
I've been doing a 30 day video challenge on YouTube and lately speaking a lot about VR topics.
VR Standards Dilemma
Messy History why PCVR is still a faff
Messy History of VR Streaming
and today on
Split rendering
And I thought it would be good to get my ideas back in blog format.
Conclusion at the top to save you time
Split rendering will likely be a part of future of VR/AR technology, but it's a bloody complicated beast that requires careful design, platform-holder pull, and developer buy-in. It's not just a VR problem either - this tech could help cloud rendering and mobile applications, with economic incentives pushing it forward despite technical challenges.
THIS IS A HIGH LEVEL ROUGH SUMMARY
The core question remains: how do we intelligently divide rendering work between a powerful PC and a mobile headset in a way that uses less bandwidth than simply streaming compressed frames?
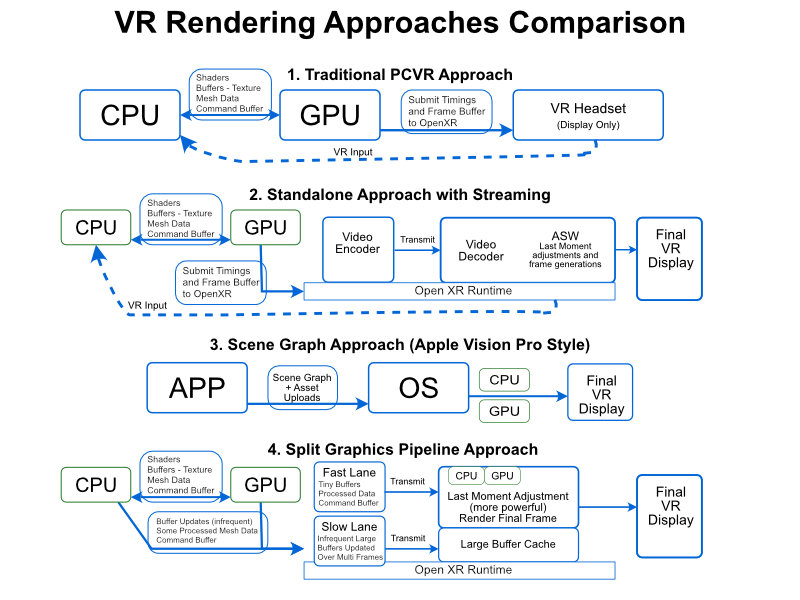
One possible version of what this could look like
The Developer Conundrum
I've been thinking about split rendering a lot lately because of these videos. The technology promises the best of both worlds: PC-level graphics with wireless freedom. But as with most things in game development, the devil's in the implementation details. Let's take a step back. When you're making a VR game, you essentially have two options: go standalone and accept mobile-level graphics constraints, or tether to a PC for gorgeous visuals but deal with that bloody cable. Split rendering attempts to solve this by dividing rendering tasks between a PC and the headset. Brilliant in theory, nightmare in practice.
What Split Rendering Actually Means
At its core, rendering is about producing 2D images - or in VR's case, a special kind of 2D image for each eye. If you've worked with Vulkan multi-view or similar APIs, you know the drill - you produce multiple frame buffers which get compressed and sent either through DisplayPort/HDMI or via streaming to a headset.
The fundamental challenge with split rendering is one of data throughput. For a split rendering system to make sense, the amount of data you're sending between the PC and headset needs to be less than what you'd use simply encoding and streaming frame buffers.
This is where things get proper complicated.
The Apple Approach: Scene Graphs and Control
Apple, who I'm not always fond of but must give credit where it's due, took a clever approach with their Vision Pro. They knew most programmers (sorry mates, but it's true) would struggle to hit VR frame rates consistently. It's a specialist field, and they needed to ensure the perception of their hardware wouldn't be marred by poorly optimized code.
So what did they do? They essentially force developers to provide a scene graph - a collection of 3D models and scene information - rather than rendered frames. Apple's system then does the actual rendering itself. There is a whole another deep dive I need to talk about another time the flat surface, bounded volume and then unbounded volume (traditional VR). The scene graph approach only applies to the first two.
This approach gives Apple tremendous control. They can:
- Merge and manipulate scene graphs for complex UX elements
- Ensure consistent frame rates by managing rendering themselves
- Splice multiple app scene graphs together in interesting ways
- Take advantage of the fact that scene graph data is typically much smaller than frame buffers
It's quite clever, actually. In most 3D applications, the scene graph doesn't change dramatically frame-to-frame. Your character moves, you shoot something, a particle effect triggers - the data throughput can be quite small when properly compressed.
The Alternative: Graphics API Splitting
The other approach involves working at the graphics API level - Vulkan, OpenGL, etc. Here's where my experience with console development colors my thinking.
Graphics cards already have established APIs we talk to them with. We send textures and model data (expensive operations we try to minimize), and issue commands to render frames. The problem is that the throughput to the graphics card - the memory IO back and forth - tends to be higher than a single frame buffer.
So if we naively split the Vulkan API between a PC and headset GPU, we'd likely end up sending more data than just streaming compressed frames. Not exactly helpful, is it?
But there are potential solutions. What if:
- The headset had a local texture/model cache for long-term assets
- You prioritize sending only what's needed for the current frame
- You use mipmapping and placeholder textures when higher-quality assets aren't loaded yet
- You leverage compute shaders for operations that can happen entirely on-device
Let's get a bit technical for a moment. If I were designing a split rendering architecture (purely as a thought exercise, mind you), I'd probably approach it through the Vulkan API. Vertex shaders would likely still run locally, as transforming vertices doesn't increase data amounts. I'd introduce a concept of "remote memory" alongside host and device memory, with anything referencing device memory running locally, and remote memory stuff running remotely.
Texture management would be critical - selective MIP transfer and compressed lighting/shadow calculations would be essential to keep bandwidth requirements manageable. Again this only works if the amount of data being sent is less than a framebuffer. With high resolution displays and having a more robust and intelligent frame generation method that split rendering could offer makes it more appealing.
The Hard Truth About Implementation
Here's the reality check: I think only a platform holder with significant pull can successfully implement split rendering. It requires developers to work in specific ways that might not align with existing pipelines.
The first devices supporting split rendering (if not from a console maker like Sony) will likely support both split and traditional rendering models to maintain backward compatibility. And it will absolutely require intensive collaboration with graphics chip providers.
Beyond VR: Broader Applications
The fascinating thing is that split rendering technology has applications well beyond VR. Mobile gaming and cloud rendering stand to benefit enormously from these techniques.
There's massive economic incentive pushing cloud rendering forward despite lukewarm reception from gamers. Big tech companies are desperate for that value-add, and split rendering could be part of the equation that finally makes cloud gaming properly viable.
While VR provides the perfect test case, I reckon we'll see these technologies appear in numerous other applications once the implementation challenges are solved.
What's Next?
Smart people I know seem to agree split rendering is a part of the future, but nobody can agree precisely where to draw the lines or on timelines. Which operations happen where? How do we manage memory efficiently? How do we handle the spikes and variability inherent in real-time rendering?
These are open questions with no clear answers yet. Every person I've spoken with draws the lines in different places, reflecting just how complex and nuanced the problem space truly is.
What do you think? Is split rendering the holy grail of VR we've been waiting for? Or will platform fragmentation and technical challenges keep it perpetually on the horizon? I honestly can't say.
Research and Further Reading
While I've been rambling about the practical challenges from a game dev perspective, there's actually some bloody exciting academic research happening in this space. If you're a bit more technically inclined, here are some fascinating topics to follow up on.
Hybrid Rendering Pipelines
Researchers are developing distributed rendering architectures where the thin client (your headset) handles lightweight tasks like basic rasterization or UI overlays, while offloading the heavy lifting—ray tracing, global illumination, volumetric effects—to a powerful server. It's a smart division of labor that could help mobile devices display high-quality graphics without needing desktop-class GPUs.
Lighting and Global Illumination Streaming
One particularly promising approach focuses on splitting global illumination computation. The server calculates dynamic light probes (or irradiance volumes) using advanced encoding, then streams just these lighting data to the client. This approach reportedly reduces bandwidth requirements by over 99% compared to traditional streaming methods. Now that's the kind of efficiency we're after!
AR Edge Offloading
There's also interesting work happening in the AR space with frameworks like PoCL-R that can distribute rendering tasks to edge servers. This approach significantly reduces energy consumption on mobile devices while improving frame rates for AR applications. As someone who's battled mobile GPU constraints, this gets me properly excited.
Volumetric Video Streaming
One of the most developed areas and very similiar to the exsisting streaming link tech, though some great research in using gaussian splats or other encoding formats other than a flat frame buffer. Volumetric streaming has lots of papers, companies and similiar work.