The Godot Rough Patch
The Godot Rough Patch
TLDR: Shipping a game with Godot is hitting all the expected rough patches around polish, tech milestones, and store compliance. The engine's great but the community's mostly hobbyist, so commercial requirements often mean rolling your own solutions. Also, please stop renaming functions in the engine - some of us are trying to ship games here.
I knew it was coming, I said as much in my Develop talk last year that the pain with Godot was always going to be felt around shipping and polish. Apoligies if I have been quiet this year. It was very much not my intention and another time I shall recount the last six months in more detail and why development has been hard. Part of it has been making a lot of mistakes and struggling to adapt to indie work patterns after years in larger studios.
After a cancelled project we decided to regroup and ship something very small. This was indeed the correct decision given the various hurdles which have come up but we are now weeks away from the Early Access launch of the title, though due to it's market fit nature I've been unable to talk about it until it is live on the store.
What is the rough patch?
Simply put getting that last bit of spit and polish on a video game project involves three areas
- Creative Polish, the feel and vibe of the project
- Hitting key technical milestones like framerate, package size ect...
- Store compliance: Console TRC, store api, legal compliance and lots of niggles
This is a pain generally not experienced by amateur or even semi professional indies often. That may seem like an inflammatory statement and in some respects they do experience the first of the three. Though ultimately the finacial pressure of paying bills and having investment compound the pressure significantly in way that is hard to understand by lightly dipping your toes in.
As for the store compliance and technical issues this is best summed up by a now infamous tweet where a indie developer complained that Steam blocked their title update because it crashed when a controller was unplugged and plugged back in. An automated check which was run on their submission no doubt and the reaction was almost perfectly split between professional gamedevs and not. On the gamer and hobbyist side their were offended at this heavy handed "censorship" and unreasonable standard. Who unplugs a controller mid game just restart the game and various other vitorial. While professional devs mostly jaded by Steam's loose quality control were mild impressed Steam was checking for this common compliance check which all consoles have had since controllers could be plugged in.
Additionally the technical milestones are often some of the hardest as a team tries to put that final gold master together, that final package for the big red button. It is a scary and often stressful times as marketing deadlines and schedule ad spends couple with a mess of proffessional calander entries bearing down on an often small programming team to find out why that character jumping really fast breaks a central check or why the build size is just over some arbitary threshold size previously committed to.
Godot is a fast progressing engine with more and more titles being worked on, though predomdiatly the community is non-professional leading to this imblance.
Unity and the PlayStation 4 Launch
This is not new, I recall this exact same issue happend when the PlayStation 4 was launching. A variety of indie developers had been lined up by Stragic Content and another initatives inside PlayStation to up the coolness of the platform off the back of work with the Vita. The old processes in some cases archaic and silly needed updating but on the other side a meaningful and important pushback for quality and core technical requirements held the line. Trying to find balance.
In this wave was a slew of Unity games. Unity was the new kid on the block with very few titles released on console, though it was in double digits by this point but on the previous generation. The issue was compounded by the fact Unity was in a massive growth phase, not disimiliar to what Godot is at the start of, but made worse by the fact it was closed source. Backroom deals and engineers rushed around but ultimatly many many indie games got screwed they missed their launch windows. Sometimes due to faults of their own, account managers but the lion shares of the blame could squarely be placed at Unity unproven engine tech.
This is why Unreal with it's closed source but build from source culture, many studios took almost a decade to upgrade to the new version from their special self cooked branches of UE3, did so much better. This is also why I feel more confident in Godot's open source approach. The issue with open source, middleware or using someone's lib is ultimately as a professional dev the buck stops with you and you have to bring all your dependcies up to the commercial standard your trying to achieve. This is the pain I am feeling with Godot at the moment.
So your just a better coder?
HOLY FUCK NO! There are much much smarter people than me and espcially in some areas. My knowledge of build systems is laughably poor to near incompetence. No we all have our blind spots. The issue is I'm building a thing. I've needed to make tech changes to achieve my goals. I will write a full post on replacing the Godot Label3d at some point. But also I needed bindings to commercial systems like leaderboards, store entitlements and commercial apis. I needed them in a way that could work across Steam, Meta Quest and PlayStation. These are not core problems to the Godot community. While some plugins exsist they tend to be single store focused and as someone who built her career on platform intergrations in some cases not up to the level I wanted.
Classic things like managing CPU affinity, respecting rate limits, pumping stuff on a thread, sleeping to avoid over stressing batteries ect... are all required elements. These stressors aren't felt by a hobby project. Even really skilled coders when they are working on something in their free time, for no pay, will often avoid the tricky problems or the ackward areas which make the project less fun. So often hobbyist libs are just missing these tricky edge cases.
Why the FUCK are you renaming shit
One big BIG difference between a mature commercial project and ameturs work is stability. Windows for all it's failing and weirdness is ROCK stable from an API point of view. Likewise Steamworks, PlayStation ect... when an API is exposed it stays still and does not move without significant pushback. This is why in Vulkan and other places you will have create_thing and create_thing2(...). So that the old one can be deprecated and people can be moved over to the new system.
While code reactoring, espcially with your fancy IDE rename tools feels quick and easy the pain is large. Recently I had to cherry pick some fixes from the main branch of Godot but I couldn't. At least not easily because some twit had renamed a bunch of function sigs! What is worse in pulling and merging the update script my build scripts all started failing because a core build command was renamed. What is worse the rename was called out in the PR as a minor ammendendment and no-one pushed back. It wasn't a junior but a senior Meta engineer and approved by key mantainers. Move fast and break my shit why don't you.
This has become a common issue with Godot mantainence. Too many people want to be involved and code janitor the code base, renaming things in a well intentioned drive to clean up and make the code base more understandable. A commendable process but it is piecemeal all over the shop, over changing function sigs or variable names for no strong reason. Making mantaining off branch variants much harder.
Any serious project will take a snapshot of all it's dependencies and keep updates to a minium to be stable. Every time an library, middleware or similiar is updated espcially on a larger team a large battery of expensive and slow tests often involving human time need to be performmed to confirm no unintended side effects. This well intentioned code janitor works makes pulling in critical patches signitificantly more time consuming and messy.
That is not to say renaming shouldn't be done but simply
- Old versions should be mantained and marked as deprecated
- Renaming due to changes in convention or similiar should be done code based wide and brought in as a single largescale change with clear approval and orcestration
- Any refactors should experience some pushback to check they are justified and not rubber stamped as "no behaviour change"
Going forward to release
Overall things are mostly looking up. I look forward to making more deep dive technical posts on the exact work undertaken and sharing more in the comming weeks. I want to keep a positive tone as I know this post can come across as a bit ranty. I'm immensely grateful to the Godot community and I hope to contribute back much of the work undertaken but as many release bits line up a large amount of work piles up.
I'm only able to write this post as I have some very long build times across multiple platforms and debug scons/cmake nightmare hell. So yes I hope to share more soon. I am still very fond of Godot but I knew this rough patch of release pain was coming and wanted to share these frustrations because I am the only dev in my various professional circles currently shipping on Godot. While I openly advocate for it, it is also important to highlight these issues. No koolaid to drink here.
If you have questions as always find me on the various socials. Bsky, Twitter and Mastodon to chat about all this or hit me up on the Godot RocketChat.
Split Rendering for VR: What does it look like
Split Rendering for VR: What does it look like
I've been doing a 30 day video challenge on YouTube and lately speaking a lot about VR topics.
VR Standards Dilemma
Messy History why PCVR is still a faff
Messy History of VR Streaming
and today on
Split rendering
And I thought it would be good to get my ideas back in blog format.
Conclusion at the top to save you time
Split rendering will likely be a part of future of VR/AR technology, but it's a bloody complicated beast that requires careful design, platform-holder pull, and developer buy-in. It's not just a VR problem either - this tech could help cloud rendering and mobile applications, with economic incentives pushing it forward despite technical challenges.
THIS IS A HIGH LEVEL ROUGH SUMMARY
The core question remains: how do we intelligently divide rendering work between a powerful PC and a mobile headset in a way that uses less bandwidth than simply streaming compressed frames?
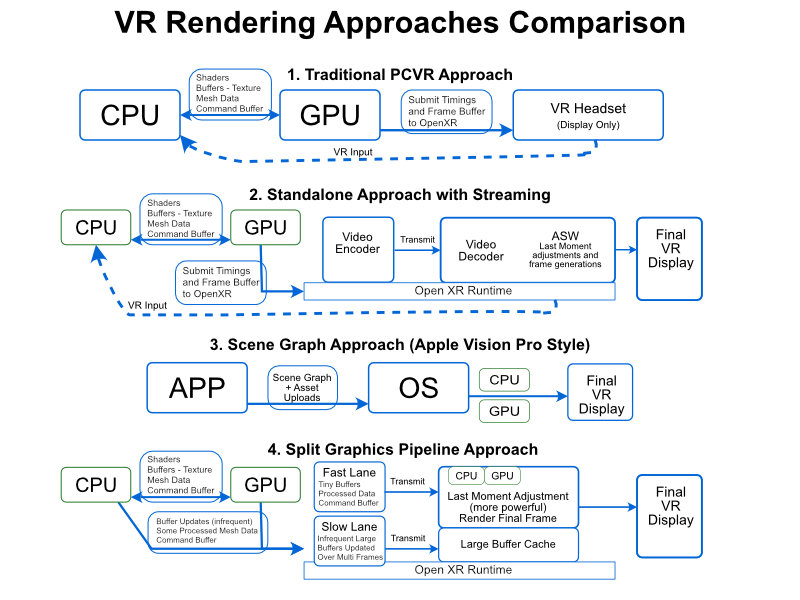
One possible version of what this could look like
The Developer Conundrum
I've been thinking about split rendering a lot lately because of these videos. The technology promises the best of both worlds: PC-level graphics with wireless freedom. But as with most things in game development, the devil's in the implementation details. Let's take a step back. When you're making a VR game, you essentially have two options: go standalone and accept mobile-level graphics constraints, or tether to a PC for gorgeous visuals but deal with that bloody cable. Split rendering attempts to solve this by dividing rendering tasks between a PC and the headset. Brilliant in theory, nightmare in practice.
What Split Rendering Actually Means
At its core, rendering is about producing 2D images - or in VR's case, a special kind of 2D image for each eye. If you've worked with Vulkan multi-view or similar APIs, you know the drill - you produce multiple frame buffers which get compressed and sent either through DisplayPort/HDMI or via streaming to a headset.
The fundamental challenge with split rendering is one of data throughput. For a split rendering system to make sense, the amount of data you're sending between the PC and headset needs to be less than what you'd use simply encoding and streaming frame buffers.
This is where things get proper complicated.
The Apple Approach: Scene Graphs and Control
Apple, who I'm not always fond of but must give credit where it's due, took a clever approach with their Vision Pro. They knew most programmers (sorry mates, but it's true) would struggle to hit VR frame rates consistently. It's a specialist field, and they needed to ensure the perception of their hardware wouldn't be marred by poorly optimized code.
So what did they do? They essentially force developers to provide a scene graph - a collection of 3D models and scene information - rather than rendered frames. Apple's system then does the actual rendering itself. There is a whole another deep dive I need to talk about another time the flat surface, bounded volume and then unbounded volume (traditional VR). The scene graph approach only applies to the first two.
This approach gives Apple tremendous control. They can:
- Merge and manipulate scene graphs for complex UX elements
- Ensure consistent frame rates by managing rendering themselves
- Splice multiple app scene graphs together in interesting ways
- Take advantage of the fact that scene graph data is typically much smaller than frame buffers
It's quite clever, actually. In most 3D applications, the scene graph doesn't change dramatically frame-to-frame. Your character moves, you shoot something, a particle effect triggers - the data throughput can be quite small when properly compressed.
The Alternative: Graphics API Splitting
The other approach involves working at the graphics API level - Vulkan, OpenGL, etc. Here's where my experience with console development colors my thinking.
Graphics cards already have established APIs we talk to them with. We send textures and model data (expensive operations we try to minimize), and issue commands to render frames. The problem is that the throughput to the graphics card - the memory IO back and forth - tends to be higher than a single frame buffer.
So if we naively split the Vulkan API between a PC and headset GPU, we'd likely end up sending more data than just streaming compressed frames. Not exactly helpful, is it?
But there are potential solutions. What if:
- The headset had a local texture/model cache for long-term assets
- You prioritize sending only what's needed for the current frame
- You use mipmapping and placeholder textures when higher-quality assets aren't loaded yet
- You leverage compute shaders for operations that can happen entirely on-device
Let's get a bit technical for a moment. If I were designing a split rendering architecture (purely as a thought exercise, mind you), I'd probably approach it through the Vulkan API. Vertex shaders would likely still run locally, as transforming vertices doesn't increase data amounts. I'd introduce a concept of "remote memory" alongside host and device memory, with anything referencing device memory running locally, and remote memory stuff running remotely.
Texture management would be critical - selective MIP transfer and compressed lighting/shadow calculations would be essential to keep bandwidth requirements manageable. Again this only works if the amount of data being sent is less than a framebuffer. With high resolution displays and having a more robust and intelligent frame generation method that split rendering could offer makes it more appealing.
The Hard Truth About Implementation
Here's the reality check: I think only a platform holder with significant pull can successfully implement split rendering. It requires developers to work in specific ways that might not align with existing pipelines.
The first devices supporting split rendering (if not from a console maker like Sony) will likely support both split and traditional rendering models to maintain backward compatibility. And it will absolutely require intensive collaboration with graphics chip providers.
Beyond VR: Broader Applications
The fascinating thing is that split rendering technology has applications well beyond VR. Mobile gaming and cloud rendering stand to benefit enormously from these techniques.
There's massive economic incentive pushing cloud rendering forward despite lukewarm reception from gamers. Big tech companies are desperate for that value-add, and split rendering could be part of the equation that finally makes cloud gaming properly viable.
While VR provides the perfect test case, I reckon we'll see these technologies appear in numerous other applications once the implementation challenges are solved.
What's Next?
Smart people I know seem to agree split rendering is a part of the future, but nobody can agree precisely where to draw the lines or on timelines. Which operations happen where? How do we manage memory efficiently? How do we handle the spikes and variability inherent in real-time rendering?
These are open questions with no clear answers yet. Every person I've spoken with draws the lines in different places, reflecting just how complex and nuanced the problem space truly is.
What do you think? Is split rendering the holy grail of VR we've been waiting for? Or will platform fragmentation and technical challenges keep it perpetually on the horizon? I honestly can't say.
Research and Further Reading
While I've been rambling about the practical challenges from a game dev perspective, there's actually some bloody exciting academic research happening in this space. If you're a bit more technically inclined, here are some fascinating topics to follow up on.
Hybrid Rendering Pipelines
Researchers are developing distributed rendering architectures where the thin client (your headset) handles lightweight tasks like basic rasterization or UI overlays, while offloading the heavy lifting—ray tracing, global illumination, volumetric effects—to a powerful server. It's a smart division of labor that could help mobile devices display high-quality graphics without needing desktop-class GPUs.
Lighting and Global Illumination Streaming
One particularly promising approach focuses on splitting global illumination computation. The server calculates dynamic light probes (or irradiance volumes) using advanced encoding, then streams just these lighting data to the client. This approach reportedly reduces bandwidth requirements by over 99% compared to traditional streaming methods. Now that's the kind of efficiency we're after!
AR Edge Offloading
There's also interesting work happening in the AR space with frameworks like PoCL-R that can distribute rendering tasks to edge servers. This approach significantly reduces energy consumption on mobile devices while improving frame rates for AR applications. As someone who's battled mobile GPU constraints, this gets me properly excited.
Volumetric Video Streaming
One of the most developed areas and very similiar to the exsisting streaming link tech, though some great research in using gaussian splats or other encoding formats other than a flat frame buffer. Volumetric streaming has lots of papers, companies and similiar work.
Building for Watchy
Building for Watchy
A short article on a little hobby code project resulting in two watch faces.
As long term fan of the best wearable, The Pebble Watch, my wife and I have a real soft spot for the long battery life epaper watch focused on time keeping and bits of useful functionality. The wearable market is dominated by wellness, fitness and subscription based services. The lack of a true pebble successor is a sad spot. Though in the run up to Christmass we became aware of the Watchy project by SQFMI. https://watchy.sqfmi.com/

This open source project based on ESP-32 was on its third revision and had a strong basis of functionality that ticked all our boxes:
- E-ink screen
- Long battery Life
- Programmable (preferably with C)
- Physical Buttons
- Wifi and Bluetooth
Building our Watches
The watches arrived in these lovely packages.

The assembly was relatively simple but quite fiddly with the ribbon cable and the button insets in the case being very fiddly to get in place. Though it is easy enough to do and my wife needed minimal assistance to build her own. I would encourage anyone to try it.

So after an hour on building we ended up with a very nice functional watch.

Open up the Code
But of course the real appeal was the open source and easy to modify watch code. The watch is based on ESP32 and before this I have not touched any ESP32 devices. I have done some embedded programming back in the day but not in a while. However the official firmware, https://github.com/sqfmi/Watchy/, had some real issues including a tendency to overflash the ink screen, cycling the entire screen in an unpleasant way.
The firmware is relatively easy to dig into with the Arduino IDE but the holding buttons to put stuff into Bootloader mode, installing USB drivers and then fighting with various serial comms issues was a real blocker to start. That was until I found some decent ESP32 command line tools. Though it was at this point in doing some investigation I found that the official firmware isn't as well maintained as one would like and you now have two main projects which have their own firmware to explore.
Ink Watchy
The first one I played with was Ink Watchy, https://github.com/Szybet/InkWatchy/
It looks very feature rich and has some great stuff in it. Though looking at the build instructions the disdain for anyone not on linux was painful. That coupled with an insistence on Docker and a cryptocoin positive outlook set off all kinds of red flags.
The toolkit and build system used was PlatformIO. The KEY feature of this being Use whenever, Run everywhere. The SCONS based system, the same used by Godot, is python first and very cross platform. Rather than doing the simple stuff in python scripts in platform agnostic ways it builds using a bunch of bash scripts and the build tooling for InkWatchy is a pain in the neck. I dug through it for a while converting logic to Python and fixing platform specific issues but honestly after most of a wasted day I was fuck it this sucks.
Though thankfully this did teach me PlatformIO which is a great toolset for this problem space. This led me to the alternative firmware.
WatchyGSR
The WatchyGSR project is a bit less along but much more stable. https://github.com/GuruSR/Watchy_GSR/
It didn't have a bitcoin feature set up front, it has a decent configurable demo binary. This combined with the platformIO cli tools made building a lot easier. The addon / watch face override system is simple to grasp and easy to deploy. The best part is an OTA (over the air) update system which lets you configure the watch from your browser and even drop most, not all, updates as a firmware update through the browser.
Building and Deploying a new Watchface

The first step was looking at the code base and seeing there was included, but not enabled by default, examples of porting the additional watch faces from the official repo in the code base. This meant I was able to get the Starry Horizon watch face on and that immediately made both me and my wife happy as the Cyberpunk+Space watchface looked very cool.
Now to get my hands dirty what was the simplest thing I could do to take the watchface from the basic to a new cool addition. So first off I copied the watchface class, as the system is based on overriding the WatchyGSR class. The key virtual functions being InsertDrawWatchStyle and handleButtonPress.
There was an excessive use of write commits in the code which I cleaned up to better batch draw calls. I played with how the sky and grid was drawn. Optimising a few of the draw calls to better batch. Also things like the ground never changes with time, while the stars do rotate on the minute. So I did some optimisation.
Feeling better I needed a goal: Let's put the ISS into orbit.
Drawing BITmaps
Images on embedded devices, even fonts, tend to be PROGMEM code embedded systems. You convert images to C style arrays and bit pack down and then draw using bit shift logic. Though again looking at the main utility function it seemed a bit wasteful so I made my own one bit bitmap drawing function.
void drawBitmap1Bit(int16_t sx, int16_t sy, const uint8_t bitmap[], int16_t w, int16_t h, uint16_t color)
{
int16_t offset = 0;
uint8_t b = bitmap[offset];
uint8_t bw = 0;
display.startWrite();
for (int16_t y = sy; y < (sy+h); y++) {
for (int16_t x = sx; x < (sx+w); x++) {
if(b & 0x80) {
display.writePixel(x, y, color);
}
b <<= 1;
bw++;
if(bw == 8) {
offset++;
bw = 0;
b = bitmap[offset];
}
}
}
display.endWrite();
}
You will notice that it will ONLY write when the bit is enabled and will either write white or black. This is batched in a single write operation. The important thing to note is that this is a Big Endian solution so that is simple to encode. I needed a method to convert images to code and for that I was using https://notisrac.github.io/FileToCArray/
Now after grabbing MsPaint and a basic silhouette of the ISS I did some by hand pixelling to make an ISS. I then had a bunch of encoding issues as the website I linked above did a pretty poor job of per line encoding with fixed endian (despite the toggle). Though I was able to get it to do what I want and BOOM I had an orbiting ISS. My wife was super happy.

Fresh Watch Face
So while this was going on we had shoved on a monster movie marathon from the classic MST3K. The brilliance of this old show being a staple in the house, I decided that I should make a MST3K watch face as my first from scratch watch face.
So copying over the watch face I had been editing I stripped it down and got the date and time printing. Though the image pipeline was a real PITA. So I decided to switch to a proper tool. So I loaded up Aesprite, which I had not used in a long time. It is a great piece of pixelling software but has no export to C array function I could find.
So while I could make great art in this software I needed to make a better export option. So looking at the LUA scripting interface I found this GameBoy export script. https://github.com/boombuler/aseprite-gbexport
Using that as a basis I started writing an export to make a simple text file which outputted space for transparent, then 1, 2 for black or white pixels. This 2bit image format lets me make transparent images which can contain both white and black. It took me a while to find the script debugger which was a blind spot in my part. Also the alert dialog doesn't support new line characters so I had to do some error stacktrace printing. Though it was relatively painless to get it exporting the selected area. Getting images like this:
#define TOM_HEIGHT 41
#define TOM_WIDTH 29
// array size is 298
static const byte TOM[] PROGMEM = {
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0A, 0xAA, 0xA8, 0x00, 0x00, 0x00, 0x00,
0x02, 0xAA, 0xAA, 0x00, 0x00, 0x00, 0x00, 0x00, 0xAA, 0xAA, 0x80, 0x00, 0x00, 0x00, 0x00, 0x22,
0x22, 0x20, 0x00, 0x00, 0x00, 0x00, 0x22, 0x22, 0x22, 0x00, 0x00, 0x00, 0x00, 0x22, 0x22, 0x22,
0x20, 0x00, 0x00, 0x00, 0x0A, 0x22, 0x22, 0x28, 0x00, 0x00, 0x00, 0x02, 0x22, 0x22, 0x22, 0x00,
0x00, 0x00, 0x00, 0xA2, 0x22, 0x22, 0x80, 0x00, 0x00, 0x00, 0x22, 0x22, 0x22, 0x20, 0x00, 0x00,
0x00, 0x02, 0x22, 0x22, 0x20, 0x00, 0x00, 0x00, 0x00, 0x22, 0x22, 0x20, 0x00, 0x00, 0x00, 0x00,
0x02, 0x22, 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0xAA, 0xA8, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0A,
0xA8, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0xAA, 0xA0, 0x00, 0x00, 0x00, 0x00, 0x00, 0xAA, 0xA0,
0x00, 0x00, 0x00, 0x00, 0x00, 0x2A, 0xA0, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0A, 0xA8, 0x00, 0x00,
0x00, 0x00, 0x00, 0x02, 0xAA, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xAA, 0xA0, 0x00, 0x00, 0x00,
0x00, 0x00, 0xAA, 0xAA, 0x80, 0x00, 0x00, 0x00, 0x02, 0xAA, 0xAA, 0xA8, 0x00, 0x00, 0x00, 0x02,
0xAA, 0xAA, 0xAA, 0x80, 0x00, 0x00, 0x02, 0xAA, 0xAA, 0xAA, 0xA0, 0x00, 0x00, 0x00, 0x2A, 0xAA,
0xAA, 0xAA, 0x00, 0x00, 0x00, 0x0A, 0xAA, 0xAA, 0xAA, 0xAA, 0x80, 0x00, 0x02, 0xAA, 0xAA, 0xAA,
0xAA, 0xA8, 0x00, 0x02, 0xAA, 0xAA, 0xAA, 0xAA, 0xAA, 0x00, 0x00, 0xAA, 0xAA, 0xAA, 0xAA, 0xAA,
0x80, 0x00, 0x2A, 0xAA, 0xAA, 0xAA, 0xAA, 0xA0, 0x00, 0x2A, 0xAA, 0xAA, 0xAA, 0xAA, 0xA0, 0x00,
0x0A, 0xAA, 0xAA, 0xAA, 0xAA, 0xA0, 0x00, 0x0A, 0xAA, 0xAA, 0xAA, 0xAA, 0xA0, 0x00, 0x02, 0xA2,
0xAA, 0xAA, 0xAA, 0xA8, 0x00, 0x00, 0xA8, 0xAA, 0xAA, 0xAA, 0xAA, 0x00, 0x00, 0xA8, 0x0A, 0xAA,
0xAA, 0xAA, 0x80, 0x00, 0xA2, 0x02, 0xAA, 0xAA, 0xAA, 0xA0, 0x00, 0x2A, 0x80, 0xAA, 0xAA, 0xAA,
0xA8, 0x00, 0x0A, 0x00, 0x2A, 0xAA, 0xAA, 0xAA, 0x00, 0x00
};
Drawn by a simple 2bit drawing function:
void drawBitmap2Bit(int16_t sx, int16_t sy, const uint8_t bitmap[], int16_t w, int16_t h)
{
int16_t offset = 0;
uint8_t b = bitmap[offset];
uint8_t bw = 0;
display.startWrite();
for (int16_t y = sy; y < (sy+h); y++) {
for (int16_t x = sx; x < (sx+w); x++) {
if(b & 0x80) {
if (b & 0x40) {
display.writePixel(x, y, GxEPD_BLACK);
} else {
display.writePixel(x, y, GxEPD_WHITE);
}
}
b <<= 2;
bw += 2;
if(bw == 8) {
offset++;
bw = 0;
b = bitmap[offset];
}
}
}
display.endWrite();
}
Animating the Characters
Next the characters needed a bit of interesting animation to provide some life to the watch face. Simply moving the characters up and down on a sine wave with some random control seemed like an easy option with alternate frames. For this reason the characters were drawn then the chairs.
Now I needed a simple predictable random function. I would normally reach for a Messene Twister function here. Though I then noticed because of the wifi functionality the board had a decent random function esp_random(). So that was easily handled. The characters now had some animation.
Lots of Blank Space
I thought what to show on the cinema screen. I would love to have a little set of mini movies to play but for now the simplest I could think of was showing some random quotes from the show. Though this meant I needed to do a few things:
- Create a new tiny font
- Write a word wrap text drawing function
- Create a bunch of quotes
Using AI and IMDB made it easy to yank almost 100 quotes from the show. The tiny font was initially an easy 5x7 font I found. Though it was too tiny to read. So as a compromise I found this website, https://rop.nl/truetype2gfx/, to convert tty font to gfx font. I made a simple 9pt font which seemed like a reasonable trade off.
The wrapping function used the measure text bounds and a lazy split method to split into lines. The function calculates how many lines it needs based on total text width versus maximum width, then for each line it takes a portion of the remaining text (based on remaining length divided by remaining lines) and tries to find a nearby space to create a natural word break rather than cutting words in half. It looks forward by up to 5 characters for a space as a better breaking point which means sometimes words are split but not often.
This gives us the final version of the watch face.

Thus concludes my yuletide coding adventure with this lovely piece of kit. As time allows I will do more hacking on the devices and will share any interesting bits I find. The ESP32 is a nifty platform to code for and the functionality of the watch with bluetooth and wifi is an interesting subset I want to do more with.
Hope this was fun and informative.
The Craft of Game Development in Cheap Game World
The Craft of Game Development in Cheap Game World
Industry Context
Recently, I attended GodotCon and gave a talk at Develop North. GodotCon was eye-opening, and at Develop North, I discussed using Godot professionally. I shouldn't post the talk here, as it's better suited for a conference environment, but much of the information is already on my website in articles.
I want to address a phenomenon being discussed in many circles: how does a professional with two decades of experience differentiate themselves from a university or even teenage student using Unreal 5? Many initial indicators we used to rely on are no longer true. The accessibility and power of middleware, AI code tools, and future AI generation tools make it harder to spot the talent or effort behind a project at first glance.
Of course, a seasoned veteran can examine code, art, or anything they're familiar with and determine the quality. However, most consumers can't, and even seasoned veterans struggle to evaluate a vertical slice from a student team versus an experienced team working fast.
The Technical Challenge: Serialization
This leads to a problem I faced with saving and loading in our current game. Serialization is an interesting topic, often involving level replays, networking, and various state serialization issues. However, if you're using Godot, Unity, or Unreal, it's almost trivial to serialize a section of the scene graph or complex objects to JSON, save it, and load it back.
Many developers do this—probably more than I'd like to admit. I expressed my frustration about this in the cafeteria at Tentacle Zone, and a mobile app developer told me, "Of course, that's what you do, just do that and move on."
I responded that I cared about loading times, and that I wanted to use platform leaderboard binary attachment systems which are very limited in size to allow for replays. Also I wanted to support infinite undo. I had reasons. His response, “very expensive…”. Before I dive deeper into that “why” argument let's talk technical for a moment.
Optimization Techniques
I'd been working on compressing and optimizing entropy. To clarify what this means: entropy optimization involves reducing redundancy in data. Think of it like this: if you have a game board where most squares are empty, storing "empty, empty, empty, piece, empty, empty" is inefficient. Instead, you could store "3 empty squares, then 1 piece, then 2 empty". This is run-length encoding, a simple but effective compression technique. Alternatively you might just store the position of the not empty squares.
Blind naive use of binary storage isn't necessarily good. Domain-specific knowledge matters. For example, moves in memory need undo/redo actions pre-cached for responsiveness, but you don't need to save those to a file. Moves can be compressed by inferring possible moves and storing a selection index. Batch operations and run-length encoding can further reduce size.
We often store values in 16 or 32-bit integers for convenience, but saved state values might have a limited discrete range, allowing for bit-packing. Some data might be temporary and not need serialization. This results in a tight, fragile data format that takes longer to write.
People might look at a JSON save file and dismiss its size, but network transfer and storage restrictions (like for leaderboard replays) make compression important. It enables new features and keeps the game snappy with fast loading and saving. Performance is a feature!
The fragility of this format can lead to lost development time. I opted for MessagePack, a compromise between flexibility and compactness. MessagePack is essentially a binary version of JSON – it maintains JSON's flexibility but with significantly smaller file sizes. For example, where JSON might store "player_position: 42" as text (taking 19 bytes), MessagePack could store it in just 5 bytes. It's like JSON's more efficient cousin, offering about 50% size reduction without sacrificing readability in development.
Of course we tend to zip JSON and MP can be zipped up as well. Also you should still use domain specific and binary methods to compress but this wrapper lets us store things at high level with version and meta data in order insensitive manner.
Easy-to-use libraries exist for it; I wrote one for Godot and might share it in a future blog post. In our case, this brought file sizes down by 60% while keeping load times under 100ms – a sweet spot between pure JSON and fully custom binary formats.
Broader Implications for the Industry
Sharing this middleware sacrifices some of my specialist advantage. Though I’m building on the strengths of others and frankly the quality of game design, art and animation are significantly higher in juniors than when I entered into the industry because of these tools improvements. Though paradoxically the programming skills are significantly worse, it seems to matter less by the day.
However, the domain-specific knowledge and problem breakdown showcased here are part of craftsmanship and lead to a better product. Would a user notice this within the first two hours on Steam? Maybe not, but I believe attention to detail contributes to long-term quality and reputation.
In the age of big data, achieving widespread recognition is difficult. However, you can develop a reputation within your niche (turn based strategic games, werewolf romance, solitaire card games, etc.). If that means a portion of your established user base will try any title you release, that's valuable. But they often attach to a studio or brand, not an individual artisan.
Conclusion: The Value of Craft
So back to the why question. Does it matter? Will decades of honing our craft remain valuable in the future? I believe so, and here's why: while one-line JSON serialization might work for many cases, understanding WHEN AND HOW to optimize – and more importantly, when not to – comes from experience. This knowledge lets us build games that not only work but excel in ways that matter to our specific audience. It's not about using complex solutions for their own sake, but about knowing exactly when they'll make a meaningful difference.
The trade-off between development time and optimization isn't just about today's release – it's about building a foundation for future features and maintaining the kind of performance that keeps players coming back. That's the real value of experience in an age of accessible tools.
Though maybe this is wishful thinking from a middle-aged lady who know's there is no damn good reason for your indie game to have a loading screen, but it still does. Maybe well crafted isn't the hallmark of quality and success in the future.
I’m still left with questions and I have some larger ideas on the state of industry I want to write about in the near future, but that is for another time.
Godot Modular Design
Godot Modular Design
There are many reasons I think that Godot is a great technical base and has a robust future, but chiefly among them is the modular way in which things are built and designed with the assumption that parts will be ripped out, replaced and improved. This is done through an easy to approach code base, modules system and robust support for addons and extensions through GDExtension (using godot-cpp) while encouraging most people to work at the scripting level.
Also importantly, you can work in this modular design without leaving scripting, using GDScript or C# through Addons.
Good reasons to move into C++ land:
* Performance
* Complex Systems with Unit Testing
* Existing Code
Then when moving into C++ you have several routes:
* GDExtension - Dynamic library style extensions that can work across multiple engine versions
* Modules - Engine modules compiled directly into specific engine versions
* Custom Engine Builds - Full engine modifications
For scripting-level extensions:
* Add-ons - Script-based extensions that integrate with the editor
* Custom Scripts - Project-specific scripting solutions
* @Tool Scripts - Single file editor extensions
Here is a graph to help visualize the various options:

Use Case: Commercial Extension
https://docs.godotengine.org/en/stable/tutorials/scripting/gdextension/what_is_gdextension.html
You have some kind of tool or service you want to bring into the Godot community but you have commercial IP which you want to protect and manage? Then GDExtension is likely the best approach as it allows you to provide a closed source binary which users can easily drop into their project with no C++ work to use your service or tech.
This approach can work across multiple versions through proper version handling in your GDExtension implementation.
It is also a great way to reduce the recompilation of the engine and keep code stable. Complex systems can be built in their own project and you can also use languages other than C++ as all you need to produce is a dll to link against. There is also a very minor performance overhead.
| Pros | Cons |
|---|---|
| Closed source distribution possible | Additional build complexity |
| Cross-version compatibility | Performance overhead |
| No engine recompilation needed | Limited access to engine internals |
| Language flexibility beyond C++ | Must maintain versioning carefully |
| Hot-reloading support | More complex debugging |
| Easier distribution to users | Initial setup learning curve |
| Independent development cycle | Platform-specific considerations |
| Protects IP effectively | Must handle ABI compatibility |
Use Case: Gameplay Workflow Add-on
https://docs.godotengine.org/en/stable/tutorials/plugins/editor/making_plugins.html
You are a developer who is working on an RPG game with a variety of enemies. It turns out you need to customise a lot of enemies in the world. You decide to develop some @tool scripts to make some helper functions to provide a friendlier editing workflow for your enemies. Some custom gizmos, some editor-time logic to double check stats and reduce the busy work.
You make a 3D gizmo plugin and add some additional helpers to quickly setup enemy behaviours and visually see data in the viewport for enemies while setting up scenes.
You want to use this code across more than one game because you know your studio is working on another RPG title in the near future. Or maybe you're just a nice person who wants to share their tool with the community.
The huge benefit of this approach is it requires no C++ knowledge. Your logic which is likely already in GDScript is easy to isolate and move into an add-on. The challenges with this approach are that it's still a scripting solution which means you will have less performance, less robust debugging tools and writing unit tests requires additional setup. While there are unit testing tools available like GUT (Godot Unit Test), they are not yet in the core engine. See https://github.com/bitwes/Gut
| Pros | Cons |
|---|---|
| No C++ knowledge required | Limited performance compared to C++ |
| Quick to develop | Less robust debugging tools |
| Easy to modify and iterate | Unit testing requires external tools |
| Simple to share and distribute | Can't access low-level engine features |
| Works directly with GDScript code | May have scaling limitations |
| Hot-reload support | No built-in testing framework |
| Native editor integration | Script security limitations |
| Cross-project compatibility | Resource-intensive for complex tools |
Use Case: Game Specific Engine Modules
You have some game specific code which ties tightly into the engine. While you could make a GDExtension, the reality is this code is project specific - maybe some of it will be shared with other projects in your studio but it's fairly bespoke. It is in active development and you're not sure which parts of the engine you need to access but performance is critical. You want to avoid the abstraction of the godot-cpp extension API. In these cases, modules are often the best approach.
Modules allow you to build internal C++ changes to the Godot engine in a fashion which is isolated from the main engine code, reducing merge conflicts during engine upgrades. Sometimes an engine upgrade will break a function call because of a signature change. Modules are part of the engine so the functions you call make no promises of API stability, though in most cases this is not much of an issue.
Additionally, modules can be turned on and off easily during compilation, and adding bindings to the scripting layer is handled through a bind function and some simple macros which are fast and easy to implement. Working in this way allows us to write robust unit tests and leverage mature C++ tooling.
The major downside is you need to recompile the engine, cannot use official binaries, and any changes require rebuilding the engine. Additionally, you need to generate custom export templates. Though this is no different from working with any other C++ engine.
| Pros | Cons |
|---|---|
| Direct engine access | Requires engine recompilation |
| Best possible performance | Cannot use official binaries |
| Full C++ debugging support | Need to maintain custom export templates |
| Mature unit testing tools | Longer iteration times due to compilation |
| Easy integration with engine systems | Can break with engine updates |
| Simple binding to scripting layer | Higher technical barrier to entry |
| Module-specific version control | More complex distribution |
| Can modify core engine behaviour | Team needs C++ expertise |
Use Case: Engine Glowup
Godot is an open source engine. You will find bugs, and you will want to fix them. After fixing the bug you are hopefully submitting a pull request back to the engine to help others. Though we all know how much time that PR will take to process and likely enter into discussions. Also your solution might not be preferred by others or they might not agree there is a problem. So maintaining your own engine fork for a commercial game is almost inevitable in some ways.
Likewise you will likely need to optimise the engine for your specific use cases or maybe you need to add support for consoles or systems which are not compatible with an MIT licence. Features that could never be in the core open source MIT lib. In these cases you can modify the engine. I would encourage you to examine the code structure and try to avoid merge conflicts down the line.
Some modifications I have made on my branch:
* Fixed some bugs (submitted PR when relevant)
* Changed XR input to present old value in signal (API change so PR turned down)
* Changed some Vulkan memory management and buffer code
* Added some rendering functionality specific to my title
* Changed some editor quality of life to my preferred workflow
| Pros | Cons |
|---|---|
| Complete control over engine code | Requires maintaining a custom fork |
| Can implement proprietary features | Most complex to maintain |
| Maximum performance optimization possible | Harder to update to new engine versions |
| Direct fix for engine bugs | Need strong C++ and engine expertise |
| Custom platform support | Longest compilation times |
| Unlimited access to internals | Most expensive in development time |
| Can make deep architectural changes | Team needs deep engine understanding |
| Full debugging and profiling capability | Requires careful merge management |
Roundup
I hope this has provided a round trip into the various ways that Godot can be edited, taken apart and improved.
I wrote this article on the bus and then while sitting in some conference talks. Apologies for any oversights.
Wider Games Industry
Wider Games Industry
Disclaimer: This is a bad news bear piece. If you're feeling rough, have a coffee and skip this one.
I have spent almost 20 professional years in what I would call the premium gaming market but now almost weekly I hear of layoffs and survive till ‘25 so what does our future look like?
Last week I was at GodotCon in Germany which was a great time but a moment to reflect on the shape and scale of the industry. I will likely write about it at some point but I think often we don’t look outside our little bubbles. This was doubled for me by a conversation with an indie developer explaining the shape of the Russian gamedev scene being very different because for a long time you could earn more as a gamedev in Russia than a typically Russian tech worker. Which is the hilarious opposite of most countries.
This was made doubly obvious by GodotCon which is fundamentally an amateur or hobbyist convention. As I saw the sideline companies of Game Services and Browser games, I know that a lot of smaller indie style industries enjoy a lot of investment and use from the gambling or iGaming market. That is to say nothing of how different the XR market or app development is from the general humdrum.
Conclusion up front to save you time
- Premium market will contract to fewer long lived titles
- Indie will experience VC investment resulting in higher failure rate by percentage
- Services market will grow with more lower quality work
- Fast Development market will merge due to more standardised tech, but accelerate due to Generative AI
- Passion development will bring YouTubefication of Games which will reduce traditional market size
The Premium Market
This AAA and indie market is really one market. Yes we have shiny billboard titles competing for the same headspace as the Oscars but the auteur low budget and arthouse gaming sections of the market are really a complementary element to the premium price market.
Typically the same people work in both, our awards shows are similar if not the same and by and large we have claimed the crown and the public perception of Game Developers. If a casual person across the world were to think of gaming our products and lifestyle is typically what is pictured. Be it the indie bohemian artwork or the commercial behemoths.
Professional indies know how to access funding, attend events and typically have talent with some studio experience or are published and nourished by a publisher who is able to close the gap for them. So this pro independent development is called indie but shares only a surface layer resemblance with the passion project from an outsider.
As a South African who always wanted to make games I can also say that this version of the industry barely exists outside the big countries of UK, America and Japan. Yes digital markets and indie explosion have seen its growth in other countries relatively explode but the infrastructure, talent and investment are largely located and culturally based in those regions.
Likewise once you're in the industry you have been in historically, shake the right hand and ship a title or two for the right company and you are now “in the industry”. As our industry experiences arguably its biggest contraction in decades combined with international growth, I do think the walls are getting higher and the island smaller.
Future of Premium
As back catalogues of content are made into more long term investment with returns being spread over years. The importance of IP and breaking through the noise resulting in higher risk mixed small investment portfolios or giant AAA budgets to guarantee breakthroughs. I think it is a completely uncontroversial statement to say fewer people will be directly employed in the premium market in the coming years.
The Services Market
Familiar to anyone in the Hollywood or tech model this is a combination of money first and desperate to escape talent. Traditionally attached but not always to the premium market this is also historically the easiest way for the countries not in the chosen geographies to break into the premium market. Whether it is technical or artistic outsourcing or specialist service it fundamentally exists to save money.
While there is a large amount of the workforce in these companies desperate to break into the premium market the bosses and company runners are often, not always, happy to be in the service biz instead of the creative. The high risk, high return model of the premium world is not there, neither are the awards but typically their companies are more stable.
While we talk about crunch I have seen more exploitation in this workforce than any other. Either because their country or locale has more lax laws, the ‘hungry to break in’ mindset makes people more exploitable or clients dehumanising the service company results in massively unrealistic turnarounds applied to people without mercy.
Also platform holders, large publishing companies and other premium gaming entities have effective small service companies embedded within the company. Though these are typically better to work for.
Future of Services
This area is likely to see the largest growth in terms of market value but I do think the pay and quality of the jobs in this area will do a classic k shaped split with certain high skill individuals getting larger paydays more in line with tech salaries while the bulk will see salary reduction. We will also see more consolidation of these companies and a few big names will emerge to the scale of large tech giants.
Mobile and Gambling Market
While some sections of the mobile market are associated with the premium market the bulk of the market is data focused with hyper fast turnarounds. While studios do not go boom or bust as much, the games are fast and furious with soft launches in small markets and further development almost entirely driven by adoption and data trends.
If you're interested in smaller game engines or unique tech stacks this world is full with them. The margins of this world are razor thin so anything that enables fast development is welcome. The explosion of middleware has meant companies will adopt any solution for rapid iteration. Also there is little brand recognition or defendable moat so these companies often have very high turnover.
This market segment also does branded work for iGaming or Gambling markets with a low bid contract model. Some of the best indie game developers have come from this market. Minecraft, Vampire Survivors and many other titles have come from people who came from this high production rate environment.
Browser and Installation Gaming
Similar to the mobile and gambling sector this market tends to be extremely high turnover with a lot of reskins of mobile and iGaming products. Though with the middleware market getting more mature and the introduction of WebGPU the gap is narrowing between the two markets. Though it has an even higher turnover in the near future with the tools gap narrowing.
The monetisation models are the primary market difference from the mobile and iGaming segment but again we are seeing a market reduction in these companies as sectors merge.
So I consider these now both the same sector of Fast Development.
Future of Fast Development
All signs point to this market adapting to new tools and cost saving measures. This is the market in which I think we will see rapid adoption of GenAI tooling due to the cutthroat and competitive nature of the games. With consumers less likely to make motivated purchase decisions which incentivises human art or ethical business practices.
In the near future the asset flip will be swapped out for the generative model. Still with humans in the loop but the already fast cycle will accelerate to new highs making this market fully commoditized. I don’t see this market being nearly as sustainable leading to more job loss in developed countries with a bigger lean on subsidised products.
Passion and Hobbyist Development
By far the fastest growing sector and one largely ignored by professionals are the passion and hobby developers. They come from all sections of life with some dreaming of being more involved in various market segments, typically premium gaming, they usually have no industry connections or finance plan. The games are developed as side projects, part of game jams or even as a lark. Some UGC platforms like Roblox, Fortnite creative, Dreams and others try to provide ready to build playgrounds for these creators.
Light monetisation exists for this market but it is often as much secondary income like Twitch, YouTube or associated influencer work. This market is exploding with the accessibility of tools and the self publishing boom. Though the reality is the vast majority, well over 95% of these creators will never recoup their money spent let alone their time an occasional breakout success will enter the professional Indie market it is not helpful to place them in the same statistical bucket as professional independent developers. This is no value judgement on the market and some of the highest quality product and artistic expression comes from these solo and tiny teams but it is fundamentally outsider art with a very low success rate as a product.
Though it needs to be stated that most of the time these people are not in it for the money or even the acclaim. With many meme games, weekend projects and flights of fancy creating thousands of unique experiences. This leads to the bulk of titles published on Steam not recouping their $100 cover charge, though only a small percentage of these games are ever pushed to marketplaces.
Future of Passion Projects
With the explosion of easy to use tools, higher game literacy and companies able to monetise the market we have seen an exponential explosion of creative expression at a small scale. This can only encroach on the attention spent on more professional products as the YouTubification of video games continues.
Players like Roblox, Meta Horizon, and others will exploit the market with poor monetisation rates while AI tools and more powerful middleware makes a fully complete fart platformer of Mario hunting Sonic’s stepson through brain rot content even easier to produce at a high quality standard. This is mostly a positive thing for culture and expression but the industry must acknowledge we will lose some section of our market attention to these passion projects. The long term future becomes the holodeck creation of unique experiences with minimal effort.
Conclusion
The survive till ‘25 motto inherently is driven by a thought pattern that the industry will return to pre-2020 levels. Though this may not be the case and in fact all signs point to it not being. We need to acknowledge that our ever changing industry will once again transform. Much like digital distribution, certification and arcades mutated it in the past the march of accessible tools and generative tools is likely to change the game on us again.
The YouTubefication of games has arrived, the investment landscape has changed and our next decade will be unrecognisable in many ways to the last one.
Onwards games, forever changing.
Setting up a Studio the not dev bits
Setting up a Studio the not dev bits
It’s been a while since I started this little gamedev journey and I wanted to talk about all the bits that aren’t gamedev so I can share what I’ve been up to. This is also why I say making games as a hobby is a totally valid thing and the gap between hobbyist and professional is larger than people sometimes think. Though if you are interested in crossing the gap maybe this will help.
This is in the order I did things, not the order you should do things. Also this is my first time being a company Director of a games company so many mistakes made and I’m sure there is a lot I should do better. If you know of some stuff I’ve missed please shout out.
Working Space
This was while I was still at Adobe and I wanted to separate my at the time hobby gamedev from work while also staying in touch with the community. To this end I found the Tentacle Zone, a gamedev specific coworking space. This was the perfect first step, it got me back into the groove as I dedicated one day a week to gamedev. I met up with other devs and spoke to other indie founders not already in my friend circle. This remains one of the most valuable resources and if you have any dedicated physical spaces with professional gamedevs you can access I would HIGHLY recommend it.
Setting up a Company
I’ve already had the experience of setting up a company with my wife’s book publishing and honestly doing that for the last decade has been a huge level up. If you have any experience running a company a lot of those skills are transferable. This is mostly about setting up a company on Companies House. You will need a company name, business address and some googling for your industry. For the book company we used a virtual office company who we paid a subscription to for virtual office which included mail forwarding and privacy with additional options of renting meeting rooms and such when you need it. It is a great solution especially as we were renting at the time and most rental agreements prevent you listing your home address as a business address but if you own your house you can go with that option. In this case I asked the Tentacle Zone and they were willing to let me use the coworking space as the registered address which was very handy.
There is also the matter of shares, standard in the UK is 100 shares you split among the founders. It is also important to write up documents and policies around IP, disagreements, buyouts if a founder leaves the company. It’s not complicated but you need to have the conversation as early as possible and write out in plain language what those policies and actions work like. What does shutting down the company look like, what does success look like and have a hard think about the biz bits.
Money, Money and Tax
One of the reasons you want a legal entity as soon as possible is so you can file for game tax credits, grants and all other bits. For the book company we filed our own taxes, and did most of the paperwork. For many companies it’s not as hard as people think, especially if you can file micro accounts. Though creative companies, especially with tax credits, means you really should get one with experience of the industry. Thankfully when I asked around one fellow described himself as <person I know>’s dumbass accountant. I immediately had good vibes and I sat down to chat to him.
My mum is an accountant and I’ll admit I have real paranoia because of the amount of crooked money people I’ve met, ironically my mum is one of the most moral and honest people I know so the contrast is stark. So hiring an accountant was a scary step but I think we found a good un. Now accountants typically have a range of services and billing options. We don’t need payroll yet, but we do need VAT, year end and some other bits.
Company Bank Account
Everything must go through this. From experience you will hate anything that doesn’t go through this. Modern digital banks are great options and this is a lot less painful than it used to be. This sets you up with a business card and my accountant signed me up for an invoice tracking thing called FreeAgent, a bit of kinda easy accounting software. Then it involved finding all the things I could file under business like Tentacle Zone ect… and move it over.
Then comes VAT registration which I’ll be honest is a whole ‘nother pain of activation and codes. We had a bit of a faff with mail on this one and this actually took a bit more of my time than I expected. Then I needed to make sure the accountant had all the access and information they needed. Thankfully again modern systems are a lot better for this with read only accounting APIs which are fantastic.
Setting up Website and Social Accounts
We made the decision to call the new company Flammable Penguins Games as we already love the name of the book company and we could reuse a lot of bits though some new accounts were needed and a website refresh was required. This sounds like a small thing but again it all takes time to set up and manage.
Logo Design
Again another fun job and I’m rather proud of the new logo but this took time to concept, draw up and match to the existing branding we have. I thought I would need to hire someone for this job but honestly dusting off my graphic design was just fantastic. Though again not time spent making the game which we hope to ship.

Writing Pitch Decks and GDD
We are mostly self funded at this point but it would be silly not to seek funding where we can get it. Now one of the nice things about being a small studio is you don’t need a ton of documents because you build what you want and you're small enough a few conversations can decide a lot but it turns out you need pitch decks and game design documents for a variety of things.
There are some great templates and resources out there to get you started. You tend to need to write some project decks as well as company pitch decks. It can get a bit awkward bigging yourself up and at the same time talking about your project.
Setting up Developer Accounts
One of the things you need those documents for is setting yourself as a developer on consoles, Quest and other stores you need to do. Console dev is often scary to many but assuming you have a company and the documents to support it like a GDD then you can apply. Sooner is better than later as you should read the submission requirements and access resources sooner rather than later.
PlayStation: https://partners.playstation.net/
XBox: https://developer.microsoft.com/en-us/microsoft-store/register
Nintendo: https://developer.nintendo.com/
Promotion and Networking
Well this includes things like writing this blog, doing an upcoming talk at Develop North and ensuring a certain level of exposure. One thing I learnt from the whole book biz is we suck at marketing and we are doing what we can to improve on that but it does take time away from dev.
Another side of this is meeting up with friends and going to events to stay in touch and ensure you're not going crazy on your little team in your home office. Also our friends and colleagues often bring up things we might have missed. This includes pitching and grant opportunities, because honestly knowing who to talk to and what to apply to is half the battle.
Game Changers
This is honestly my lovely wife not me, though as half the company her time not on gamedev is also handy. It was a big win for her to get on the London Mayor’s Game Changer program. She is getting mentored, founder support and will be travelling to Slush as part of the GC cohort in the next month or so. This has been a huge level up for her and super handy.
Pitching to Publishers and Applying for Grants
Pitching to a publisher is only a few meetings or quick conversations though there is a whole song and dance beforehand. You tend to need to tweak your pitch deck for each meeting, do your research and frankly they are a bigger time drain than you think.
Additionally there are a bunch of grants we needed to apply for. This means instead of a meeting you have to read through all the grant documentation and additional annexes ect… looking for scoring grids and guidelines. Then tailoring the decks and documents to that specific grant. It also usually involves a bunch of form filling and in its own way is even more stressful than publisher conversations.
Godot Engagement and Side Dev work
This falls somewhat under the category of dev work but mostly what I put in this bucket is staying in touch with other Godot devs, checking on engine issues and engaging with the XR working group. This is a biweekly meeting but it's super valuable to the long term future of the studio. Also there is side dev work like adding support for Logitech MxInk Pen to Godot. This was awesome work I enjoyed doing and I love giving back to the community and working on the Pen was just a fun little project.
Biz Dev Work
As much as I want to get my head down and focus on the project you need to keep an ear open because you never know when opportunity will knock. The industry is in a rough place and sometimes people need help. Some friends needed a little help with some tech advice, another thing came up where some talent might have been able to come on and join the studio. Additionally people wanted to talk about bits of work mostly which I say no to as I try to focus on the game but sometimes you need to have the conversation to know if you should say yes or no.
Conclusion
Setting up a company is a bunch of work, none of it very hard but it all adds up and I wanted to just document it all to show some of the non-gamedev work that goes into a gamedev company. Thankfully now that it is set up and we have our decks and materials are in order, maintenance is much easier. Also the good news is that Nov-Jan is relatively quiet on the business front as few deals are done over the holiday period. With the madness ramping back up as we approach year end, taxes and our first year end, omewhere in there we hope to launch our first small game.
External Memories and VR Industry
External Memories and VR Industry
I’ve struggled the last two weeks to make time to write about creative tools and volumes. The subject still fascinates me but as I said at the start of this series it was a brain dump before lessons learnt paged out of my brain now I’m no longer at Adobe or thinking about Dreams. Well the brain was not fully dumped the hectic business of running a new studio has meant that it has been thoroughly paged out to long term storage. So while I’m sure I will return to the subject matter for now I need to pause and talk about where my current focus is.
Talk about the deep technical things you are doing, it is more interesting and the details are informative in a way a long term reflection or abstract could not be.
All of us in the VR industry and especially the UK have been rocked by the recent cutbacks at nDreams and the more severe cutbacks at XR Games. The truth is the VR market, much like the wider game market is doing great but the waters are shifting and this means change and it’s hitting us as well.
High Level VR Trends
- Largest VR budgets have increased and more AAA funding is on the table
- Indie VR is booming but results are fickle
- Many established safe bets have failed
- VR Ports are the new hotness, again
- The market favours anything that appeals to a 14 year old demographic
Now this is a tricky one to talk about without talking about sources and I don’t do well convincing people and instead I want to talk about how this is affecting my studio and thoughts I have in this direction.
Larger Budgets
This one has hurt us the most, as well as other small players looking for funding. Start of 2025 the industry was in the lurch. Financing and investment which is always the puppet hand behind creative industries was experiencing the most expensive credit for over a decade with most capital allocated and stretched onto the Covid big spend. Delayed budgets and lower than expected returns meant that almost everyone including the big players like Meta were looking to make more diversified smaller bets with a potential higher ROI.
It is important when thinking about ROI it is not the return on investment vs the money doing nothing but rather the comparison against a stable index fund or safe investment. This means even modest ROI becomes more difficult in times of inflation and raising costs so this pushes expected returns way up.
This coupled with a large amount of startups funded by redundancy money, more entrants into the VR market, over 50% of active developers have entered the VR market since April according to Meta at last week’s Connect, means that competition has heated up. With a wide crop of funded small teams producing quality content the market has heated and discoverability has become a bigger issue. Also for the last four years the market has been begging for larger titles and with more headset competition on the way providers are looking for their system sellers.
This led to a bit of a rug pull I did not predict in the last three to four months of smaller budgets being cut out. Projects being cancelled and funding consolidated into larger bets many of which are driven by established IP. This is great for consumers as we can expect some larger, more complete premium titles on the market, and good for developers as it raises the price expectation and quality bar of VR craft. Though it does pose a serious risk as a failed larger budget project can sink a studio single-handedly.
Indie Random Toss
The breakaway success of “I am Cat” and “I am Security” as well as a range of other small titles which have had great returns even with more modest sales has put people back in the mind of breakout success. Though when I sat down with some others and did the numbers recently the failure rate has gone up in the market in recent days.
With chart driven sales we are seeing dynamics very similar to the iPhone 5 era of app development with kingmakers grabbing their chart spot and hanging onto it. Algorithmic discovery is still largely unknown and marketing budgets being small. The days of releasing a game and if it’s good it will be discovered are ending for VR. I expect we will get to algorithmic recommendations sooner than we did for the mobile market but I also expect discovery to take a short term hit.
Immediate appeal and marketing plans are now key factors for indie devs in the VR space, not yet to the competitiveness of other markets but it is increasing fast. By January I believe the Meta Quest store will be a completely different animal. Quality still matters but immediate visual appeal and chart position are increasing in importance fast.
Sidenote: I am Cat while a polished game takes a lot from a Ludum Dare game which was later reworked into a full VR game and published on Steam and PlayStation called Catlateral Damage. I highly encourage you to look at this earlier work.
VR Ports
The amazing rise of Flat2VR is welcome and long overdue. The truth is that many flat games with a small amount of effort make great VR games. The largest barrier being standalone performance. Though I would encourage more devs to explore PCVR and PSVR2 ports of their titles. Smaller ports can even be sold as DLC addons.
We saw this effort originally on PSVR1 as a common tactic but the lukewarm status of the market, the underdeveloped support of VR in the big engines and lack of market understanding led to poor adaptations for the most part.
Now with a mature VR market, with a settled and common control scheme and high enough resolutions to avoid the need for large scale UI reworks we will see a huge rise in this area.
Additionally the support of Flat+ style applications on Meta and Apple headsets means we will see many titles present mostly as flat and only going 3D when it works for the title. This combined with the value of IP recognition and development costs means that I expect more ports in the VR charts from mid 2025 onwards. I know of at least ten developers actively considering VR ports at the moment.
The key barrier which might stifle this trend is down porting to mobile hardware required for Quest support is a huge technical ask and many won’t want to make it. Though on the flipside I think changes in the next year will make PCVR a much more appealing market which should also help mature the console VR market.
18 Rated built for Teens
Rough as this sounds, we need to look back at the 90s PC market. The truth is that the bulk of time spent in VR is by teens who drive market adoption, even if their spending power is reduced their impact is mighty.
EVERY SINGLE TITLE IN THE TOP 20 ON QUEST APPEALS TO A TEEN
While some of them may have higher ratings they all market and present in a manner I can convince a 14 year old is cool. The possible edge cases being Golf+ and Table Tennis though sports are easier to sell because of real world recognition.
The industry has a “problem” most of us are older and more mature and to be blunt burnt out. We have developed a taste for comedic self questioning and deriding humour as well as a broader aesthetic appreciation. Sliding through the top games in a year is a delightful and broad palette of complex flavours from high art to deranged comedy with our fantasy often being as simple as cleaning, running a small shop or escaping from a traumatic relationship with a goblin racoon.
Due to the younger demographic however VR needs to be more sweet and simple in flavour. This does not mean underestimate your audience but imagine walking into a classroom of 14 years olds and pitching your game. What excites that audience is the spectacular, simple humour and empowering fantasy. They want the explosions and dumb much like we did when the game industry was younger. We want the simple premise of King’s Quest or Duke Nukem.
You can build complex games which have interesting depth but your pitch needs to be robust to the younger demographic which dominates the VR market.
What does this mean for Flammable Penguins Games
Well the main project which has a more nuanced appeal has been put on the shelf for more concept development and thinking about how we could sell that fantasy better. In the meantime we are pushing fast on a smaller title to prove out our technical pipeline. Though to be honest I don’t think it will appeal to the core demographic I highlighted above but I do think it will find its audience.
The project is a small work of passion because I want to play it in VR and I think it’s time for a title like this. Also it has a small budget with simpler tech which provides a strong basis for our console porting work. I’m not yet ready to announce that.
Finally the game we return to might not be the shop game as originally intended but instead one of our concepts which might be better suited. I hope to announce our smaller title this month and launch it before year end. So wish us luck and let me know what you think about these thoughts on the industry.
Surface vs Volume Formats in Tools
Surface vs Volume Formats in Tools
The long-established default in the modeling space has been the transition from pushing pixels to manipulating points in space. Originally defined with a lightpen scanning physical models or handwritten points in code into point clouds. Over time, the ambiguity of points in space led to the dominance of the triangle or surface representation. Today, we explore whether this is still the best format for our tools to work in. What are the advantages and challenges of moving to volumetric tools?
Note:: This is a large topic so there will be a second part next week
Key Takeaways
- Triangles have superior mathematical properties for rendering efficiency.
- Volumes are better sources of truth and easier to sample.
- All volumes have a surface, but not all surfaces have a valid volume.
- GPU advancements now enable direct work with volumetric data in creative workflows.
- Future 3D modeling likely shifts to volume-first tools, with triangles remaining in final rendering.
- Hybrid approaches will bridge the gap between volumetric and surface representations.
The Fundamentals: Surface vs. Volume Representations
Comparing Cubes and Spheres: A Tale of Two Geometries
Before we delve into why triangles have become the dominant format, we need to explore the more fundamental problem space of surface vs volume representation.

In this ideal use case, a cube can easily be defined with 12 triangles with no loss of data. However, in the case of a sphere using purely planar triangles, it is effectively impossible to have no data loss, so we always have some degree of data loss or must use more implicit surface representations. The issue is that worst case volume scales in a cubic, in the common case surfaces are a squared progression though the worst case surfaces are infinity. Though in practical terms this is avoidable for surfaces in general volumes are more predictable though heavier weight data formats.
The Spectrum of 3D Data Formats
As you can see, the space of surfaces is DOMINATED by triangles, but it's important to realize the breadth of the ecosystem out there. Here is a brief overview of most the formats that come to mind:

The Reign of Triangles: Understanding the Status Quo
Mathematical Superiority of Triangles
The mathematical superiority of triangles is hard to argue against:
- Given any three points (not in a line - collinear) you get a valid triangle
- Barycentric coordinates for interpolation is easy and fast
- Given a fixed 2d perspective it is easy to sort and organize
- Line to Triangle intersection is fast, solid and predictable
The first two are strong arguments which always hold, but interestingly, the third point is only relevant when moving data from 3D to a framebuffer. The last one has wide application to creative tooling as we often want to project to or select a surface.
Historical Context: The Triangle Limit
Another significant reason for the dominance of triangles, which we touched on in the intro, is the data compression factor. Any artist of a certain age will be strongly aware of the triangle limit. Working with any abstractions from the real final data loses artistic control, which was very obvious when our limits were so low.

It is my firm belief that when talking about graphics engines and final render pipelines, triangles will remain a dominant format long into the future. Even with the increased usage of ray tracing, triangles will always need a good strong option for exporting to triangles regardless of format.
The Volume Advantage: Challenging the Surface Paradigm
The False Equivalence: Surfaces vs. Volumes
For any volume there exists a valid surface,
but not every surface represents a valid volume
This is the key argument for why our toolchains should maintain volumetrics for as long as possible. Even real-time graphics engines often need volumetrics for lighting, physics, or other calculations.
Conversion Challenges: From Surface to Volume and Back
Due to the dominance of surface representations in our tool chain, the methods for generating volumes from surfaces are very mature and well-established. However, they often require assumptions or are fragile to non-watertight meshes or other open cases which break the conversion. The algorithms are often very expensive for high-quality volumes.
The conversion of volumes to surfaces is less well represented. The most well-understood method, marching cubes, was locked behind a software patent for a key period of graphics development, stunting the growth of these methods. It is no longer patented, and more superior methods like dual contouring now exist.
The Complexity Spectrum: From Explicit to Implicit Representations
Explicit Representations: Triangles and Voxels
Triangles and dense voxel grids are at the most explicit end of the spectrum. There is a one-to-one mapping of data which is very predictable to process. Though as covered in earlier articles, our bottleneck on modern hardware is typically related to I/O. So even when a format takes a little more time to process, it is worth the tradeoff in many cases.
Complex Explicit Representations: Textures and UV Mapping
This moves into more complex formats, with things like textured surfaces using displacement maps and other UV mapped 2D data. This is a complex explicit representation but is still explicit; it requires even more data lookup, as well as some calculations. UV Mapping also adds an additional fragile quality beyond the scope of this article to discuss.
Implicit Representations: NURBS and Signed Distance Fields
Another approach which does not require additional data lookup but calculation are methods like NURBs and 2D signed distance fields. NURBS (Non-Uniform Rational B-Splines) are mathematical surfaces with a high degree of precision and flexibility. They are defined by control points, weights, and knot vectors, allowing for smooth, easily manipulable surfaces. Car manufacturers and people looking for precision surfaces really like these models, but they tend to be very computationally expensive.
Game Engine Approaches: BSP Trees and CSG
Game engines have traditionally preferred BSP Trees and CSG, typically building BSP from CSG. Constructive Solid Geometry (CSG) combines simple shapes to create complex 3D models, while Binary Space Partitioning (BSP) trees efficiently subdivide space for rendering and collision detection. In Quake, CSG was used to design levels, and BSP trees generated from these designs enabled real-time rendering of complex 3D environments on mid-1990s hardware by quickly determining visible polygons from any viewpoint.
Advanced Volumetric Representations: Sparse Voxel Grids
While CSG works well for coarse level design, it does not scale well to artistic shape and form. Another approach taken by photogrammetry and simulation formats like OpenVDB is sparse voxel grids. This takes the approach of representing volumetric data efficiently by storing only the relevant, non-empty voxels in a hierarchical data structure.

Sparse voxel grids or level sets divide space into a grid but only allocate memory and compute resources for areas containing actual data or near the surface of objects. This allows for highly detailed and complex shapes to be represented without the memory overhead of storing empty space, making it possible to handle much higher resolution volumes than traditional dense grids.
Adapative grids are also really interesting by storing data at each graph point you are able to reduce the node count. Also You can adaptivly sample the grid for the desired level of detail. This maps well to certain GPU texture optimisation modes. Though typically a blend of approaches is used with a low level lookup vs a high level grid. Finally using scene tree for the highest level of sparse data.
Beyond Binary: Occupancy and Density in 3D Representation
Occupancy: The Traditional Approach
The traditional triangle surface or voxel grid works on the concept of one-bit occupancy. There is either a surface or volume there, or there is not.
Density: Adding a New Dimension to 3D Data
Density doesn't really exist in most surface representations, though some volumetric capture data from medical imaging and volume simulation software creates it. Density is great for VFX use cases like clouds and fire simulation. It also has pretty awesome physics and sculpting properties. For physics simulation, light transport, and even gameplay, this is an interesting property. In the case of tools, you can squish and pull while maintaining volume, like real materials would.
This dynamic manipulation property is one I really wanted to explore in the future, though I am now unlikely to dedicated the time.
Material Properties: Transparency and Surface Interactions
There is a concept of material transparency. In the world of surfaces, we can use those additional data channels to lay on alpha or transparency, but it is fundamentally not a concept which maps well to our real-world understanding of light transport and physics. In most cases when we need to calculate surface interactions, we fake it or we infer a volume to calculate thickness, sometimes assuming a simple in-and-out model based on surface facing. In the world of volumes, we just say this volume or sub-volume has an index of refraction of X.
Performance and Practicality: Navigating the Tradeoffs
The Cache Compromise: Balancing Speed and Memory
When working with volumetric data, caching strategies become crucial for maintaining performance. Both volume-to-surface and surface-to-volume conversions can benefit from caching, reducing uncertainties and improving overall performance. However, caching comes with its own set of challenges:
- Cached data is heavy to move, potentially causing I/O bottlenecks.
- Cached data often needs reconstruction, which can be computationally expensive.
- Caches consume valuable video RAM, a limited resource on many systems.
Surface Regeneration: The Volumetric Editing Challenge
One of the key challenges when working with volumetric data is the need to regenerate surface representations when editing volumes. This process can be computationally intensive and may introduce latency in interactive editing scenarios. Several strategies can be employed to mitigate this issue including incremental update and multi resolution.
In Dreams we had a fast path surface generation for responsive sculpting then a more correct slow pass which was done in the background as the stroke completes. Most of the time a user is idle in creative applications. That sounds strange but even in a flow state from a computers point of view the time between brush strokes is massive.
An alternative approach is avoid caching entirely and work directly with ray casting applications. I think in realtime modelling applications the computer graphics hardware is fast heading towards that direction. Though when not working directly with surfaces a caching approach is still likely to be superior in render times.
GPU-Centric Workflows: New Horizons in 3D Processing
Recent advancements in GPU technology and memory management have opened up new possibilities for volumetric workflows:
Direct Memory Access on GPUs: Modern GPUs can load memory directly from the hard drive into GPU memory using Direct Storage APIs. This capability alleviates many issues related to data transfer and management.
Keeping calculations in video RAM: By performing most calculations directly in GPU memory, we can avoid expensive host-to-device memory transfers.
GPU-based volumetric operations: Implementing volume editing and surface generation algorithms directly on the GPU can significantly improve performance for interactive workflows.
However, working entirely on the GPU comes with its own set of challenges:
- Limited memory: GPU memory is typically more expensive and limited in size compared to system memory.
- Complexity: All operations must be written in GPU code, which can increase development complexity.
- CPU-GPU synchronization: Managing data coherence between CPU and GPU can introduce additional complexity.
Looking Forward: Emerging Solutions and Future Directions
Lightweight Volumetric Formats: Addressing the Data Challenge
To address the challenges of storing and transferring volumetric data, several lightweight formats have emerged:
- Implicit Signed Distance Functions (SDFs): These provide a compact representation of complex volumetric data.
- Constructive Solid Geometry (CSG): Allows for efficient representation of certain types of geometry through boolean operations.
These formats offer reduced storage requirements compared to explicit voxel grids and can be more efficient for certain types of geometric operations and queries. However, they may require more computation to evaluate compared to explicit representations, and certain operations might be more complex or time-consuming. In a future article I do want to talk about some of the data advantages of implicit SDF over CSG though again this article is already long.
Hybrid Approaches: Combining Surface and Volumetric Strengths
As we look to the future, it's likely that hybrid approaches, leveraging the strengths of both surface and volumetric representations, will play an increasingly important role in creative tools. These hybrid methods could potentially offer the best of both worlds: the editing flexibility of volumetric data with the rendering efficiency of surface representations.
Conclusion: Shaping the Future of 3D Creative Tools
The choice between surface and volumetric representations in creative tools is not a simple one. Each approach offers distinct advantages and challenges, and the optimal choice often depends on the specific requirements of the application at hand.
Surface representations, particularly triangles, have long dominated the field due to their mathematical properties and rendering efficiency. However, volumetric approaches offer advantages in terms of representing complex geometries, handling multi-scale detail, and providing a more intuitive editing experience in some scenarios.
Through due to the imbalance of the false equivlence volumes are a fundementally a better source of truth than surfaces. Computers are now fast enough to work directly with volumes, which open up new workflows.
As hardware capabilities continue to evolve, particularly in the realm of GPU computing and memory management, we may see a shift towards more volumetric workflows. The ability to work directly with volumetric data on the GPU, coupled with advanced caching strategies and lightweight volumetric formats, could potentially overcome many of the traditional barriers to volumetric adoption.
Ultimately, the ongoing evolution of 3D representation methods continues to shape the field of creative tools and computer graphics. As we push the boundaries of what's possible in 3D modeling and rendering, we can expect to see continued innovation in data structures, algorithms, and workflows that bridge the gap between surface and volumetric approaches.
The future of 3D modeling for realtime applications is complex but I believe it is time for a fundemental shift to a volume first creative tools workflow. Dreams, Modeller and their cohourts are the first in a wave of change to come. Though triangles will still often be the last geometry before rasterisation.
Godot on Console
Godot on Console
Taking a break from my tools articles to write about Godot on PS5 and PSVR2.
I’m going to lay out
- My disagreement with the statement given
- Thoughts on W4 vs Foundation lines
- Go over their reasons
- Explain my studio plans, which include freely sharing any Godot port work
I am sure that there are many things which triggered the Godot foundation to put out an article stating...
The Foundation does not plan on providing console ports at this time
Pretty spicy and strong statement, and I think it's a bad one but let's step back. As this series of articles has shown, about a month or so ago I stepped down from my job at Adobe and returned to my lifelong passion of games. I spent the bulk of that time at Sony PlayStation in a core tech team and then later shipping Dreams with Media Molecule. Prior to that I worked at a bunch of studios and a LARGE chunk of that work is porting. Often other companies and a variety of tech bases. I’ve shipped code on all of these platforms using custom in-house engines: PC, PS5, PSVR, PS4, PS3, Web, Mobile, Xbox 360, Wii, Nintendo DS and PS2. Yes I also have experience with Unity and Unreal but custom tech has always been my preference. I am not a render programmer or dedicated engine programmer by trade but I have done both jobs.
There are no villains in this story. I think everyone is awesome. I love Godot as an engine and I think most of the folks at W4 games have their heart in the right places, doesn’t mean I can’t disagree.
But as I’ve covered, I recently started my small games company and as part of last month’s paperwork I signed up for a PlayStation developer account, signed a bunch of contracts, got my umpteenth DevNet account and signed in. Here I asked about the status of Godot and honestly was quite shocked at the response.
It was a friendly enough exchange I can’t share because it was behind closed doors so to speak. I also had a more productive conversation directly with Remi but a line on the forum from Juan stands out to me.
I am curious what makes this different from Unreal and Unity, also maintained by third party companies.
Now my stand should be clear from the recent article I wrote about Godot being a great tech seed but yeah the whole point of using Godot is it was different. The smart short term decision is to use Unity or Unreal which pound for pound are more capable engines able to ship higher quality games today. I’m investing in tech, my studio and frankly trying to build a house instead of renting one. So no, I don't want W4 games as my landlord.
W4 Difficult Position
Before I get into these I want to double down and say I don’t think anyone is behaving poorly. Godot has been in development for a long time. A lot of people worked hard for a long time to build it and didn’t get paid. There are a variety of ways to monetise Open Source projects and frankly we all have bills so no shame there.
There is a big issue that the key maintainers and founders of the project are also the key figures at W4 and that is always going to be a hard needle to thread. A lot of their actions are going to be under public scrutiny, as they should be with foundations and charitable orgs, and they won’t get it right all the time but I believe they are doing the best they can. AGAIN PEOPLE HAVE BILLS TO PAY!
That said it will always be tough, like was W4 games the best partner to receive a lot of money from Meta to do closed platform work W4 Games and Meta Team Up to Expand Open-Source Godot Ecosystem on Meta Quest? Honestly probably but you can see how that brings up interesting conflicts like what does the foundation take on and what does W4 games take on. Does W4 get business opportunities which come out of meetings between company A and the foundation, probably. But it is also often easier to engage with a commercial entity when making those kinds of deals.
Again everything I’ve seen is people are mostly being above board and good but I don’t want to rent, I want to buy. So engaging in commercial agreements with W4 games is not in my studio's best interest at this time.
Reasons Given
- Legal liability
- Disproportionate cost
- Open source licensing issues
Legal and Open Source
The legal side again without breaking NDA this is a tough discussion but the short version is when you submit a game to a console provider they want to make sure the code is safe, legal issues are resolved and the product is of a certain quality. The modern console era as we know it was established by the Nintendo Gold Seal of quality during a mad rush of game development and one of the bigger crashes, a strong argument for quality and curation.
What this means in process terms is you submit a list of software used in your game. Any legal agreements, licence and such. This is to ensure you're in line, not submitting copyleft software for example which would be incompatible with console licence but also saying you have a legal right to all the code. Ultimately you as the developer are directly liable for all code in your game, including game engines. Now there are some lawyers who can and have argued deferred responsibility but as written you take the direct responsibility. Note I am not a lawyer, this is mostly a checkbox activity but like any contract it’s very serious.
IT IS VERY EASY to paint the consoles as the bad guys but they aren’t. In fact many games ship with open source libs in them including SDL, STB lib and many other fan favourites. In fact ImGui which everyone loves started out inside Media Molecule and Sony gave Omar the licence to continue developing it as an open source project (he was the original author but he did it while working for Sony). Sony also released the Phyre Engine which is an open source game engine developed internally. They have also released a bunch of internal frameworks right on github. https://github.com/SonyWWS
Internally most console forums have a section for developers to share code with each other under the umbrella of console NDA. A common model in the modern era is, speak up here to be added to a private git repo. Would it be better for everyone if the SDK were available (not open) like iOS or Android. YES! Argued it for years. But the current arrangement does not prevent the development or sharing of MIT licensed code for consoles.
So ultimately I find this a thin argument, and no-one is going to pipe up from Sony so it’s easy to say boo big company evil when in this case it’s clearly not the case. Complexities yes, but Open Source on console is well established.
The Cost
Honestly this one holds the most water, work has been done and people want to get paid. I do want to take issue with some communication I have seen internally and externally as it reeks of omg guys this is so hard give us money. Porting varies greatly in quality and completeness but getting your game running on hardware is not a monumental task. Assuming you're comfortable with engine code, which not everyone is.
Most of the code will be unchanged, the bulk of the work is going to be in the renderer and honestly there are so many resources from the console providers that porting a known renderer like DirectX or Vulkan to the internal API is just a bit of a slog. The only consoles which are a real pain to port to are handhelds for performance reasons. The only real pain was the PS3 to PS4 ports as that was the shift from the 32bit to 64bit era, omg so much broke. Also down porting to the Wii…. omg the horror.
Honestly it’s a slog and an investment but this is exactly why community ports or work by the foundation would be PERFECT. Let’s do the slog together. Though you would be shocked to know how many full time staff were assigned to the PS4 for Unreal, a tiny amount. There are some complexities like making Godot shaders compile to console specific stuff. Having more heads hitting the problem and frankly more devs engaging in hardware SDK the better. The industry is fast losing the skills it needs and it was scary comparing the PS4 and PS5 launches how few people were technically engaged. It's a real problem.
Also annoyingly PlayStation has hit teams of experts, as does Xbox, AMD and nVidia who get sent into studios of bigger titles to help beef up their engines to run better on their hardware. Including Unreal and Unity. I would prefer that time to be invested in something all the developers on the console can use instead of a private company semi attached to the engine.
There are also a bunch of platform libs for things like leaderboards and achievements. Again for Godot on Quest there are projects like Godot OpenXR Vendors and decacis oculus platform libs which handle a lot of this for you on Meta devices. They are also separate because they interact with private company code you need to agree to a specific licence to use, though the second one is community maintained, not by the foundation. As long as you read your console SDK documentation this is pretty easy work and mostly a checkbox activity. Be sure to pay close attention to submission requirements though.
The other thing I want to highlight is if you think you're shipping a game on console, getting through the various compliance checks and hitting any kind of quality bar without some code time, inhouse or contractual, from an engine level coder you are dreaming. Or you are shipping one of the most basic of basic games.
My biggest gripe is almost any console port will involve building custom code, and if you're painting the house and doing DIY you better bloody well own that house.
That being said, a bunch of peoples’ salaries were paid for a bunch of time to develop this code for W4. They can do what they want with it, and I hope for everyone’s sake they make some money. The more Godot game studios which are financially stable the better and they are the OG.
My Plans and Releasing a port
Okay so I’m 100% head down on the first studio title. It is a smaller title which will be out sooner rather than later. We are entirely self funded off savings at the moment, though I’m having publisher convos. It will also be the test shot through our systems, professional, technical ect… our lead platform is the Meta Quest but as someone who helped develop the PS5 and PSVR2 they have a special place in my heart so yeah that is going to follow “soon” after.
The first game is much smaller and easier to port. So I plan to do my own port, it won’t be pretty clean or great but it will work for me. In the spirit of community I plan to share that in the private walled garden of PlayStation for any other devs who want to reference it to help with the slog and welcome any support in those efforts.
I make no support commitments, and hopefully going forward I can share more. I’m not making any binding commitments because oh god lawyers but yeah it will likely all just be MIT use as you will, and don’t expect it fast.
Is this the best financial decision, in the short term hell no. But if I was thinking short term I would be on Unity or Unreal. I'm choosing to invest in my studio and the community and hoping that long term it will pay off. I'm trying to build a sustainable studio.
Hopefully I can lure some old Sony pals in to help out, and hey maybe your studio is thinking of doing a port. I know this is only one console and as a VR studio I’m hyper focused but hey it’s a start and for me that is the spirit of building things with the community and giving back. <3
Hardware Handcuffs
Hardware Handcuffs
At the backend of almost years of creative tooling work with Substance 3D Modeler and Dreams I am brain dumping lessons learnt and this week I want to talk about what the actual data handcuffs are. In a later article I will talk about higher level parts of this problem and solutions but today let’s talk about the true data handcuffs or limitations: HARDWARE!
Conclusion at the top as always to save you the time:
- Buffered Grids of Pixels dominates visual display tech
- Audio waveforms dominate to an even greater extent
- Their reign is relatively new. See old AV tech.
- Special cases still exists but backpressure from dominate formats stagnate our tool pipeline
- Small evolutions are happening, see some changes for VR
- VR makes consistent depth buffer mandatory
The Audio Visual King
It is safe to say the bulk of creative content which is consumed today, towards the order of high nineties percentile is Audio Visual data which is expressed by oscillating a speaker and displaying a grid of pixels for viewing. This is a fairly constrained creative bottleneck enforced by high degrees of technical entropy which would take a massive cultural and capital investment to shift.
These data formats, while influenced by our biology, see Bayer Filter encoding, are not innate to our biology. Even our experience of sound involves more than just our ears detecting air pressure modifications. Though for the most part we can agree the AV format rules the world.

It should not be forgotten though that other targets exist with their own limitations. Print media for example is still a massive part of society. By volume of unique creative output it is relatively low but I guarantee you have seen at least one billboard, book, magazine, or flyer today.
This was not a foregone conclusion; our audio format was dominated by sheet music far longer than the current waveform technology has existed. For a long time the early wax cylinder was outdone by digital sheet music in the form of mechanical player pianos and kin. With bespoke mechanical music boxes bring their own unique and non-standard method for audio encoding.
Likewise the visual format evolved a lot in my lifetime despite seemingly being locked in time. We moved away from crystals on film for example. Vector displays with their high contrast monochrome were in the arcades of my youth,. I remember playing handheld gaming devices using LCD segment displays fondly. I even recall a hospital using a typewriter style display in its admin department though old even then.

The point is AV waveform pixel grid format is dominant. It is the king of today, long live the king.
Driver Entropy
While not a law of nature the path of least resistance means even new methods of display tech will conform at a driver level towards traditional formats. The most concrete example of this is the VSync being a hold over from the once dominant CRT display.
I recall enthusiastically coding for my Pebble Watch because they had made the bold decision to expose per line updates because that is how the hardware worked and battery drain of flipping a line was noticeable on the always on eInk style display. Many modern handheld and wearable devices would benefit from this level of optimisation but now we depend on the driver to throw away unneeded pixel updates after we did the hard work of computing them to save on screen cycles.

While still a lovely programming challenge the Pebble was eventually killed by Apple watch and other full colour watch displays. Those at the driver level were performing these kinds of optimisations but from a software point of view were still mostly the standard double buffered grid of pixels we see on every other display technology.
The point is that our software ecosystem has become so well established that even were a new display format to emerge it would likely be constrained to traditional display paradigms and only survive if it can outperform existing tech using old formats, even if it was superior in other non standard ways.
Wonderful World of Special Cases vs Tools Ecosystem
Much like wearable devices provided a strong limit with battery power leading to innovation in the display space. There are other weird special case situations. Museum or installation pieces. Advertising or limited use displays doing projection mapping or unique updates.
Mechanical printing, be it additive 3d printers, traditional 2d plotters or a manufacturing process which provides an economic or material advantage. There are special case outputs in the wild worth paying attention to. MIDI music, the digital holdover from those self playing pianos still can power physical instruments like a robot. So unique use cases exist.
The bulk of things printed on addictive printers are 3d models from traditional tool pipelines then fed into slicer software to convert the volume into GCode or similar format, basically a list of vector lines in space with tool configuration changes. There is a real opportunity to produce that data from entirely different pipelines. See new manufacturing tech like Incremental Sheet Forming.

The reality though is the back pressure from the AV king keeps our tools pipeline pretty rigid.
Virtual Reality: The king is dead, long live the king
Despite our innovations in spatial audio, and attempts at non standard display formats, the world of XR is basically unchanged from a CRT monitor with a speaker. Though basically unchanged is not the same as unchanged. Cracks are emerging.
The first crack is we are now producing two inherently linked images. Early VR had massive performance issues because we treated these as two unlinked framebuffers. Now with (multiview) in Vulkan and other render API we acknowledge that these are linked and from almost identical spatial positions. Thus allowing massive optimisations in vertex processing and even some fragment processing. This is an area of innovation to keep an eye on.
Likewise the advent of higher contrast displays, predating VR as HDR, are starting to move into the space requiring higher bit depth. At the same time offloading rendering to a disconnected device be it in home streaming or cloud streaming is becoming more popular which pushes against these higher bit rates.
With the release of OpenXR 1.1 the quad image format championed by Varjo is now part of the standard. This basically means four image buffers: two low resolution and two high resolution images. In some headsets this will be physically separate displays like the Varjo, in others it will be software mapping to foveated rendering powered by eye tracking.
Finally perhaps the biggest change to the format and discussion is the depth buffer. Longtime artefact of 3d rendering we have never, outside of fringe use cases, needed to present to display hardware. Though in a world of synthetic frames and ultrafast framerates it is now a must to present a depth buffer to headsets. This is the biggest visual presentation change in a while.
Wrap it up
I want to talk about how this pipeline pressure manifests in our tool chains, what is fixed and what isn’t, but this was the end of the pipeline. Mostly stable but some things are changing with unique uses cases which can’t be ignored. Again the takeaways from the start of the article:
- Buffered Grids of Pixels dominates visual display tech
- Audio waveforms dominate to an even greater extent
- Their reign is relatively new. See old AV tech.
- Special cases still exists but backpressure from dominate formats stagnate our tool pipeline
- Small evolutions are happening, see some changes for VR
- VR makes consistent depth buffer mandatory
If you made it to the bottom please tell me on your platform of choice what your favourite retro or special case display or audio tech is. I love hearing about them.
Questions or feedback to me on Twitter or Mastodon please.
Also a reminder that the RSS Feed is still a thing.
Why Build Tools? The Metaverse Problem!
Why Build Tools? The Metaverse Problem!
As part of my brain dump series on writing creative tools off the back of Substance 3D Modeler and Dreams I want to talk about WHY I was working on creative tools. Back in 2014 when I first interviewed at PlayStation with hope of being involved in the Morpheus Project, a wire basket VR prototype I had started developing prototypes for as a 3rd party developer at Climax and would later become PlayStation VR 1, the word which was conspicuous was Metaverse.
Normally I would present the conclusions at the start of the article but this is really the tale of the why and how I got sucked into building creative tools. For the more technical takeaway articles come back next week.
The word metaverse is poisoned now, it wasn’t in 2014. I was applying to join the Online Technology Group, just the kind of nerdy group thinking deeply about networked worlds. As a Stephenson fan, I am unsure if it was I or Richard Lee who first used the word in the interview. It was being thought about by a lot of nerds chipping away at the problem over decades. Two visionaries at Sony who had it on their mind were Richard Lee, the CTO for Sony's internal first party studios and Shuhei Yoshida who was in charge of the division called World Wide Studios at the time.
I was enamoured with Virtual Reality, my previous obsession which I had chased for about a decade was semantic webs and dialogue trees, another story. Both share a common desire of social storytelling and play the power of simulation and alternate realities. These are highfalutin terms and not grounded in how you build things and the real problems but they inform the why. The purpose sharpens the knife of technical choices allowing you to make leaps not obvious to others.
Both Richard and Shu had the kind of long term vision which you dream for in your leadership. I spoke at length about metaverse, lobbies and the problems an interconnected simulation would entail. I dug into the job doing many things but a mainline thread was spawned one day when Richard called my desk, as he was wont to do, with a question.
What does multiplayer look like in Virtual Reality?
This spawned a whole range of discussions but had been started by a discussion with Shu and Richard. It led to a few patents, an internal RnD project, a GDC talk and some real foundational stuff. PlayStation was no stranger to the space, having launched PlayStation Home on the PS3 which was successful. The external perception was of course out of line, but having seen the numbers it did well. I cannot talk about the details of why that project needed to be shut down but we were in the process of getting ready for it. The best summation of the problem I can give which drills to the core of the problem was twofold: the person driving the project had left and the content desert.
Networking is the primary problem
Those who speak the words Virtual Reality and Metaverse in the same sentence are often short- sighted these days but we were not. In fact most people I know really in the space of building connected network spaces know their history, at least those who are successful. I shan’t recant it all here but if you're not familiar with PlayStation Home, Second Life, VRML, Muds, Quake world, The Sierra Network and MIDI Maze they are all required reading.

I hate networking code, so why did I spend a large part of my life writing it? Play is social and networked computers allow a magic that solo play can never match. Even the best single player stories are elevated through social discussion and sharing those experiences. At the time I was also working deeply with YouTube and Twitch as part of PlayStation for the same reason. Networking is hard, but so rewarding. Connectivity matters.
Going from serial networking of MIDI Maze, through the lag jumps of Duke 3D and Quake into the modern prediction and rollback of modern Call of Duty coping with some of the worst packet drop ever during the PS4 era of bad Wi-Fidecisions, crowded air space and Wi-Fi specifications arguments. Tons of teams are improving the low level layers and high level trickery for hiding the limitations of physics.
I was speaking to people involved in PlayStation Now who are the best and most established cloud gaming solution. People forget about it but when I see new players hype out their solution, such as Google and other tech bros, I know the numbers from that service. It works but it's a HARD problem. So cloud gaming was being worked on by some of the smartest people.
Networking optimisation and trickery are key to even non obvious issues like voice chat. While it has a large hardware component, and audio processing which should not be understated for the Metaverse. The hardest issue was solving networking those voices, especially with spatial audio at low latency and resolving the audio mixes in interactive spaces. Sound is slower than light, but we are more sensitive to audio latency. Another networking problem that a co-worker was already solving.
I was confident the difficult networking problems had the best people, money and motivation.
Problem everyone was ignoring
At the time I was doing this work the space was heating up fast and lots of players. Many people saw the dream bringing different levels of experience. Though looking through the space, and reflecting on the problem of Home and the bare bones tech demos being produced by the new tech companies. Remembering fondly and awkwardly my time spent in Second Life but also the complexity we lost when moving from player run text based Muds to the Everquests and Theme Park MMO world, it was all about one word: Content.
Go back and read those big Second Life articles, Content Creators were always in the spotlight. Having worked at Jagex and being in the MMO space, content treadmill and cost of content was a constant topic of conversation. If you look at the most successful metaverse, VRChat, it is driven by a powerful creator economy. In 2014 VRChat was mostly a curious small player. It would be years till the Knuckle and Steam user explosions.
My consulting job and eSports work had me working with YouTube and Twitch deep in the social space and examining the explosion of the web from text to digital photography to video and finally to broadcast the content pipe was exploding. The problem is to inhabit a social connective space you want a 3d world which means you need 3d content which is rigged and animated to be as easy as video to make. That is a HUGE gap.
The User Generated Created Content
The gaming term UGC is now commonplace but it is still very new to the space. While things like Pinball Construction Set have made level design possible for a long time, Build Engine made 3d level design accessible to the masses with its flat maps. Then as we moved to Hammer and Unreal Editor the ramp turned into a cliff. We lose people the moment we need to work in true 3d.

I’ve loved playing with 3d Studio as it grew into Max, programs like Poser and Bryce and the early explosion of innovation in the space. I grew up with these tools but I wasn’t seeing the explosion of 3d content that was needed to power the Metaverse.
The creative tools in games had been getting less powerful not more. More restrictive than the golden 90s mod era of PC gaming. The exception of course was Little Big Planet. The 2008 powerhouse which was 2.5d in nature and created 3d worlds with simple layers and powerful tools which redefined the conversation. Not long after Minecraft started development, remind me to write about the funny Jagex story there. We saw a ton of people exploding in their 3d creativity with the lego brick mindset that voxels enabled for people.
Well Alex Evans was a frequent visitor to the London office and watching early Dreams dev I basically turned around to Shu and Richard and said: Dreams is the answer!
The Dream Solution
If you have a content problem then Dreams is the solution.
I want to write another piece about surfaces vs volumes and various technical hurdles to clean up but I will summarise them here in my perceived order of importance for the Metaverse.
- Performance is hard to predict and scale
- Traditional Tools are filled with arcane knowledge
- Building 3d content with 2d tools
- Game Code is Network Code
- Topology and UV Space
- Rigging and Animation
How does Dreams solve these problems?
Performance
You can see this in VRChat and many other platforms with custom created avatars, not generated from sliders but handmade, it is hard to predict the performance of them. This extends out to loading in levels, random props etc…
Dreams levels were tiny, with the exception of audio samples, the entire dataset was delta based and built up from an optimised storage of the strokes and actions which make the thing. Leading to file sizes orders of magnitude less than more traditional levels.
Little Big Planet is shocking in how well it scales and Dreams even more so. While there were performance issues with some of the sculpting at that time the performance scalability of signed distance fields was insane. Gaussian splats are now all the rage but are quite old tech, as are voxels. The particular mix that Dreams opted for was very scalable and most of the limits were based around memory which was predictable and easy to scale.
Arcane Knowledge
Dreams gave us a chance to re-examine every step of the creative process.
While many could accuse Dreams of having its own store of weird knowledge you needed to acquire very little of it was required to make things. As Kareem explained, it was a musical instrument. The basic chords could be learnt very quickly but the mastery would take your lifetime.
The issue with traditional 3d pipelines is it requires an apprenticeship or consulting ancient tomes to know how topology affects rigging and skinning optimally. Our current pipeline is not designed from first principles but rather evolved from layers of interoperability and compromise. Trends started before personal computers still today define the modern art pipeline.
3D Tools
Before VR, the thing which started the 10 year journey of Dreams was the Move Controllers when AntonK made the first block prototype. It was driven by the fact you had the first true 3d tools in a consumer device. 6 DOF tracked controllers even without a VR headset transform the problem space. Bringing it more into the range of giving a child coloured putty to sculpt with.
Now it was obvious that VR was going to be a big part of Dreams' future.
Network Code
The fact that Tim Sweeny set out to write a new functional programming language for UEFN called Verse made me certain he was taking the problem of the Metaverse seriously because as any network programmer will tell you the real problem is that ALL logic is networked. So often networking bugs were from programmers higher up the stack not thinking how their state works over a network. The halting problem and various nightmares exist especially in a low trust environment with user made content. Functional programming is an obvious step for those who study the problem but functional programming in text is hard to explain.
It turns out that analog circuits and visual scripting however maps well to the problem space as well. Redstone and LBP/Dreams gadgets are large grids of logic which can be evaluated in a network friendly manner when built correctly.
UV and Polygon Problem
Triangles are fast. They have basic maths properties and years of hardware investment which mean that it is unlikely to change in the near future. That being said, the final GPU representation should not dictate the creative process.
In the days of Quake going from 150ish triangles, to 300ish Quake 2 up to 1500 triangles in Quake 3, it used to be true that triangles matter. At the start of the PS4 era we were talking 100k for typical character models this is not the same conversation.
Texture space used to be 128x128 pixels but now we use multiple HD maps for a single character. With often the shader of material work making more of an impact with things like self shadow, ambient occlusion removing a lot of the custom texture work from past generations.
Topology was likewise critical when elbows bent like a bad paper straw but now complex rigs with secondary support for muscles and morph groups mean the game has changed.
There are better ways to solve both surfacing and animation of volumes. Dreams had solutions to these and while I have since seen better solutions Dreams made the bold choice to not have textures and not care about topology.
Rigging and Animation
Rigging and animation are another arcane art which is both fragile and loaded with arcane knowledge. Knowing how UV scrolling, topology affects rigging and then losing all of the work because the animation retargeting process, a modern lifesaver, didn’t work and you need to clean up after losing or corrupting months of animations.
This final stage of the process is often curtailed, time pressured and limited by earlier decisions. Also animation of a 3d object with 2d tools is even harder than static 3d content as an entire new dimension is added to the problem.
Dreams was approaching this from day one with a mind towards puppetry and accessible animation. That combined with early mocap work I had seen coming out of the early Vive/Lighthouse system showed huge promise. This is also after working with Computer Vision on earlier projects and knowing there were better ways to do it.
End of the Dream
One day there will be a book written, hopefully not by me but by those deeper into the history of the project. Though I have thoughts. Time has healed a lot of wounds and ultimately a great game was made and you can still play it today.
PSVR2 and PS5… I feel the most regret here. I tried and the fact it is forever locked to PSVR1 still hurts.
PC Version and Export… would have solved my Dream content problem.
Networking and Metaverse…. We tried.
Why aren’t you still building them?
Dreams was wild. It was like a rock tour, though more on the scale of a massive world tour of a successful band doing their new album with all the baggage that entails. It was hard but it was a rollercoaster and while it hurt it suited my temperament. Almost everyone I speak to in the creative space has heard of Dreams so I know we made the splash where it matters. We showed the way.
I wrote about why I thought now was the time to leave in Adobe the first article of the series.
So is content still the biggest problem…
When I joined the Modeller team the ocean was blue and the space wide open. I feared with the oncoming death of Dreams the magic would be lost before we could change the creative workflow. Through the last four years we have seen an explosion of tools. Things like Gravity Sketch, OpenBrush, Uniform, MagicaCSG, WOMP and Unbound.io made me sure the space would now evolve. Voxels, SDF, Nerfs, Surfels, Splats and other modern reps are being discussed and shipped in big software stacks.
Finally the big changer of AI and generative 3D, which I will definitely write about soon.
I wanted to make 3d Content easier to make because I wanted richer digital worlds.
The solution is not here yet, but I’m confident that it will be soon and that I’m not the best person to work on it. Just like I knew I wasn’t the best person to work on the networking side of the problem.
I know this is a less technical, more long form article but I thought it was important to outline because it will inform some of the technical points I make in future articles. As I said, the why is a knife which lets you cut through to the correct decisions.
Godot: The Secret XR Tech Move
Godot: The Secret XR Tech Move
As part of my brain dump series on writing creative tools off the back of Substance 3D Modeler and Dreams I want to talk about technical innovation and the importance of your Tech Stack for Virtual Reality productivity and creativity software. So let’s talk about the speed of light and Godot.
Conclusion at the top to save you time
- Speed of Light - What are the physics / hardware constraints
- Design for the possible, performance is a feature
- Owning your tech stack makes innovation possible
- I suggest using Godot as the seed to grow your tech from
- Ownership comes with responsibility, tools are forever.
Speed of Light Thinking
Something that was super common on the Dreams team and also underpins a lot of decisions on the Modeller team was speed of light thinking. Alex Evans was the one who really got me thinking this way. Long before joining Mm, when I was still in Sony networking division he gave a talk at an internal conference laying out the thinking for a graph database which was single threaded motivated by this article about the cost of multithreaded smart code on cloud hardware vs dumb cache friendly code on an old laptop. Spoiler alert: Computers are fast and the laptop, when not burdened by complexity, could do the graph calculations a lot faster.
I look at this chart a lot, Latency Numbers Every Programmer should know.
This thinking was in a lot of PlayStation which led to a total rewrite of the IO pipe leading the PS5 to disk transfer speeds of 5.5 GB/s. Meaning a cold read of a database of 5 gig or less should take you less than a second. This thinking required looking at what was theoretically possible and breaking down the problem at each level. Thinking in terms of the speed of light.
Likewise there is another great talk from Grace Hopper which I referenced long before Alex introduced me to how fast disk io could be. Why networking is NEVER fast.
You can’t fight physics. Though at the same time computers are STUPID fast and when you re-examine base assumptions using modern data points you can write software which was not possible a decade ago. When Medium was written back in the day it had very tight boundaries. Early days of when Modeller was being concepted Anton looked at the scene graph and wanted to be able to build a tree with each leaf individually modelled. Which works out to about 10,000 leaves. Turns out most scene graphs are horribly slow but if you think about scene graphs from first principles with instancing and counting every bit, then it turns out you can make them blindingly fast.
This speed of light thinking requires you have a technical stack which is capable of being moulded to new concepts.
Edit Notes
Alex was kind enough in this tweet to point me at the original article:
Scalability! But at what COST? by Frank McSherry from 2015. There are some great follow ups as well.
Anton had a correction and more info in this tweet thread. Pasted below for readability.
I had a quick look to see if I can find that article, but no dice :( I'll try again later. What I remember that might help though:
- It was about performance of running social network graph algorithms (the fb one i think) on a laptop vs in the cloud
- I'm pretty sure it hit HN
Also it's "100k things" (leaves, bricks, etc) not 10k :) (and it's ballpark, a quick google reminds me that an average tree has ~200k leaves heh)
I find the "ops per byte" back of the napkin analysis here useful to get "into the ballpark". Assume ~20Gb/sec bandwidth on a typical CPU. Divide by 60 or whatever your fps target. That's how many bytes you can "touch" per frame. Then see if that seems like "enough" for your task
Next, figure out how many "ops per byte" you think you'll need to do. Know how many "ops per byte" you can do on your given CPU/GPU without being slower than memory (on PS4 GPU for example, it's 5 ops per byte iirc). If you're above that, you're cpu bound, below, mem bound.
For the case of moving transforms (ie 100k leaves), it turns out to be slightly cpu bound but not by much. It's about 2-4x vs just touching the mem. You can do experiments to figure this out. So from that, given your individual instance size, you know how many you can do.
It's much more than people expect :)
So if you're doing less than that, you should probably know why (as in, what are you getting in return). Not all apps need to go full rate, but good to be conscious about the choice to "make it easier to code" or "being safer" or whatever.
What about my own engine?
If you have the technical backing and more importantly the runway to create your own tech then that is great. Though I think you would be silly not to build on top of the shoulders of giants. Pull in any MIT or similar licensed tech when you can. Use it, improve it, delete it or rewrite it. The point is you don’t have to do it all day one.
Dreams went through multiple engine rewrites from day 1 to shipping and effectively went 10 years without producing Sony a dime. Modeller was built on top of Medium tech and even then was a large investment from a corporation the size of Adobe to rework and upgrade it.
Do I think small indie teams can compete in the creative/productivity space? Hell yeah! (future article)
Do I think they should build their engine from scratch? FUCK NO!
My suggestion: Use Godot as the technical seed to grow your XR application from.
Godot isn’t... X
Is it Unity or Unreal? No.
Out of the box perf is lower than Unreal and Unity.
There are shiny toys missing and the community, while powerful, is still growing. Tutorials and talent pools are smaller. If you are a 3d game developer with no internal programmer support would I recommend it over other engines? Probably not. Though if you have even one decent coder and you will need that if you are building tools. Then yes it is the right option.
Godot isn't speed of light
Yes I agree because it's general purpose. By design it is make to be approachable and extenable. Juan, a founder, outlines what he believes the pillars of Godot are in this tweet. That base gives the perfect stock car to rip apart and boost up for whatever drag race you specifically need to perform in. Seed thinking.
I don’t want to use GDScript
Well you don’t have to, I know devs that are 100% C++ but honestly it is a really nice speed boost. I would strongly recommend looking into it, working with it and would advise against the C# side. C++ or GDScript are ideal. C++ for core and systems, and GDScript for speed of development and prototyping.
It doesn’t do X?
Well there is likely an addon or plugin that will do it for you if it’s not core render tech say. Also you can build it yourself.
Dedicated XR Engine
This is true it is a general purpose engine but it’s XR implementation is one of the best in a general purpose stack. Also it’s easily exposed to be improved for future applications. Though I do want to be clear, dedicated XR tech stacks are the future. Again a future article. Though Godot is a great seed to build yours from.
It is unknown
Honestly the biggest hurdle is funding, and talent pool wise at the moment. I get it, but this is a temporary problem which is getting solved. I remember the shift when funders used to value internal tech, then the shift as they saw it as a risk. The pressure to abandon internal tech for middleware and now recently the business risk of being exposed to middleware. This will change, investors are getting more familiar with Godot and its position in the market.
What is Godot!
There are other options but at this point Godot 4.3, congrats to all on the release, is a robust MIT licensed engine written in clean C++ with a Vulkan renderer which runs on Quest and PCVR with strong support for a variety of features like multi window which app devs need that game devs don’t often support well.
It is not the most performant engine but it is easy to break into parts, replace parts and build on. The engine is very easy to understand with readability and re-workability key design features from the team.
Long term I think most productivity or creative tools end up building a lot of their own tech. Be it voxel based, mesh processing, stroke api or even text processing libs. As such you want to build it fast and portable so C++ is an obvious choice here and unlike Unity which has been many small companies goto choice for productivity VR it is FREE and a great seed from which your internal tech grows. Any investment you make into the technology is 100% yours. You may choose to push some of it back into the community but you are under no legal obligation to. That is massive for business.
Also the web side of Godot had a hiccup, too long to discuss but you can read here that they are fixing. Once fixed it is the perfect WebXR basis as well for more accessible situations. Like museum showcases or marketing pushes.
Edit Note: As of 4.3 single threaded option is there but this article is still worth the read about why the problem exsists.

Lots of companies are keeping it secret. Look at the lovely Cozy Blanket.
The only reason we know it’s Godot based is from this tweet
Because again they are under no obligation to share that and I’m pretty sure Uniform is built on it as well.
Godot is hands down the best OpenXR implementation I have seen and because it's all open source it’s really easy to add in support for OpenXR extensions and features not yet shipped. Just last week I added support to the engine for Logitech’s new Mx Ink pen over the course of a lunch break. Honestly take a look at this pen, I want to do a whole another post on creative inputs and this pen is a big part of it.
How to Extend Godot: Addons, Modules and Fork
In many small studios where we maintained our own tech stack the plan went as follows: Fork the internal tech stack, build and hack what we need for the title in development and then at the end of the project, or other milestones like another project due to start, we would examine what could be pulled back into the main branch tech engine.
Additionally sometimes games would cherry pick from each other. This is from an era when porting to new hardware was common, working with other studios' tech stacks was frequent and standardisation was rare. This is a good framework to think around extending Godot for games but tools are forever products.
My personal recommendation is ignore Godot Plugins development unless you're making it for use outside of your studio. Modules are great c++ development method for studio or game specific logic. It builds directly in the engine, and isolates it so that merge pain with Godot development.
The next leap is going from adding to using Godot as a seed. As you head into production fork Godot and take ownership. This means you have to fix all future bugs. You might want to pull in developments from the main branch but if you want to own the tech stack, control regressions and invest in tech then it comes with ownership of the stack and starting to think about the speed of light.
Conclusion
As before I put it up at the top but I will repeat it here.
- Speed of Light - What are the physics / hardware constraints
- Design for the possible, performance is a feature
- Owning your tech stack makes innovation possible
- I suggest using Godot as the seed to grow your tech from
- Ownership comes with responsibility, tools are forever.
Have a banana for your potassium 🍌
Fatigue in VR Productivity and Creativity Applications
Fatigue in VR Productivity and Creativity Applications
As part of my brain dump series on writing creative tools off the back of Substance 3D Modeler and Dreams I want to talk about the state of Virtual Reality for productivity and creativity. So let’s talk about VR fatigue.
Conclusion ; TLDR
- Use VR, you will solve fatigue issues as you find them
- User will be seated, head tilted down with arms at their side
- Passthrough is important, immersion is optional
- You should support
XR_ENVIRONMENT_BLEND_MODE_ALPHA_BLEND - Precision: Controllers. Comfort: Hands
- Most apps should explore One Controller / One Hand as default
- Headless is a great comfort option; advice on how
- Hardware vendors should support
XR_MND_HEADLESS
USE VR EVERYDAY!

Look, you need to have some courage and use VR every single day you are developing it. I’m so tired of VR devs avoiding VR. By far the biggest weakness. If you can’t stomach it why would your users. If you actually spend time in VR you will find the issues and fix them. Dumb, simple but it needs to be said because omg the amount of dusty dev headsets I’ve seen.
Hands down the best solution?
I’m trying to not repeat things said in a million other talks but this one needs retreading.
Your user will be:
- Seated
- Head Tilted Down
- Hands at their side
Yes some users will stand, about as many use a standing desk. Not own one, but actually use it in standing mode. Turns out that wears you out.
Your hands will be down and at your side because lifting your arms takes energy and humans are creatures of optimisation. Unless there is a supporting surface like a desk, which is a valid UX I want to talk about in the future, they are going to have their hands down low. They will want the bulk of their boring work to be done with the most efficient low energy motions possible. This isn’t a game where we pump up their excitement and get them moving. BE LAZY! There is a counterpoint that if you are working on a 3d volume you will have your arms up and in the work area. Also in cases where the user wants a high degree of control they will want big motions. For the same reasons artists draw with their arms, not their wrists.
Head tilted down comes from two factors, the above paragraph about arms and the fact you have a weight torquing your head down. Headset weight is too often discussed and torque and angular momentum are not discussed enough.
Design your UX for these basic realities of what I call the VR worker pose.
Why is Passthrough Critical?
I’m not going to ask you how often you fullscreen a productivity application. Because even when you do I bet you have a second monitor, phone screen close at hand or other distraction. So instead I will ask you how often you IMMERSE yourself into a productivity tool. Yes, sometimes you get into a flow state and are head down in your productivity software but often that is not the reality of creativity or productivity.
So we need a non-immersive default for productivity and creative apps for VR and that means we need passthrough. VR devices may in the future be multiple application devices, Apple sure is building an OS for that reality from today. Their contribution to the space has been vital to waking people up to this reality but honestly I want to give a lot of the credit to Varjo who not only pushed this early on, had Apple as one of their biggest customers, but also set the standard for HOW TODO PASSTHROUGH.
Meta early on released the XR_FB_passthrough as a solution for passthrough. This extension became popular and was adopted by Pico and HTC as they all used similar chipsets. This was the wrong solution because it was built under the assumption the application controls the passthrough and would have access to the camera feed. This was a huge problem for PCVR via streaming, the most common use case for PCVR with Quest, Pico and HTC. As the camera data was sent through the system, the PC-based compositor ended up working with a delayed camera image. I understand some not all the legacy decisions behind this thinking applications would do more with mixed reality.
APPLICATIONS DON’T CARE ABOUT YOUR DESKTOP!
Neither should your passthrough. I will put spatial anchors and some other cool tech to the side for now. That is a whole separate article. The solution was what Varjo did instead, XR_ENVIRONMENT_BLEND_MODE_ALPHA_BLEND.

Unlike the default opaque, or the additive mode designed for wave optics displays this allows our application to send a framebuffer with alpha. This means the headset can display passthrough cameras, virtual environments or other applications. We don’t care. And when a user wants to focus on our applications we can just render as much as we need and no more.
This is the golden secret for productivity applications and something I’ve pushed in every Vendor meeting for 3+ years. Finally progress is being made but this is a big shift.
Doing it one handed?
You need to ask:
- Do I need precision control?
- Do I need precision control on both hands?
Most productivity and creativity applications need precision control, but almost none need it with both hands. There are exceptions like some apps that don't need precision.
Precision Two Handed - Default with two controllers
Lower precision - Hand tracking
Hand tracking is great because no batteries, you can drink your coffee and it is one less thing to worry about. But the truth is most applications need precision in one hand. Well Meta have been working on a solution called Multi Modal. OpenXR extension outlined here in Meta docs.

This is fantastic and gives you not only the freedom to work with a dominant hand while using the other to do real world interactions, assuming you have passthrough, but also unlocks a secret power. Hands have a MUCH larger vocab than any controller could hope to unlock. This gives you a huge menu of shortcuts should you wish to unlock them.
A bit of creativity here could really remove 2-3 click deep menus and provide detailed shortcuts for a range of actions.
Going Headless!
The final mega upgrade. Look, I believe in VR and I think it has a bright future. I have a saying I will repeat here. VR is the most uncomfortable it will ever be today. Year by year and cycle by cycle it will improve. That said there is a dirty secret, a large reason why most productivity and creativity apps excel in VR way beyond their flat rivals when done well is due to the controllers. VR six degrees of freedom controllers are magic.
I still think for most users the Dreams TV + Move Controllers experience is the ideal experience most of the time. Do I think it gets better when you put on a headset? Yes. Is the improvement bigger than the inconvenience of the headset? Maybe.
The answer used to be no but headsets have improved. That being said, we need to stop ignoring this use case. This should be supported using the extension, XR_MND_HEADLESS. Pico and SteamVR have support for it but this is slightly bugged. I fought this fight for a while but there wasn’t much vendor interest in solving this because it’s against their commercial narrative. Modeler now has a fake headless mode where we don’t use the extension but don’t send any frames to render to the headset.
This works quite well but it often requires the user to shove a t-shirt or similar in the headset and point it at the controller volume. Unless you have an option to disable the presence sensor and power saving stuff. Less than ideal but it works.
You will need an easy to use shortcut the user can frequently press to reset to the rest position. As now the headset is detached from the user. I ended up using double stick click but honestly the mode never got the love it deserved. If you want to see it done well load up Dreams with the Move controllers.
There are 3D TV displays. Also lighthouse based tracking should be ideal for this. You can level this up with a small tracker on the head or using a webcam for facial tracking ala this old Wii Demo, no 3D TV required.
The point is we are only one decent HW vendor or creative OpenXR runtime implementation away from proper support for this completely valid use case. Hell the Quest Pro controllers track themselves and there was this interesting reference design from Intel not long ago I believe. Also a few interesting monitors at AWE and CES so who knows what the future holds. I just hope they build on OpenXR, because if you do the difference between supporting Monitor + VR controllers and VR is smaller than most people realise for productivity applications.
Conclusion is at the top
Thanks for reading. Have a 🍪
Why leave an awesome team in Adobe Substance Modeller?
Why leave an awesome team in Adobe Substance Modeller?
August 2nd was my last day on Adobe Substance 3D Modeller.
There is an FREE Open Beta and you should go try it: Open Beta
Why? I’m starting an indie VR game dev studio. Could not be more excited!
I can’t talk much about that yet BUT after working on PlayStation Dreams and then Modeller I think my time working on creative tools is at an end and I want to brain dump before this stuff fades from memory. So I’m going to write a series of weekly articles to share some learnings and thoughts as I forget a lot as my brain moves on.
Nothing here has been approved by Adobe and only the first article will mention some public Adobe stuff for context, but this is a generic learning series to unload some knowledge from doing Senior Online Consultant gig at Sony then Dreams and finally being primary OpenXR/AI person on Modeller.
Why Leave?
TLDR; I love making games and I’m not built for corporate long term products.
The thing I love about working in a creative field which is project based everything is about the launch. Showtime the time you step on stage. Then there are maybe some DLC or other bits but you have a season and then you move on. Yes sometimes seasons overlap as you look for the new thing while the old thing wraps but your life has a cadence. This was great for launching and early days of Modeller but now I’m the wrong person in the wrong place.
I want to be clear, Modeller is the best tool to make primary and secondary forms or models in my opinion. Is it as powerful as Dreams, yes and no. It is more focused and does less but is built for a professional audience. Also its newer Dreams took 10 years to make. Modeller while built on top of Medium is mostly a new product with a new direction and is still relatively new. It takes a long time to build up a 3d modelling software.
What did you do?
Initially I had to pick up a lot of VR UX work with our original ui system which was hand built. That system is no longer in place as there was a huge rewrite to a very cool system. But that initial iteration on our original system let us rework a lot of concepts and nail down the structure so the rewrite had a hard target to aim for.
The biggest thing I am most proud of is being the OpenXR expert on the team. Porting the tech from OculusVR onto OpenXR because I wanted it to run on every headset it could. Also it was a great chance to work directly with hardware providers. I went from being a passionate amateur of OpenXR with deep knowledge of early VR and console VR to becoming one of the few people who has written and deployed a widely used OpenXR application. Something I want to talk about because not enough people engage with what has become the modern base layer of VR instead hiding it behind a game engine.

Cool to see Md shouted out at Siggraph as one of the OpenXR implementations. Big win.
Finally working with the London Lab folks on various AI projects has been really interesting. I want to write up some stuff that is public domain and my thoughts on that. Honestly though most of the cool stuff isn’t public, it's a hot topic and I don’t want a lawyer/assassin in my house. Just know cool people are working on things, the research is interesting and I’m excited for the future and believe enough people of good integrity will speak their mind internally. Good vibes.
What do you think of the future?
Without breaking any NDA I will say I am excited.
The challenge is they are building an innovative new product inside a big company. Adobe in recent years has acquired more than it has built and I hope with the failure to acquire Figma they learn how to build, support and market new products. Substance clearly knows how to do this and all the Substance talent is still there so I’m confident they will figure it out. But that is the only real concern I have.
The team is very skilled and the product is full with potential. I’m obviously bias to the VR side of things but I believe the real value of the product is unlocked through the VR controllers.
The introduction of non destructive edits like Dreams is a big deal which is a really exciting addition. You can see Joshua showing them off here. Substance 3D Modeler - Boba Tea Tank
The product has seen a lot of love recently and I’m excited for the VR future.
When to go C++ in Godot
When to go C++ in Godot
I'm working on a VR game in Godot 4.x and well it has been long since that I admitted I would need to hack open the engine and make changes. I am trying to keep that to a minimum I talk about that about why the last game was shelved in this video. Now as progress on the new game is going well I want to talk about -two things- when you should C++.
Problem: Cut a mesh in VR very fast
GDSCript is Great
It's fast, you can live edit it and well when speed of iteration is king it is hard to beat a domain specific scripting language. Though that is all it is a scripting language. That is not a bad thing and one of my favourite things about GDScript is it doesn't try to overreach. So many game enginges I've worked on get really over complicated when really a bit of YAML or LUA would serve 99% of their needs. So that golden rule for me is, build it in gdscript first whenever possible. So I start out by building a simple slicer using ArrayMesh in GDScript.
Why not use generic addon ect...
VR needs speed and general purpose mesh processing algos are really slow and have a tendency to get linear fast, which means it is hard to avoid frame hitches. 99/100 if your doing realtime mesh processing in a game you haven't spoken to your tech artist enough. Smoke and mirrors baby! Also only solving the problems you to is a huge boost.
Fake the cut then delay the processing across several frames
- Not going to split the rigid body till the moment of the cut completion
- The cut is likely to occur over multiple frames
- Minimal change of graphics buffers
So the MVP is we need to...
- Take a mesh and a cut plane
- Determine if you are either side of the plane. Simple dot product per vert
- Show the cut in progress without changing the mesh
- Then write a mesh slicer that is possible to split over multiple frames and does minimal IO
Another thing is the set of preconditions
- We can preprocess the mesh to be easy to cut (avoid long triangles for example)
- We can use gameplay effects to slow the cut down
- We can hide the moment of the cut with visual feedback on top
What can't we do in GDScript
Honestly nothing in that list, we good then the question is what should we do in gdscript. Looking at the docs for array mesh and the functions offered by the Render Server I noticed a few things. Any mesh processing or buffer management will be a lot more complex, indirect and hard to optimise in GDScript. This is because many functions are wrapped through layers of indirection which would be hard for compilers to optimised. Now if I wasn't working on a VR game where every drop of perf mattered this wouldn't be a huge issue, but it is for me. Another thing though is...
Scripting is aweful for Cache
Writing code which is very robust to processing large chunks of data with minimal wasteage mostly comes down to caring about IO and cache friendly operations. People will often talk about Big O optimisation or some fancy way of making the code "cleaner" but the reality is the compiler needs to scan a bunch of data from one place, make a transformation using a small set of instructions on a tiny worktable (CPU/GPU registers). It has some shelves by the table it can each to, or turn around and reach which can hold a bit more (Cache). But every time the computer needs to walk away from that worktable to fetch something from another room like hard drive or ram, or worse go talk to the neighbour or drive to another city over a network connection things slow waaaaaaaay down.
So often doing more work that involves less moving about is faster than doing less work. Think about this like sorting the puzzle pieces before doing a jigsaw or sorting out the bits of pieces from a model kit, cutting all the sprus while having the cutters in your hand. So sometimes scanning through data and working on it as you come across it, even if it means scanning the data twice or three times is faster. These deep coding problems are when you should be reaching for C++.
Additionally looking at the scripting API for GDScript, rendering server and its multiple backend support for Vulkan and other renderers because I know I'm only on Vulkan I can make things work directly with that. And the calls which are exposed to scripting are often done so in a friendly easy to process way for human devs rather than what is nice for the computer.
Final Solution
I'm still optimising and cleaning up the solution but currently here is the process
Shader is given uniform cutplane data for current cut
- Cut effect is done in shader
- Updated by gdscript to keep iteration fast
- Only one cut at a time, assumed to be plane
- Avoids any IO except setting shader param (very small)
C++ Module for Mesh Cutting
- Given Cut point, normal, direction
- Encode UV2 to store dist from plane and relative 1D position in the cut
- Iterate any faces which are split by the cut plane
- Generate two new vertices slightly apart from the cut plane, quantise them into int grid
- Merge any cut vertices in same grid point
- Define new faces in direction of the cut plane using grid surf gen
- Define two surfaces using the same underlying buffers to minimise GPU IO
- Each surface uses unique index buffer
- Directly update buffers
Wrap that C++ function in a custom module which is callable from GDScript.
Conclusion
I hope that is useful for some people I'm happy to talk more specifics if people are interested just drop me a line on masto: @kimau@mastodon.gamedev.place or twitter: @EvilKimau
Wildsea Campaign
Wildsea Campaign
So recently I closed off my Second Moon DnD campaign after two and half years. Which was great and honestly give me a wonderful sense of completion.
That being said I'm also really excited to dig into non-DnD systems again. On the table we discussed Heart, Scum and Villany and Wildsea. Obviously by the title you know we selected Wildsea. Once again I'm using my own wiki golang code to run and manage the campaign through a web interface.
One thing I built while doing this was a character sheet which converts markdown into character sheets and I thought some people might enjoy it.
Access it here.
I also made a ship sheet.
Hopefully that is handy for some folks. I will be updating it as the campaign goes on with new features ect...
Dice Rolls in Table Top
Dice Rolls in Table Top
I've been thinking a lot lately about dice rolls as I consider reviving my old Channels of Power ttrpg and doing a v2.0 and launching some new campaigns and modules but this got me thinking about my old friend, dice probability.
The classic d20 is a flat probability curve with a BROAD range with small bonus meaning that the curves are wild.
You ALWAYS have a 5% chance of guaranteed success or failure. No dice risk is without hope or dread. This leads to a very cinematic feel with a level 1 character still having a chance of hitting a big bad monster. The wildness of the dice is countered by rolling a lot of dice rolls. So the Dungeons and Dragons system tends traditionally to LARGE amount of dice rolls. The more dice rolls in a game the more the fairness or power scale levels out.
Also notice how huge the advantage and disadvantage system are in Dungeons and Dragons 5th edition. This replacement of situational bonus was a huge improvement. You don't really feel a +2 the same way as you feel disadvantage or advantage. So this becomes a key flavour mechanic for Dungeon Masters.

Now my preferred story telling game is Fate which uses fudge dice. Roll 4d6 where [1,2] is failure (-1), [3,4] is neutral (0) and [5,6] is succes (+1). This is made simple by dice with minus, blank and plus sides and really is 4d3 roll. This is simple because you always roll the same number of dice and the swing trends towards a strong normal. So very few dice rolls still feel fair and infrequent rolls can be made to be pivotal.
Both are solid and strongly flavoured systems but my original v1 of Channels of Power was based on the classic White Wolf style dice. Roll the number of d10 equal to your skill and any dice equal or higher than your target number is a success (+1) with the default target being 6. A controversial but awesome addition to this flavour of dice system is the exploding 10. When you roll the highest possible value it is a success then you reroll for more chances to succeed. This in theory leads to an infinte ceiling.
I'm also a huge fan of success based dice systems as they avoid the secondary damage roll. Wrapping up everything into a single roll feels more dynamic, faster paced and is often simplier to newer players. Especially with DnD wargaming inspired range of damage dice.
You will see that immediately the exploding doesn't actually shift the numbers much, except on the very low end. Though I will say exploding dice feel very cool. I've often seen the house rule is that the Story Teller running the game does not explode but the players do. This feels great for players and avoids the random situation of runaway failure for the ST rolls which are enviromental and atongonistic.
I know a lot of Vampire, Werewolf, Mage ect... players who just love their tubes of d10s and the joy of exploding madness. Though many other table tops use the same system but with the much more ordinary d6 dice, often thought of as the normal dice as it rolls well and is the most common dice seen outside of tabletop games. So how does a d6 target system fare?
As you can see the chances with a d6 vs a d10 aren't that different. So I think the difference between d10 and d6 are largely thematic. The difference being mostly in how the fumble and explode are handled. The d10 are slightly lower rolls but the players don't really FEEL it. Though the novelty of d10 is often cited as a reason to use them over d6. It puts the players in a different headspace and collecting tubes of d10s is often more fun than d6s. Though by the same token it does make it slightly more intimidating for newer players.
The next question which comes up is often around shifting the target numbers. So making things harder or easier by the ST setting a target number lower or higher than the average. I always liked this as the player rolls the same number of dice, which if you are really expert at a thing the feeling of rolling a lot of dice is epic, but it gives the ST a strong knob to turn which affects the high rollers more than the low rollers.
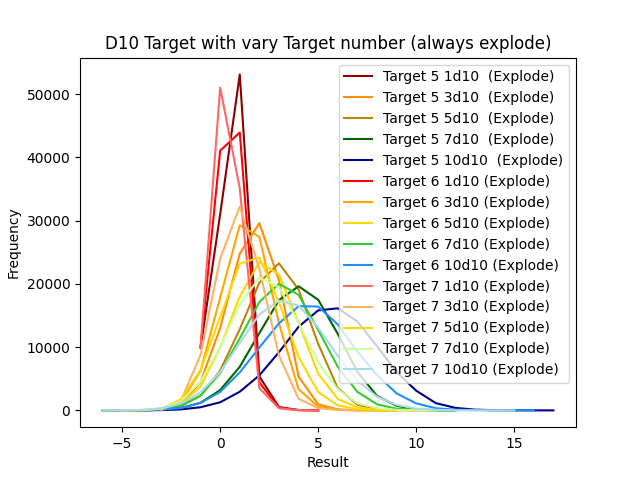
Now this is often cited as a key reason to use d10s over d6s and while I can see the benefit I found often ST didn't adjust much more than a higer or lower roll. Let me show you what it looks like if we use d6 instead.
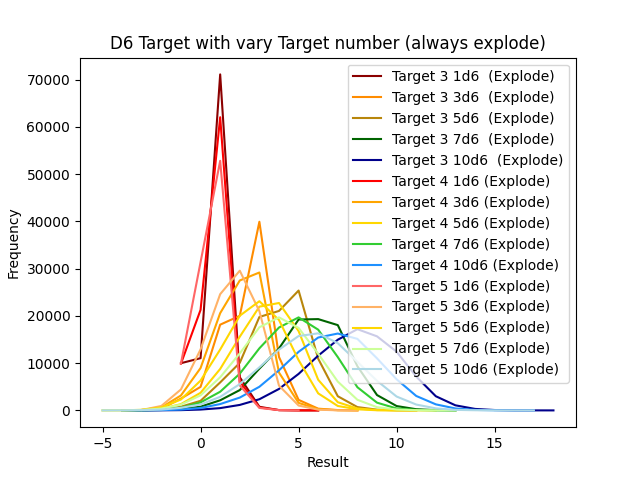
A nice subtle tuning mechanic but without the oomph of the D20 advantage and disadvantage system.
It can be a bit harder to intuit the sense of these target numbers so I've given you a small toy below to play with the system. The rainbow of colours showing the difference between rolling a single dice all the way up to 10 die. You can see that a bigger dice pool mostly makes the roll more reliable by flattening the curve.
The biggest change between 20 years ago when I designed the first version and now is my years of experience in game design, have taught me the most important aspect isn't the mathematics behind it. Rather how the dice mechanics feel during gameplay. Over time, I've encountered a variety of unique dice systems, each with their own interesting features.
Poker dice, fixed pools, pairs and set, target dice and all sorts of strange combos.
However, let me delve into one more concept: the use of target numbers, particularly with the introduction of 'advantage' or 'disadvantage' in the fifth edition. Consider a scenario where you roll multiple dice but only count the highest roll against a predetermined difficulty level (DC).
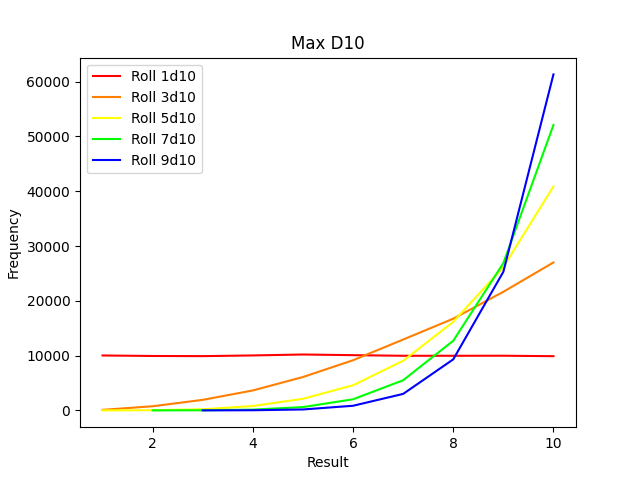
This is actually really simple and nice but it quickly gives diminishing returns on the high end. Which is not always a bad thing but might flatten the power curves more than some games which focus on getting really good at one thing could want. Though it is appealing if the damage is say the amount you beat the target by then the high end of the dice pool is interesting.
If you want to explore that idea further and stretch the power curve: What if you sum the TWO biggest dice?
Then you get this curve...
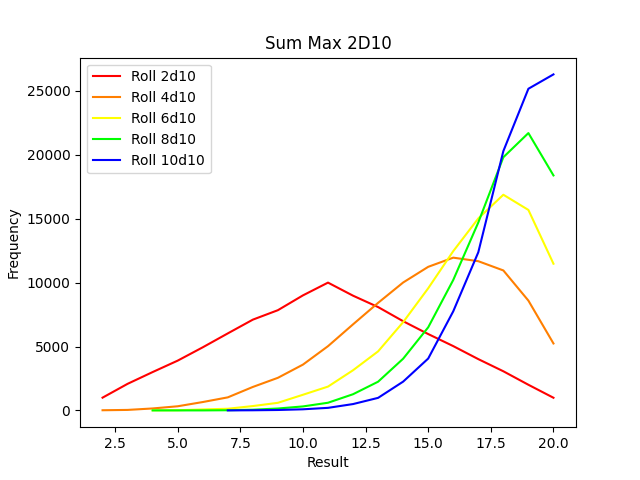
See that provides a lot more room at the top end. The introduction of a rule around 1s and 10s for stress, flair or explosion is of course interesting as well. I have a bunch more thoughts but I wanted to conclude this blog post on dice proabilities with that simple sum max system as I call it.
Please let me know your thoughts on Twitter (@evilkimau) or Mastodon (@kimau@mastodon.gamedev.place)
Footnote on Probability Curves
All of these are run through a simple python script to just roll dice and add up the result. You can grab the code here. While calculating the something like advantage on d20 roll is P(highest 𝕥) = P(first_die 𝕥) × P(second_die ≤ 𝕥) + P(second_die 𝕥) × P(first_die < 𝕥) + P(both_dice 𝕥)
while disadvantage is P(lowest 𝕥) = P(first_die 𝕥) × P(second_die ≥ 𝕥) + P(second_die 𝕥) × P(first_die > 𝕥) + P(both_dice 𝕥) isn't that hard it becomes a mess with exploding dice. Also I found it quicker to iterate in code than math.
Btw for d20 that is
Advantage: =(1/20)*((21-Target)/20+(20-Target)/20)+(1/20)^2
Disadvantage: =(1/20)*((Target/20)+(Target-1)/20)+(1/20)^2
Roleplaying in Sunny Hunny
Roleplaying in Sunny Hunny

Are you ready for an adventure? Last week, I returned to the world of roleplaying for the first time in years. I journeyed to Con-tingency, an epic event held at Searles Leisure Resort in Hunstanton from 18th to 22nd January 2023. With three slots of four hours each, I delved into a diverse variety of roleplaying games, board games, and all-around fun. This event is the spiritual successor to Conception, an event that holds a special place in my heart. As an experienced roleplayer, with nearly 30 years of experience and a history of writing and running convention modules for over 20 years, it was strange to have not attended a con in so long. But Con-tingency presented the perfect opportunity for me to see the changes in the hobby without the gradual shift of seasons. Are you curious what has changed? Join me as I explore the world of roleplaying at Con-tingency.
Headline is Con-tingency provides a faithful successor to Conception.
I want to focus on the games and talk about game design more than the event.
Played
- Rest in Pieces: Renting from Death Comedy (Story gen + Jenga)
- Getting Away with Murder: Murder Mystery (Card story gen)
- Magical School Girl (Mid-System)
- Goblin vs Smurfs Comedy (Freeform)
Hosted (Ran)
- 17th century Occult Horror (Call of Cthulhu x2)
- Goblins build killer robots (Freeform x2)
- Scooby Doo meets GhostBusters (Fate)
- Sex Worker Aliens Adult Comedy (Fate Accelerated)
Glancing around the hall and talking to people, the big change was obvious. The hobby has exploded and demographics changed but the con hasn’t yet. The attendees used to represent the hobby but now they skew older and less diverse, as the hobby has exploded. The last time Conception ran was before 5th edition, I was streaming on Twitch but Critical Role had not started and table play was mostly in podcasting format and very niche. The dominant media being story recaps, Wizards had shot themselves in the foot with 4th edition and Pathfinder was enjoying a huge rise in popularity. World of Warcraft was still dominant and Minecraft had just started blowing up.
Con-tingency offered a diverse range of games, moving away from traditional staples such as Dungeons and Dragons and Pathfinder. The event showcased new and innovative games, providing a glimpse into future years. The demographic of attendees may be older but the gaming trends on display were varied and exciting.

Kickstarter games like Rest in Pieces, which combines story generation with a custom Jenga set, are introducing new and unique elements to the hobby. Beautifully made and presented, the game offers a mix of storytelling and skill-based gameplay. While I have some issues using Jenga as skilled players can dominate play. I play Jenga like I manage my mental health, a disastrous expert on the brink of collapse masterfully delaying burnout. The game is novel and engaging enough to be a worthwhile experience, and it is an example of the kind of innovative games that are now available in the hobby.
Goblin-themed games, like the ones I played and ran, have had a good run, much like bacon culture. They've been popular for a while, but it seems that their popularity may be on the decline. While they can still be fun and enjoyable, it may be time for the genre to evolve and explore new themes. I added a doodle mechanic to mine I quite enjoyed. The game I played had some innovative features, like novel name generation and skill stack popping, but it may be worth considering new ways to approach the goblin genre in order to keep it fresh and exciting. That being said, like bacon, going goblin mode will always be a tasty treat, and fun was had by all.
When it comes to roleplaying games, pacing, relationships, and character development are crucial elements that can make or break the experience. As someone who grew up in the South African con scene, which had a strong emphasis on writing, I may be biassed towards the importance of well-written characters that players can connect with and how it can impact the pacing and relationships in the game. When it comes to character generation, it should be fast-paced, engaging and lightweight to keep the game moving. While it may be challenging, creating well-developed characters and relationships is crucial to enhance the player's experience. So, when running a game, especially within a four-hour slot, take the time to consider whether player-generated characters or pre-written characters are more suitable. Four hours is a short slot, don’t make it shorter with character generation.
After years of not writing new modules, I was excited to try my hand at creating a 17th century Call of Cthulhu horror game, inspired by the start of the Baroque Cycle by Neal Stephenson. The game followed artists who retreated to the countryside to escape the plague, only to encounter occult occurrences. I was shocked to see the 7th edition Call of Cthulhu has made the biggest changes to my beloved horror system in years. I am assured they are good changes so I need to sit down and upgrade my old modules. Despite some challenges during playtesting and difficulty in refining the concept, players had fun with the game. However, I ultimately decided to shelve it and move on to new projects. The core characters and theme were not well suited to module occult play. Despite this, it was encouraging to see that the classic horror genre remains popular and largely unchanged.
I had the pleasure of playing my friend's latest creation, a gm-less murder mystery card game called "Getting Away with Murder." The game is inspired by the beloved roleplaying game Fiasco and features strong writing on the cards to generate an engaging story. As a friend of the creator, it can be difficult to provide an unbiased review, but I can confidently recommend it to fans of story games, improv, and Fiasco. The card mechanics in this game are incredibly strong and I believe we will be seeing more of this style of game in the future. If you're looking for a new and exciting way to play Fiasco or story games, be sure to check out https://gawm.link/ - I promise you won't be disappointed.

As we bid farewell to Con-tingency, I can't help but reflect on the exciting new trends in the roleplaying game hobby. Diceless systems, such as card-based mechanics and Jenga, offer a refreshing change of pace from the traditional use of dice. While we dice goblins will always have a fondness for the unpredictability and tactile nature of dice, it's important to explore new ways of generating random outcomes in our games. I am eager to see more diversity in the hobby, not just for the sake of change, but for the benefit of new players. With new inspiration and renewed passion, I can't wait to return to the convention circuit, crafting new modules, and experiencing the thrill of the roll. I leave Con-tingency with a smile and the excitement of what's to come.
Experimenting with Midjourney
Experimenting with Midjourney
Loving this idea of using Midjourney to document Dungeons and Dragons sessions.
There is an issue with consistency and certain fantasy races but overall it really captures the feel of the sessions and the progress.
It's great to see the session laid out visually.
 Brigadier's New Armor
Brigadier's New Armor
 Kelly rallies the camp
Kelly rallies the camp
 Public Whipping
Public Whipping
 Feast to celebrate
Feast to celebrate
 Dissection of Chiwi Chiwi
Dissection of Chiwi Chiwi
 Problems with Portal
Problems with Portal
 Camp watches Explosions
Camp watches Explosions
 Arguments in the Tent
Arguments in the Tent
 Forest Ambush
Forest Ambush
 Laura makes a Friend
Laura makes a Friend
 Max talks to the Pit
Max talks to the Pit
Second Moon
Second Moon
I've been running a DnD games again. I am enjoying it so far. It is good to be rolling dice in person again. The campaign is actually running across multiple groups. Some of which are at the London DnD Meetup.
So I've decided to publish some of the notes on my webpage to make it easier for players to reference stuff and intro players.
Second Moon Notes
Also, I made a fun video of the setting introduction here.
Pickle on the Nightmare Wall - Part 7
Pickle on the Nightmare Wall - Part 7
Can You Breathe
The air lay heavy with anticipation, the high sun casting shadows in sharp relief on the edge of the treeline. Pickle could easily pick out the twisted shape impaled with the javelin she had shot moments before. The corpse was bubbling and fuming with acrid black smoke. Now it appeared to be melting around the shaft, sliding down slowly. The screams had lasted less than a second, though they had seemed to hang in the air for longer. The corpse had twitched for a short while. The smoke now was just continuing to grow in intensity, the corpse long since stilled.
Gunther had taken in the situation and was now giving clipped orders in a calm collected tone. Not barking or shouting, and frankly, the rooftop watchtower was now quiet as a church. A silent wake. He told the Ball twins to spin down the turrets and everyone to go dark but stay ready. For a moment, she wondered if red and ready were related. Gas, tension and chem weapons were brought out and checked. The spin weapons could be turned on relatively quickly, though the seconds for them to spin up could be their death. Right now, this was about managing the emissions, hoping the ripples would calm and deescalate back to the still pond of the routine she had grown used to.
This all registered dimly in Pickle's mind as her memories drifted into darker places. She watched the burning baby dragon corpse smoke with billows of black smoke. The guts and internals of the creature seemed to react with the ironclad javelin. Not a mild peanut allergy. More like a violent chemical reaction, the closest point of reference that Pickle's mind could conjure was the expensive cocktails, some chemical, others magic, occasionally served in the club. The stylishly dressed server dropping an overpriced cube of ice or magic charm into the beverage producing smoke, rainbow colour changes or full illusions to spring up from the liquid on contact. Though in truth, the foul black smoke reminded her of burning rubber. Her mind flashed to a darker and earlier memory.
The smoke stuck to the trees and stained them with a heaviness, making leaves limp. How could smoke, air, be heavy and still float up? Black particulate staining the world. Her mind searched for a connection. These days grav vehicles dominate the southern continent, with the main arteries of travel being rail. The efficiency of rail and the power of the metal tracks in this world of magic and low taxation were the easier to maintain options, typically over roads. Almost all wheeled vehicles were electric or drawn by magical beasts. Liquid fueling stations were speciality depos far and few between, not roadside repetitions. Anyone who wished to maintain the archaic and dangerous chem engines did so as prestige items. Still, you did see wheeled vehicles on occasion. High-end corporate variants might have articulating smart wheels or some other modern alternative. Rubber tires were still used in places and common in scrap heaps.
Looking at the smoking corpse, her mind flashed back to that day that Jack Jack and the boys had necklaced a rival gang leader. The practice was cruel and old involving flammable liquid, wearing a tire as a necklace and usually staking the person down. It had been popular in this part of the world once with freedom fighters and terrorists alike. Jack Jack boys had just used long sticks, spears almost, in a circle to keep the rival leader pinned in as he screamed and howled, it had been for much longer than the beasts' short shrieks, but they were now in her head again. The globules of melting black burning flesh on contact. The smell and clinging black smoke that stained the landscape came back into her mind as she saw the smoke billow.
Rough hands shook her. The world rocked, and then a slap ran out. Pain rising in her cheek. This was not a light tap on the cheek with a loose wrist but a forceful wallop literally knocking sense back in her. Pickle felt her brain rattle as she looked around and saw Gunther's eyes locked with hers.
"You good?" His question was urgent.
She nodded on reflex, feeling the memories retreat.
Sarah was now at the ballista in Pickle's place. Pickle was sitting on the floor of the watchtower, dazed. The Ball twins had spun down the turrets, as ordered, and now were sighting down two gas rifles, both single-shot long-range weapons. Gunther looked at Pickle intently, evaluating some hidden math from which he did not like the sum.
"You did good, the Wyvern is dead. It needed killing fast. Hopefully, we can deal with the fallout without this going hot. Every minute we can avoid killing or making a fuss, we are more likely to survive. Go join Leon and Ka on roof walk. Can't have too many on the tower."
With that, Gunther directed her to the wooden steps leading down to the roof. She grabbed her spin rifle and checked her gas revolver. She walked down the steps and watched Gunther joining Sarah by the ballista, mounting his large chem rifle on the railing. Walking down the steps, she saw Ka on the east side and Leon on the west side of the tower. Both were walking back and forth on the roof edge taking stock of the area down below. Not knowing exactly where to go, she went to Leon. He raised a friendly hand in greeting.
"Nice shot Pickle, it was a clean kill."
"Thanks. Where do you want me?"
"Walk with me for a bit. You can use your cap gun to support me until we go hot. Then spin up your rifle."
She briefly swung the rifle off her back and checked it once over before securing it on her back again. No spin rifles yet. She quickly checked her gas revolver and spun the barrel to inspect the caps. Thinking how little it would do to the baby Wyvern. The large dog-sized creature had thick scales. She was pretty confident it would kill a Wisp Cat or maybe even a Six Stalk.
"Don't worry, Wyvern don't normally stay close to their parents at that age." Leon seemed to mistake the point of Pickle's worried gun inspection. He pointed his rifle over the tree line. "Truth be told, that don't normally come this close to the line."
The smoke was now dying down from the corpse as everyone started to feel a bit more relaxed. Gone from billowing to a smouldering wisp. Maybe a minute after the first creatures they sighted were Pebbles. She had seen the little scavengers before and had been instructed not to shoot. Little bits of stone or wood crawled over the corpse. The climbing movement of the Pebbles was somewhere between the smooth motions of spiders and the linear scuttling of crabs. It depended on the little hermit creatures tiny white bodies and how they fit into their unique shell. Now they scrambled over the sight, picking at it.
They were carrion.
"Lekker, the little buggers will clean up the mess and leave the javelin well alone." Leon laughed.
"Leon why..." her question went unasked as a rough roar came from the nearby tree cover. More bark than roar. Leon dropped smoothly to a knee, taking aim. She followed him down with less grace using his aim to pinpoint the source.
"White Cats," Leon said in a severe low voice. "Only take the shot if you are certain. Body never head, not with that pea shooter."
Before she could ask for more, she saw the Pebbles had scattered from the sound. Washed away almost instantly into hiding. Though stationary, they were practically impossible to see. From the edge of the tree line, three shapes emerged. They were on all fours, cat-like, with long swishing tails. These tails were solid matter, thankfully, with maroon fur covering the body. Most disturbing was the dark brown, almost black bone growing out of their face. It was like their skulls had bubbled out. The bare white bones stained dark. Their eyes were set forward, the eyes of a hunter, small sunken dots in bone bowls. The bone flared on the edges, whiskers of bone matted together.
Not three shapes, five big cats. She couldn't believe she had almost missed the two larger animals as one jumped down from a tree branch. The dark bone had hidden it in the shadows proving a ballistic frontal shield as well as camouflage. They circled the corpse before sniffing the air. Leon adjusted his sight. Pickle pulled out her revolver. She wasn't confident at this distance on a moving target. She would wait.
Just as the creature seemed to catch a scent of something it liked and lowered its head to roar, its head exploded. Then all hell broke loose. Another cat flew to the side as its side exploded in a bloody fountain. Large javelin bolt narrowly dodged by the third cat. Some smaller bolts hit a fourth, wounding but not killing it. The fifth cat, one of two she had failed to see at first, was now charging towards them.
"Yours." Leon calmly ordered while keeping his aim on the charging cat.
Pickle fired. The first shot pinged off the creature's skull, staggering the cat but not stopping it. The creature had about 70 meters to cover, and at the rate it was running, it would be on them in under ten seconds. Her second shot missed, shooting high. Standing up, she aimed her third shot just over the skull, aiming for its rear. The bullet hit. The cat stumbled and fell forward into the dirt just shy of the red line. She quickly fired two more shots into the exposed chest of the creature. It jerked in pain at the first shot but fell still with the second.
"Reload."
Leon hadn't even looked up at her as he quietly gave the order to reload. She popped the drum, dropped the five spent caps onto the floor to collect later while holding her thumb over the unspent three left. Not wanting to touch the hot caps. They didn't get nearly as hot as chem rounds, but you could singe yourself on spent caps.
Pickle reached into her pouch to retrieve a few unspent caps and thumbed them into the empty chambers. She looked at Leon and then the horizon before asking the obvious question.
"What were those things?"
"White Cats, travel in packs. Hunters, so unless we get fokken unlucky, then sure, they are the last. Most things this far south will travel a far distance to keep out the way of White Cats. Just need to keep things quiet until the coast is clear. Not attract anything more."
Waiting for the other shoe to drop. Pickled looked over everything, evaluating the battlefield, the corpses of the five white cats. She was sure that the first exploded after being executed with a chem round from Gunther's rifle. None would have pre-empted his command except maybe Malcolm. Sarah had fired the Javelin, which had been dodged, but she saw now the corpse had bullet holes. She hadn't heard another gunshot from a chem rifle, so she assumed the Ball twins had finished that one with their cap rifles. Gas made noise, but it was easy to miss in the chaos. Then the bolts from Ka'Shek's crossbox had made short work of the fourth. Finally leaving her to kill, she wondered at what point Leon would have taken the shot. Before or after the creature had crossed into the minefield?
Flicking the gas revolver, so the drum locked back into place, she checked its action before looking over to Leon, who seemed transfixed with his arm hairs. Now standing on end. He looked at her, mouthing a single word. Spin. Leon looked up at the tower and shouted it.
"Spin!"
Moments later, the turrets started spinning up, and Gunther called back down, asking for a direction. Leon had his scope back up to his eye searching, responding he had no idea. All the while, she swung the spin rifle off her back and spun it up. She felt the tug as the spin drive engaged the flywheel drums inside, and the gun grew sticky in its motion. Like moving a large stick in water, the rifle pulled as she tried to focus on what Leon was looking at. Ka was the first to spot it. Bolts flew from his crossbox in a flurry as he emptied the entire box in one volley. They watched as some of the wooden bolts missed and pegged deep into the dry ground. While others shattered on the tan brown scales of a giant serpent.
The beast was a fat snake with overlapping tan scales. Perhaps it was as thick as one of the high-pressure cylinders or Ka'Sheks beefy thighs though it was as long as maybe ten meters in length. The creatures hadn't fully emerged from the treeline. Its slithering motion was the oscillating creature pushing up little ripples in the ground. Its head is a flattish triangle.
The wall erupted as everyone let loose the full power of spin turrets and rifles backed by two loud gunshots from chem rifles and the large javelin. It was madness to watch all aiming for slightly different marks. The explosion of misses was at first confusing. Unlike Ka's bolts which had mostly found their mark but had been too weak to break through, none of the ironclad or tipped bolts hit their mark. The effect was underlined by the only wound being from the large javelin, which seemed to have only been deflected slightly due to its size, and it grazed the beast. Some scales flew off, and a nasty gash appeared on the serpent's side. A significant and sizable flesh wound, nothing more.
Dismissing her revolver out of hand, she immediately set to dropping in new bolts into the spin rifle. The turret continued firing for a moment before stopping, leaving a small garden of iron bolts sticking up from the ground around the snake. It only seemed to speed up the monster as it used the new poles to push off from. Seeing this, the turrets stopped. Then she saw Leon shoot not the snake but a landmine a few meters in the front of it off from the side of its travel. Since the Wisp Cat incident, she had learned that they were indeed mines but tuned for a heavy load, so posed little risk to humans or light beasts. The mine exploded in a plume of dirt and rock. Showering some back onto the roof. The snake paused momentarily, stunned by the explosion. This was their chance.
Leon swore out loud, protecting his rifle from the debris before reaching into a chest pocket searching something out. Distracted from her immediate task of reloading, she saw him pull out three shining rounds. As he slotted one into the rifle, she noted the sheen of gold. Before Leon could bring his rifle back up to his eye, a third gunshot clapped out. This time the snake's head splatted a bloody fountain into the air.
This was not the end of it as the creature thrashed about. Though it no longer moved with the sense of purpose it had before. Blood and dirt flew as it tore up the mown turf. Another volley of bolts from Ka's crossbox flew down, but they mostly found their mark, and when they did, they pierced the serpent.
The dust started to settle as the long snake lay there stationary but for blood seeping into the exposed dirt. Mixing into a dark clay.
They stood like that at the ready for minutes. The wind blew, the whirring sound of rapidly spinning wheels went quiet. She could almost hear the sound of everything breathing. Before long, Leon stood up and walked along the roof. The crunch of roof gravel under his feet as he ushered her to follow. They met a tired Ka'Shek at the bottom of the tower. No words were exchanged, but he looked ragged, having been pulled up from bed straight into combat. They walked up the wooden steps. Their feet are heavy on the boards.
Once they reached the top, they found a similar sight of everyone extremely weary. The Ball twins she noticed for the first time were topless. Sarah looked worried, but mostly Gunther just looked angry. Once again, she wondered where Malcolm was in all this? Had Ka woken up while Malcolm slept? That wasn't right. She had seen him awake this morning before coming on shift. Gunther nodded, acknowledging their arrival before turning to the console and dialling them back down to yellow status.
"Right, I think we can stand down for now. Ka and the Twins go down there and gather up what you can. Ka can you set the flame?"
This seemed a serious and notable question. Ka solemnly placed both his hands on his shoulders. Left hand on the left shoulder, fingers spread wide like a pauldron before bowing his head in a solemn gesture. The twins looked nervous. Brad twitched, seeming to remember the Wisp Cat. He seemed to be about to object when Brian elbowed him hard. They left their rifles, and Ka left his crossbox. They opened the hatch and went down the Tube shaft before emerging moments later from the front gate.
The entire squad watched with weapons at the ready, watching the process. They had collected bags from the entryway with the airlock ironclad doors which protected the entryway. The rope system Brad had used on her first day was preferred when one or maybe two people needed to head out. For larger excursions, especially with an Orc, the front door was the only sensible way. Though it put the base at slightly more risk, it was a much more practical route for a firing retreat.
Under the watchful eyes of the squad, they collected any metal they could. Both the twins wearing thick leather gloves. They left the shattered wooden bolts. Brian had a small but powerful magnet. He ran over the ground picking up bolt heads and bits of broken metal. It was risky but better than leaving worked metal on the ground. When they got to the serpent, they took some photos with a small film camera.
Pickle sympathised with them. She had felt exposed every time she had been sent out to check the mines, trim the grass and one time to document and dispose of the small creatures. The procedure was either to record or retrieve, then document before disposal. She supposed the snake was far too large to shoot out of the pult like its smaller cousin Leon had killed days earlier. It felt strange calling that tree trunk of a monster a snake. The word was too small for it. She watched them photograph its smashed triangle head. The single bullet wound had travelled through it, not cleanly but as a wrecking ball.
"Why couldn't we hit it?" Pickle asked.
Leon and Gunther looked nervous. It was not a look that suited either of the stoic men. Though her mentor Leon spoke first. "Shield, though I've not seen one at the wall in years. Usually only in the deeps, on some real nasty buggers. Kinda like a super magnet but different. You know the metal rhyme?"
Pickle thought for a moment back to the children's rhyme. Knowledge everyone had though she didn't really understand it.
"Wood to weave, Iron to bind, Copper to carry, Silver to shine, and Gold to Trust."
"Yeah, well," Leon ruffled his head. "Knew a different one, but the point is magic don't like iron, it blocks and burns. Two-way street verstaan? Magic doesn't touch gold much so those kind of barrier just don't crack it."
This thought confused her for a moment. She was certain she had seen mages wear iron and gold before. Though she knew the gold standard was on egg timers made with gold. They didn't get time drift. She knew there was gold in some of their tools. She had nicked some magic bits back when. The fence had commented on the gold inlay. Pushing it from her mind and resolving to make some gold rounds.
Watching Ka heft the White Cat she had shot from near the wall towards the pile of death that was being accumulated, she wondered what they would do with the bodies. They couldn't pult them and yeet them into the distance like they had the others. Bury them deep? That would take ages to dig.
It was then that Malcolm emerged from the Tube. Neither Leon nor Gunther seemed surprised. Sarah was studiously watching the work below with the ballista at the ready. Malcolm walked up next to Gunther, not even adding a smart arse comment. Maybe he was finally eating crow, and she would see him grovel and apologise. She pretended to be watching the work below, but really she was just waiting to see what would happen to the smug mage. Finally, Leon broke the silence.
"Bad business. Fred say anything?"
"No," Gunther answered. "I want to call a company meeting once they are done down there. He was still looking into some things for me."
"Malcolm, anything on your side?" asked Leon.
Malcolm shrugged, "Last thing I want to do is summon a spirit or daemon to ask. You know what they are like on the wall. But there was definitely something. What's with the big sausage?"
"Wyrm," Gunther answered. "Not seen, it's like in quite some time. Never seen this sort before. Maybe discovery bonus?"
The three old men watched the work below. Their conversation such as it was slow in pace, unhurried. The death and carnage below them another Tuesday. In truth, she had lost track of the days of the week. She took a moment to count the days back. She had ripped off Queenie after Saturday night takings, so Sunday was the day she had got on the train. Twelve days rotation meant today was Friday. Not that the weekday meant much here. She looked back at the Captain and his left and right-hand men before surveying the work below.
The twins had rags wrapped around their faces, probably due to the rank scent. She could smell it from here. They were standing back as Ka was circling the pile of corpses, shoeing away the Pebbles that were starting to get interested in the feast. It would take them days to pick that pile clean. Ka was singing in a low tone, throwing what looked like salt from a small cloth pouch. After encircling the mound three times, he stood back and finished his song with a mighty clap of the hands.
The pile burst into flame. Not a bright hot roaring red flame but a dead cold, an almost transparent purple-black flame which seemed to cast no light or issue smoke. The little smoke it gave off was more akin to white steam with flecks of colour. Though the bonfire raged, its strange optics allowed her to see the pile still. She looked through a hand scope picking out the details of the creatures now aflame. Their flesh coiled and burnt as usual from flame. It was like watching some grotesque timelapse without the obfuscation of heat haze. Some sort of magical cremation. She had no idea Ka could perform magic.
"Won't that fire draw more attention?" She asked.
"A small bit kitten," Malcolm answered, "though much less than death and decay had we left it. Necrotic flame is a rather elegant spell using the remaining life energy to burn away the corpse. I've tried replicating it though mine has a tendency to explode. Which releases the necrotic energy in a large burst. Not ideal."
Both Leon and Gunther winced at this description. She didn't want to think about the events which caused those expressions.
With the fire set, the twins and Ka walked back to the base. Entering without issue. They watched the flames burn as the Pebbles watched from nearby. Once the flames died down, the Pebbles moved in and claimed the bleached bones. Within an hour, the pile was being slowly disassembled piece by piece. She noticed a few of the little creatures trying to use some vertebrae and small bones as new homes. Though most were unsuccessful.
Usually, Ka and Malcolm would have the following shift, but instead, the twins and Ka took the shift as everyone else was called into the lounge at Gunther's orders. The swing shift would be picked up later, and they would sort it all out. For now, Pickle found herself sitting on a ragged bean bag chair, checking over her revolver. Doc had tried to save her a seat on the sofa, but she hadn't taken it. She was still a bit sore on her, no matter Fred had wandered in with a pile of notepaper, a worried expression on his face.
Leon and Malcolm had taken seats from the dinner table, and Gunther stood in the middle of the room waiting. Meanwhile, the Geek, Virgil, was by the kitchen sitting on a barstool intently interested with a notebook in hand. Everyone awkwardly shuffled as they waited for Fred, the last to arrive to get settled.
"Alright, Fred, you are here. What did you find?" Gunther asked.
"Diddly do. Not a thing. Temps were well within margin. I did not even have the vault spinners online or anything running hot. No strange gases or radio waves, and our neighbours hadn't been naughty from what I can tell?"
"Fotsak! No Wyvern comes to the wall, especially not a baby. I've not seen a White Cat within a mile of the wall for over a decade. Hell's bells a Wyrm by the Zambezi river I could go for but here. Fok that."
Fred shrugged, "I went through all the systems and meters. I checked the exotic supplies and gases, no leaks. If the cause is from our base, it is not technological."
All eyes turned to Malcolm, he lifted his hand's palm up in a comically exaggerated shrug smirking with amusement. "Don't look at me. I was just working on my journals. Haven't even got a potion on the boil. First I heard was Gunther's stay-put order. Though I did feel the aura of menace when I got the message. Sorry snacks?"
"What about Ka'Shek?" asked Fred.
Doc answered, "No dad, Ka was sleeping, and he has his catches for nightmares."
A prolonged silence drifted over the room. Leon looks agitated before glaring across the room at the Geek. "What about him?"
"I assure you Mr. Viljoen while you were on watch, I was merely compiling my notes. I have done nothing other than observe."
"Says you," Leon muttered.
Gunther made a calming gesture, "We have been over this Leon. The Geek, sorry, Virgil is our guest. Our contract gives him access to all areas save the vault and personal spaces."
"Besides, his sort, do magic? Please cookie. Be reasonable." Malcolm answered with derision dripping off every syllable.
The dry clerical voice interrupted Leon glaring at Malcolm. "Eh hum. Am I to understand you encountered a Cantio Lutum Viperia is my guess from what you have said. Florentia Spinus Felix, and I'm sorry to say Sagitta Scala Manga Vermis is a rare but documented genus, so there is no discovery bonus there. While the Wyrm and Wyvern have much in common, they share little with White Cats as you call them, except they all have a preferred food."
Leon, Malcolm and Gunther looked abashed, not wanting to acknowledge the contribution. Fred was disinterested, and Sarah was confused. Pickle looked around before she felt her curiosity burst out. "Well, what do they all eat?"
"Magic, kitten." came the quiet response from Malcolm.
Nodding, Gunther added, "I knew that about the Wyvern hence why I ordered Malcolm to hunker down. I assumed it was his magics which had drawn the beast."
"I had done nothing, and I had been off shift for a while. Ka knows better."
They all looked worried. She looked at Sarah only to see her look down. Suddenly she realised no one was meeting her eyes. She struggled, standing up from the bean bag.
"Wait, you all think me? I've got no magic. HE said it himself," she pointed at Malcolm in rage. "Human standard."
"Close enough, kitten, I said close enough."
She felt her world spin as her helmet grew hot. She felt light-headed. She didn't know what to say. She felt her heart swell, the air thick. More now than when she faced down that charging cat, more than that unstoppable serpent, she felt the reassuring weight of the revolver in her hand. Heavy. Her vision narrowed so she could feel her heartbeat in her ears. Not enough air. Breathe. She couldn't breathe. The gun was hot in her hand, her helmet too. The world was on fire.
Big hands grabbed her shoulder. She felt the gun drop as her wrist was twisted. Before she could register, she felt herself sit down on the floor, with big hands supporting her, rubbing her back. The room slowly came back into focus before swimming again. Colours vivid.
Malcolm was uttering something, swinging his hands through the air. The fucker was casting a spell on her. They were going to try to kill her. She reached for her holster. The revolver was gone. She had it in her hand. No. Where was her gun? She couldn't breathe, was he sucking out the air. She didn't think mages could do magic on you unless you were cut or mostly ware. Did that fucker with the third nipple lie. Wait, she had sliced him with her knife.
She reached for her thigh only to feel cotton. Wait, what happened to her fancy pants? Oh, right, they were going to kill her. Pickle sees red in front of her. Red hair. That fucker all in black waving his arms. Red hair going for her throat, heavy hands holding her. Fuck Jack Jack. She kicks out, back. Right in the coin purse. Foot back sprinters start and come up punching. Red flies. Two down. Moving. Exit. No need to stop the mage. Shoulder charge as she leaps. For a moment, she sees pupils through those goggles wide-eyed cat's eyes. Fear. The moment is frozen when Thwack.
She doesn't feel the shoulder connect but instead, her ribs hurt like a freight train hit her. The landing is softer than expected. She recovers, ready to jump up, when suddenly a large fist rushes into her face. She feels her nose crack. The world explodes in pain.
After a few moments, her thoughts return to her. She feels searing pain in her face and tastes blood on her lips. Her vision returns along with her breathing. Pickle looks about the room. Malcolm is standing watching her with his goggled eyes. His stance was ready, and his fingers in a strange configuration. She can feel a sense of something from him.
Sarah is on the floor out cold, Fred leaning over her in worry. Gunther is watching with an angry face, redder than she has ever seen it. She is on the sofa. Where is Leon? She tries turning around only to find her hands restrained. She feels her wrists bound. She is dead. Wait, why haven't they killed her? Gunther approaches his hands up in a calming gesture.
"Easy girl. Stay still."
Panicking, she glances around the room, trying to take it all in to get a sense of things. Few times in her life before had she ever failed to escape but never before in a life or death struggle. She had to beg, sacrifice much, but she had lived. She could do it again. He had said girl, she hated it but well, if that was the card to play. She started crying.
"Please, Captain, don't kill me. I'll go. I didn't know. You said it yourself I'm not cut out for this."
A light but firm palm tapped the back of her head. Some blood and spittle flew forward.
"None of that kak." Leon said from behind her.
"Malcolm, is it contained?" Gunther asked.
"For now, but I should get her in my workshop or the vault."
"Nevermind that for now, Fred, is Sarah okay?"
"I'm okay," Sarah's voice came through. "Just didn't expect to uppercut by a patient."
"Patient?" Pickle gaped, looking around the room. "You ain't killing me?"
This strangely seemed to relax Gunther. Though Fred still looked upset, Sarah was laughing. Gunther took a deep breath. "We just need to control your magic, is all."
"I don't have any magic."
The quiet paper voice came from behind, "Actually, the girl might…"
"Shut it." Gunther cut off the Geek. "This is company business you can observe, but I will not have you interfering with my family." He paused, waiting to see the acknowledgement on Virgil's face. Pickle couldn't see it restrained on the sofa, but she could see Gunther relax.
"Malcolm said you weren't likely to be a risk for a while. So I didn't want to jump straight into it, but he did say you would need testing and maybe training at some point."
She glared daggers at the mage. So they all knew. Her deepest secret and they had all been laughing behind her back. Fuckers. Malcolm shrugged.
"So you all know I'm not human? Well, I might not be, but I don't have magic. Even a mage said so." It was true a mage at Queenie's claimed to know how much magic a girl had. He had been very drunk, but he was down from Europe for the conference. He had read her palm and said she was enchanting but without craft.
"Some foreign idiot, no doubt." Malcolm scoffed. "I'm guessing you don't take off that helmet much. Regardless, you have a web woven tight around yourself. Not every metahuman has magic, but almost all who turn do. Though yours is buried deep. You have been soaking it into that helmet most of your life, is my guess. Though I wouldn't be surprised to discover you had some other sinks. So much so I doubt you will ever fully turn. Something got your emotions running high today, didn't it?"
Sarah, now standing shyly, said, "My fault, I am afraid. I was pestering her about her physical. Which in hindsight, I now understand why she was avoiding."
"You knew?" Pickle could feel real tears rolling up her throat now. "You all knew?"
Gunther looked solemn, "I knew the moment you walked up to the table. Been on the wall all my life. Didn't know what I knew, but I knew. That is why I got Malcolm to check you out. Malcolm obviously knew."
"Scraps told me," Sarah added, "I do not think she knew it was a secret. Her nose knows."
Gunther nodded, "Told Leon to watch out for signs. He was your trainer. No one else knows to my knowledge. Virgil is under NDA, and I didn't see any reason to tell Fred. Not his department. The other's aren't company."
She thought about Brad's horrible jokes at Ka. "Please, can we not? Not tell them."
"Sure girl, but you need to tell me what happened?"
"Sarah was right, I was upset. I just couldn't think about how to avoid the physical and I didn't do great at training this morning. Guess I was running a little hot. Didn't think about it because that's when the dragon showed up."
Gunther breathed out a heavy sigh resting his forehead between thumb and forefinger. Rubbing and pinching the skin, trying to work out the heady thoughts.
"Right. I have to go file paperwork, let the Tower Watch know why we went red. Let's get this cleaned up. Going to need to draft new schedules. We are going to need to make some changes. Leon, take Ka. Malcolm, you're with the girl, make her safe, and handle it if she flares. Meeting dismissed."
Everyone had a purpose and set off. Leon let go of her as Malcolm collapsed onto the sofa next to her in a lazy way. Throwing his arm over her shoulder. She wanted to pull away, but her hands were still retrained, and her nose was running bloody. He leaned over and whispered in her ear, "You're magic kitten."
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 6
Pickle on the Nightmare Wall - Part 6
New Routine
Over the next two weeks, Pickle started to enjoy life on watch. For the first time in her life, she had a routine. While her control was limited, she felt empowered and knew what tomorrow would bring. It was strangely peaceful. Gone were the endless days of darkness, crawling to find nuggets to extend her life, running from place to place, constantly on alert or surrendering to the whims of the clientele and the mood of the night.
Stretching in her bunk, she felt her blanket pull off her as she stretched out a full-body yawn waking her up. Tussling her hair with one hand, she lay in bed staring up at the concrete ceiling with its expansive glass skylights running the length of the dorm. It was a sunny day, and while she knew the winter chill would be on the air in her warm blankets, she didn't feel the bite of it.
She turned her head to see the small hourglass filled with gold dust still had a few minutes in it. She reached over and tilted the finely made but robust device, effectively snoozing it as she stretched. Her internal body clock was good, but running on gold standard time was pretty much required to keep things running. She had a few minutes to wake up. Sitting up in bed, she looked at the brown curtains still pulled tight around her bed.
The tower operated on a pretty strict five and dime shift rotation with three teams. Naturally, the Ball twins were on a shift team because they were brothers, and frankly, everyone found them low key annoying. Though outside of that incident on the first day when Brad was drunk, they were nice enough. They were class clown types keeping the mood light. The Balls did their job well when not showing off.
Still she kept her curtains pulled each night. Sarah told her in all seriousness that if anyone intentionally messed with another person's rest period, then Gunther came down on them like a ton of bricks. The barracks dorm was actually the safest place she had ever slept, but old habits die hard. She kept the curtains pulled and clipped. Pickle also slept with her gas gun under her pillow. Though, to be fair, Leon had advised she always keep her personal weapon close. Her spin rifle was up in the locker.
Leon was assigned to show her the ropes, though everyone helped, which meant they were on shift together. She couldn't hear him moving, but he might already be up. The man slept the least of any of them. His bunk was just opposite hers, but she knew he would be in the kitchen. This left Malcolm and Ka on the third shift. She had been told the shift teams occasionally switched it up, but they had stuck to those patterns so far.
With the curtains pulled, she had no idea where the meter was, but she was confident there would be heat to spare from making breakfast. She grabbed her shower gear and a change of clothes. The girls had done her a solid when buying her equipment, getting only natural fabrics and not ones she would have picked. There were six days change with a mix of outfits in what they had bought her. All-natural fabrics. They also thoughtfully bought two sets of silk pyjamas, an extravagance she would have never purchased herself but a welcome one.
She had packed clothes in her bag before signing up, but more than half had synthetics, which meant they were mostly tossed into storage. Thankfully, Sarah told her to keep the bras and panties as the amount of fabric compared to the benefit was just too great. She also learned that not all synth fabrics were as bad as others. Anything wired with smarts, synthed or meta was a strict no. So bye-bye fancy pants. Apparently, plastics gave off a smell that upsets Wild beasts but only up close though it could rub onto your skin, but it wasn't like a strict no, more of a to be avoided. So she mostly stuck them away not to be worn, though items like her rain jacket and undergarments were too helpful not to wear.
Picking up her helmet from the side table and checked her ears were tucked in. She checked her gas gun safety and the rounds in the revolving chambers before getting up out of bed. Pulling the curtains aside and clipping them open, holding her change of clothes and shower gear. She hadn't needed the top curtain as she had slept natural hours. Today was a dime day.
The rota was four five hour shifts followed by the shorter shift, which was four hours, called the dime shift. The dime was from ten till two, and those days were her preferred shift as you got a nice bedtime and ten hours before next duty. Dime day was followed by hell day, which was on a shift from two in the morning until breakfast. Sleeping the day or not, if things were busy, then doing another shift five till late. She hated hell days, mostly because she needed to do firearms training on her first hell day, and Leon wouldn't let her sleep more than a few hours around lunch.
Finally, you only had a morning shift from seven in the morning till lunch on break days. In theory, these could be the best days, but you had to use the afternoon to do assigned work orders in practice.
The Balls were on watch currently, so their bunks were open and a mess as per usual. After stacking both beds, they had more space than anyone else in the dorm, but their crap spread like a messy invasion throughout the room. Dirty jockstraps, ammunition and magazines spread out. The occasional stray sock drifting out into no man's land. They knew never to intrude on Leon's area with his small rock collection and neatly made bed. Leon's bunk was clear. He had gone running already.
Her neighbour was Ka'Shek, and he kept inside his space like a champ which was impressive considering his bulk and the amount of stuff he had. The bed had been replaced by a wider and taller one from storage now draped with animal skins with his finely embroidered protection charms. Fetish and chimes hung in his space, dancing silently in the still air of the dorm. Ka had lugged up a wooden chest from storage, finely carved which he had carved on a previous visit which now kept all his stuff in. The large orc was currently sleeping with the curtains wide open. He never closed them off, even sleeping through the daylight without them.
Gently tiptoeing on the cold concrete floor, she eyed the last bed by the door on her side. Neatly made with no personality, the trim space of the Geek. Everyone called him that now, even to his face. Virgil Northcott was not a personable character, and it's hard to like someone who isn't working when everyone else is.
Walking into the lounge, she felt a bit more comfortable. Malcolm should be asleep in his room, and the Balls were on duty. Sure enough, Sarah was in the kitchen making breakfast. It smelled like eggs. She smiled and waved as she cut through, noticing Sarah turning rice on the wok after throwing in some chopped veg.
Glancing up at the heat meter opposite the dorm door hanging on the lounge wall, she noticed the base was running a little hot. This was normal for this time of day, especially with a hot breakfast. Controlling tower temp was essential but what it meant right now was she could have a warm shower. She didn't understand all the base systems yet, but Fred explained that some stuff generates heat and others use heat. Though most things made heat and most the bleed off was ambient into the ground and air. Taking the right turn into the corridor to the rear apartment, she noticed both the dorm showers were free, so she nipped into the second one. It was morning chilly in here, but the tiles were dry.
The tower had four washrooms side by side. Two for the dormitory barracks, but everyone used them, the officer's washroom then a final one in the apartments. More correctly called the commander's apartments, but Gunther didn't use them, instead of taking one of the two officer's rooms. The apartments were used by Sarah and her dad, Fred, the chief engineer. The design was uniform, but the cleanliness and accoutrements were not. She looked around the few broken and cracked tiles mixed in with the mismatched replacements. Leading up to the strange coral white band that rang around the top of each wall where it reached the ceiling.
The washroom had a sink, shower, and toilet interconnected into a communal greywater system to minimise waste and strain on the recycling systems. The sink water was drinkable, and the shower water less so. Locking the door then undressing, Pickle popped her clothes onto the shelves by the door. Pistol on top. A pull-out glass separator kept the water primarily to one side of the room, which was a meter by two, and changed. Whether or not you could run the shower warm depends on the base temp. Typically, the base ran hotter than ambient in the mornings, trading heat off during the day and finally running a bit cold at the night's start.
The base was never warm enough, and she had been told it was always a bit too warm in the summer. Likewise, the shower wasn't a hot shower that she so desperately wanted but instead a comfortable, warm shower. The cool air just left her a little bit too cold to enjoy the wet. Thinking through the drills Leon had been running her through, she wondered what she needed to get done today.
Every second break day, Captain would take a shift with Fred or Sarah to give you a rest day. So they were on the morning shift every second day as cover. Those sixth days were a thing of beauty and the best day of the six-day week. You were never assigned any work orders on those days, and barring a yellow flag, you didn't even need to be on alert. Securing a few stolen days of peace between risky gigs or travelling from place to place, she had never had the concept of a rest day. The base ran on a twelve-day cycle, at which point the rota would fully loop again. Today was the last of her first cycle. After the second would be a resupply day, which was off rota. That was called a month or session, and when she would next see Scraps.
Other bases had pretty frequent communications out, but Gunther's tower ran dark mostly. He had a tower captain's call every week, but Leon says it's mostly a broadcast. Captain listens in, and he can transmit to speak on the call, but he rarely, if ever, does. He mostly files his paperwork with Scraps on resupplies. The tower is effectively out of contact from the world for about a month at a time. The tower would receive news, weather and little data dumps. People could send through data, but the tower policy was not to transmit.
Lathering up the shampoo in her hair, she tilted her head back to wash her face. She still had some makeup on, smiling, she rubbed some of it off. Sarah had got her dad to take the break shift yesterday so Pickle and her could spend time together. She had some training with Leon in the morning, but she mostly spent the day helping Sarah with the greenhouse and outdoor gardens. Though the gardens were bearing their last harvests for the year before the cold snaps, they still had plenty to give.
After gardening, they had cleaned up made lunch, then Sarah showed Pickle her favourite spot on the kopje at the back of the base. It was a tiny outcrop that looked south, not north. Sarah had a small easel stand set up for painting. Though she wasn't painting landscapes but instead repainting images from holofics, magazines and books. Famed adventurer Vindaloo Vu exploring the depths of temples or wearing a tuxedo to a famous ball. World-renowned grav biker racer Udeksan Nutineen with her flaming red hair a mirror of Sarah’s. King Charlemagne touring visiting his cousin in Windsor. The floating markets of New Hope and one of the seven grand rings of Heaven, suspended in the stars.
Pickle smiled as she turned off the water and reached for her towel. Her mind was all kinds of distracted today. She needed to get to the range and see if she could hit Leon's targets. She needed to pass his weapon assessment before the resupply, or so Gunther had said last week. Leon had set a few different live-fire training exercises, but she couldn't practice long. Leon allowed her only one live-fire training session a day, assuming the flag was blue that day.
Pulling on some olive green cargo pants she had picked out, she pulled the belt strap tight. Securing the gas revolver to her waist, it slotted easily into the quick release holster. She checked herself in the mirror. Resolving to trim her hair the next free day, she pulled and twisted the ends. Grabbing a bit of scented soap, she styled it to stay out of her face. Sarah had told her it was fine. Apparently, the Wild would smell emissions from tech, magic and smell the death or trapped death of plastic over long distances but perfume not so much. Oh, Leon claimed they would smell and track it like any other animal, some better and other's worse, but it was a mundane thing. Not some irritant that would drive the Wild to hunt down the source.
Finishing up with some moisturiser, she glanced at her toothbrush. Remembering the delicious smell of breakfast from moments earlier, she decided to forgo the morning brush in order not to spoil the flavour. Wiping down the washroom with the washrag, she squeezed it out and washed her hands, doing one last check of her helmet before stepping out.
"There is my model. Want me to give me a hand wrapping these breakfast burritos?" Sarah's voice asked from the kitchen as Pickle walked past.
Pickle shifted her clothes bundle under her right arm before giving a thumbs up with her left. "Sure, let me just drop off this and pop on some shoes."
She grabbed some shoes and quickly helped roll the burritos with Sarah. The coffee clicked to warming just as they were finishing up. They nibbled at their burritos, chatting about the day before. The Geek stood up from his note-taking to claim his burrito and a small glass of water before returning to the lounge table.
"Can I borrow that magazine," Pickle asked between mouthfuls. She drank down some water. It was surprisingly better here than the municipal city supply. "The one with Felina?"
"Sure, I will grab it in a second. We should get the boys their breakfast."
"Mind doing top side. It's too early for Balls."
"Yeah, I can do them and Pa. He is down in the vault. You mind doing Malcolm and Captain?"
Pickle had learnt the base layout since arriving and was surprised to discover how much was below ground. They spent almost all their time on the first floor sleeping or relaxing or on the roof watching. The first floor was built around the lounge and kitchen area. The building was somewhere between a plus symbol or capital T in shape. The west room off of the lounge was the bunk room she slept in. The officers quarters were opposite. Then down the south or shaft of the T were the shower rooms and the captains quarters used by Sarah and her dad. The little north tip was a small staging room with the Tube as they called it and some shooting windows.
Neither the bunk room nor officers rooms could look directly outside. The outer shell of the first floor was a narrow corridor built for defence. The surprising part was the armoury being the only room on the ground floor beside the kill room. Then below that, the train station was flanked by two massive warehouses which stored supplies. Enough dry rations, ammunition and supplies for the base to run for quite a while. Months would be her guess. This was also where the waste recycling was located.
Finally, at the deepest level below even the train station was a deeply sunk metal tube. The vault could only be accessed from the Tube, and it was entirely shielded by metal. It contained the base Spin Generators and any high-risk elements like her small box with the fancy pants. It was also Fred's workshop and their last resort. Though it would be an extremely tight space for them to all climb into. It was their own brass burrito coffin buried more than ten meters below ground. Though maybe only two or three meters below the train station.
Shuddering at the thought, she placed the breakfast burritos on a tray with a hot cup of black coffee and a green tea. Grabbing the tray, she walked down the corridor. She came to Malcolm's door first. Holding the tray carefully, she gently knocked on his door first. Maybe she would be lucky, and he would be asleep like Ka.
"Enter kitten."
Drat. Pushing the handle down and opening the door wide to carry in the tray with both her hands. The room should be furnished with strange occult symbols or demonic evil things she felt, but instead, it was rather plain she felt. His bed was the same as hers, but the bedding was expensive and exquisitely chosen to match the furnishing, and he even had some little throw pillows on the bed. She had never seen him in it, or it even creased. The room was bathed in the warm morning sun from the skylights. The floor was layered with rugs of all colours and designs. A modest desk on the left wall was flanked by bookshelves with a tall dresser in the corner. All were made from fine wood and show fine joinery and detailing, emphasising their crafted nature. A master carpenter had made them as a set probably to order. As always, Malcolm was seated at the desk, reading a book.
"Breakfast burrito and some tea, Sir." Pickle said in her flattest voice. She gently placed the plate and tea on his desk off to the side.
"Ah, how delightfully robust. Thank you for the tea kitten." He gently tapped the cup with a gloved finger.
She nodded, turning out of the room. That man still gave her the creeps all the time she was there. She had not seen him sleep, eat or even remove his wrappings. She had once joked with Sarah about it, and she had just shut down the conversation. Since then, she had been too afraid to ask anyone else about it. What was he? He hadn't performed any great works of magic since the train ride. He sometimes did a short cleansing spell though it was always a brief thing with no visible effect.
Her head still lost in thought, she knocked on the Captain's door.
"Enter."
Gunther's room was something else entirely. The bed was trim and military with no furnishing and the same blankets she had on her bed when she arrived. The Captain sat at his much larger desk immediately to the right of the door. The desk was always a mess of official documents, war books, maps and reports. The floor mainly was unadorned except for a small rug. The rug was under the desk and chair, placed more to protect the floor from wear than any sense of decor. He quickly made some space for her to set down the plate and coffee.
"Wonderful, grab a seat, will you. I have some questions for you."
"Of course, sir."
She grabbed the wooden chair against the wall. It was next to a glass cabinet that ran the length of the wall. Inside were various photo frames, small trinkets and ornaments. Medals and memories from conflicts, along with a few old guns and weapons. Gunther's large chem rifle from the train hung on the wall just above an enormous looking gatling gun. It was THE gun of legend from which the company drew its name. The weapon which the legend had held back the night with for four days alone on the wall.
The Captain sipped his coffee and looked up at the ceiling for a moment. The twin skylight which ran the length of the roof showed the bright morning sky outside. He looked lost in the clouds. Pickle started worrying, could this be bad news? Was she not learning fast enough? Had she broken some rule? Unconsciously she felt her right foot bouncing slightly.
"Today, you finish your first cycle."
"Yes, sir."
"You haven't had to kill anything yet, correct?"
There hadn't been anything to kill. The tower was barely attacked, a few critters had come inspecting, but there were only a handful of incidents other than the Wisp Cat attack. Most were harmless wildlife that would move on. The few actual Wild creatures that came to investigate could often be deterred by wounding rather than killing. Leon had spotted a snake on their watch once and without preamble had shot it dead, kill shot. Leon told her to raise the alert, and once Ka was there to cover, he had gone down to collect the kill. They had launched it from the catapult, more akin to a flat ballista than the medieval sort she thought of typically with the word. It was strange, Mars tower was attacked almost daily, and the Medpoll tower was assaulted three out of five days.
Gunther cleared his throat, and she was immediately pulled out of her retrospection.
"Not yet, sir."
"Leon said you are coming along okay. Your weapons training needs to continue. Your accuracy is below what I would like with a Spin Rifle. I'm tempted to send you off base for intensive training with Leon. Can't spare you, though. I want to see your numbers up."
"Yes, sir."
"You feel like you got the hang of a routine."
"Mostly, sir."
With one hand, he dug through some papers to retrieve the one he wanted. Reading it over before asking another question. "How do you feel things are coming along? Can you do this for the long haul?"
She paused, knowing the Captain preferred a well thought out answer.
"If this cycle is typical, then yes, sir, I think I can do this job."
"Duty, not job. I'm not your employer, I give the orders out of the mutual agreement, but you are a stakeholder, not a freelancer. You have invested in this tower, and we have in you." Looking down at the page he had picked up, he continued. "Leon has good things to say, mostly."
She waited for the Captain to continue as he stared directly at her. She tried to hold her calm.
"Says you a below average shot but take orders well and the training seriously. You don't let your mind drift on watch and are attentive. He does worry you're a bit too distant and says he worries about how you will do under pressure. Do you agree?"
"Agree he is worried, sir?"
"Can you deal with the crush?"
"Think so, sir."
The Wisp Cat had frightened her, almost as much as that Six Stalk on the way here, but if those were the great horrors of the Wild, she was confident she could handle it. She had taken worse in the city.
"Well, I hope it is a long time before we find out. Any nightmares?"
"None, sir."
That was a lie but those she had brought with her. Old memories and fading pain. In truth, they had been getting better since she got here. She found herself anxiously rubbing the metal plate which signalled her membership to the company. Gunther noticed and smiled.
"Well good, and nothing strange or unexplained? Leon told you the moment you see something even a little weird. Don't doubt your eyes or ears. Tell us immediately."
"Yes, sir."
"Okay, I'm keeping you on your own time. Report to Doc. You are overdue for a full physical. Should have been done week one, but she said that she wanted to wait till you had settled in."
"Today, sir?"
"Yeah, today, before your duty. Dismissed."
She nodded and got up to leave. She felt awkward without a salute. The company was pretty informal in many ways, but the Captain ran a tight ship. He was grabbing his burrito as she closed the door behind her.
Bugger that Doctor's appointment with Sarah was going to eat into her free time. Not that she could complain much since she had her day off yesterday. Walking into the lounge, she heard the shower. Leon was back from his morning run. He tended to run out back behind the base. Said he needed the grass for it to feel like a real run.
In the kitchen, Malcolm was wiping down his plate and putting it away in the cupboard. She excused herself, gently sliding the tray back into place before turning to face the Geek.
"Geek, have you seen Sarah come back?"
"I believe she is down below with her Fred."
"Drat, want a quick game?"
"Sure."
With that, the small man shut his book with both hands as she grabbed the folded go board from the shelf in the lounge. It mainly was board games and a few books, but this old go set had seen a lot of use since the Geek had arrived. He had asked the Captain to a game. The Captain had lost, but it was clear from watching even her novice understanding of the game that they were both excellent players. So she had started to learn the game from Virgil whenever she had a moment.
She was still playing with all nine handicap stones and losing every time. Though she felt like she was learning and with the full handicap, she had taken a game off Ka when they played. She felt a natural affinity for a game where you needed to watch all parts of the board and forever be aware of your liberties. You attempted to forward your goals always while monitoring your escape, only capturing when you had control and the ability to escape. Partway through the game, Leon returned from the dorm fully dressed.
"You gonna take much longer, Pick?" he asked in that thick Afrikaans accent.
Without pause, the Geek piped up, "This game is done."
Sighing, Pickle stood up, "Yeah, you got me again. Thanks. Mind grabbing the board?"
With that, she got up and went to the iron door by the kitchen. Two iron doors were just by the kitchen. The right one led to the kill corridor surrounding the dorm but the left one led outside. Stepping around the lift down to the station, they came to the second door with its big metal bar. Lifting it out, they were in the open air behind the base.
The back of the base was butted up against a kopje. The mix of large boulders and dirt formed the petite mountain like a handbuilt diorama. The formation was unnaturally trimmed with large boulders pushed down or broken up in places to avoid providing easy access to the roof. They were technically behind the wooden fence and firing lines. Still, the system was designed with that being breached in a heavy assault.
The train tracks were not visible for about a hundred metres till they broke out of the underground tunnel and onto the surface. Even then, after the tracks surfaced, raised dirt on either side ran for about a kilometre. Making the tracks hidden from sight unless you had a birds-eye view providing a stealth approach or a covered line of retreat.
Towards the back of the plateau, Leon had set up a few sandbags and some shooting positions. It seems he had already brought out her spin rifle and a few of the other weapons. They both slipped in the small ear protectors. Unlike the sophisticated digital versions used by Bruno back at the club, these weren't radio linked smart headphones she was used to. They were crude miniature wooden carvings that fit snuggled in your ears. They had some magical runes inscribed, which Malcolm assured her wouldn't upset a Wild bee. Though it was hard to hear anything with them in as they quickly dampened sound, the effect, while quick to start, was slow to wear off, which meant you often missed anything said after a loud sound.
"Gunther wants me to give you a score on all the weapons. You want spin first or last?"
She eyed the weapons he had laid out on the blanket. On the left-most was her spin rifle. He had encouraged her to mark it and make it her own. In curly red letters, she had written Get Fucked. Next to her weapon of choice was a chem rifle, gas launcher and a crossbow. Not every type of weapon the tower stocked, even ignoring the mounted turrets but most of them.
"Last, please."
He nodded, "Personal C"
Without pause, she drew the revolver from the quick draw holster. Sighted downrange at the stone target, it was marked a red circled letter C. Breathing for a moment, she steadied before firing a single shot. The pistol was surprisingly quiet but had a hefty kick. She quickly managed and sighted down the weapon again, confirming her hit. It wasn't the centre, but it was inside the circle. She held that stance for a moment before Leon acknowledged the success.
The gas revolver had eight rounds, and so the cylinder was oversized for the weapon. All eight chambers were loaded at all times as the safety mechanism was reliable. The gun didn't take chemical rounds, which were ejected, instead the entire cylinder was replaced to reload the weapon. It made partial reload impractical. Each chamber had its own pressurised reaction gas, which would expand rapidly when slammed firing pin. In truth, it was a combination of compression and a small explosion of cold gas. Meaning unlike the chem rifles, the gun didn't run hot and was relatively quiet. Even if it was a pain to reload and had lower velocities, it was a solid choice on the wall. Unlike her needle gun, which was truly whisper quiet, this was a muffled whomp with each shot.
Holding his hand scope to his eye, Leon examined her hit. He was less than impressed but not upset. He rattled off seven more target letters. Sometimes pausing between them and other times chaining a few. The targets were all down range but set up high, low, and to either side of the train tracks. Some targets were small. Some large. They were all red circles with letter markings painted on stone.
He had driven home day one that hitting inside the circle was all that mattered. She should try to have margin, but he wanted the quickest shots that didn't miss. More interested in her reaction time and adequate accuracy. It was tough to balance the speed required the confidence of hitting the target. Given enough time, she could hit almost any target with any gun, bar a few outliers like the distant targets with her gas revolver. Though if she took too long, he would declare a miss.
After the revolver, they did a more extended crossbow session. Thankfully training with wooden training shafts, so Pickle didn't need to retrieve them from the range. Leon preferred training on the crossbow and gas guns because they were low risk. Honestly, Pickle had selected the gas revolver as her personal weapon because it was most similar to her needle gun. Still, the low emission of the weapon was a strong motivator. She was a decent shot with the crossbow, though, and if it was more compact or had a powered winder, she could see herself using it.
The gas launcher and its cousin, the gas canon, were beasts of weapons. They both required bracing on the ground or a mounting point. The launcher slung a projectile, typically explosive or chemical in nature, though they used differently weighted wooden balls for training. Leon threw random balls at her before calling out the target. She was expected to judge the weight and adjust. The weapon had two dials for weight and pressure. A simple looking glass tube was filled with a two colour solution. By dialling the weight, it changed how much fluid was in the Tube. Then based on the angle of the weapon, you could see minor markings on the Tube, which would indicate approximate launch distance. You could then tweak the pressure to dial in the range. It wasn't perfect, but it let her get much closer than she would without it. Temperature and wind were the most prominent things the simple glass computer couldn't account for with its coloured fluid. The gas canon was somewhere between a sniper rifle and the cannon of a ship. It was truly terrifying, but like all the gas weapons, reloading was a pain making them a great opener that wouldn't escalate the Wild too much. Still, they didn't have the staying power.
Her performance with the launcher wasn't fabulous. She just didn't have a feel for the calculations involved.
Next was the chem rifle. Checking her ear protectors, she saw Leon pulling out coloured tokens. The protectors worked a bit too well after a loud shot. Unlike Gunther's unique rifle, this chem rifle didn't have nearly as many compensators. She had since learned that Gunther's rifle was an ongoing project of Fred's to improve the stealth nature of it. The rifle she now used had a much earlier version of the design and was still way more efficient than a traditional chem rifle, softer too. Unlike the versions she saw in the city, there were no spent cartridges expelled from the weapon. Instead they dropped into a well, built for the purpose.
Leon threw down the first token, J. She aimed and fired, feeling the power of the explosion as the round tore into the target. He quickly threw down three more letter tokens before tapping her on the shoulder. So not the entire cartridge. She was grateful for more than just an escape from the loudness. She wasn't as fond of the chem rifle, and worse, you were expected to load your own rounds. Leon had said it was to do with magic. Though she still hadn't heard a decent explanation, it frustrated her.
She was not going to ask Malcolm. Two weeks and he still called her kitten. At least Gunther had stopped calling her girl.
Finally, she picked up the spin rifle, the weapon of choice in the tower. She clicked it onto idle. Checking the gun. The spin rifle had three modes of operation: dead, idle and hot. Dead was basically just its active-duty state despite the name. When you pushed it into idle, the spin drive got the wheels turning, and it started to pull a vacuum. A slow whirr built up in pitch and volume before the pitching continued to go up. It became quieter as the complex mechanism created a near-vacuum, dampening the sounds coming from the weapon.
Idle speeds were still manageable. You could move the gun around easily enough. Flicking it into hot, the whir grew in intensity, but it was still dampened. The weapon could run like this for a few minutes before needing cooling off or switching back down to idle, but the real issue was the sticky effect. Fred had tried explaining it to her. The drums spun so fast that the gun didn't want to move. You could easily make minor adjustments, but you were constantly fighting the weapon's desire to stay.
Leon quickly listed off-targets. She had practice bolts loaded, wooden shafts with no core or head, and they quickly shattered on impact with the stone targets. You could dial up and down the speed of the rifle. It allowed you to fire with greater power and distance but shortened the life of the weapon. She was expected to hit every circle three times with the rapid-fire rifle. It required her to refill the gravity feeder with new bolts twice, an easy and fast process that support in a pinch could do.
It was exhausting, and this, more than anything, was why she picked it as her last. By the end of the training, she put the gun back into idle. Feeling the warm glow coming from the drums of the weapon. Checking the spin drive which powered the gun. According to Leon, the rifle was complex, but it was the most refined version of this weapon design. The original version had been developed by Fred on the army RnD budget. After the military dissolved, he had spent his life refining the design among another low emission tech.
Not only did you need to manage the heat, stick and ensure it could pull a vacuum. You needed to spin up the weapon to a state of readiness, and it was powered by a spin drive that needed recharging. The spin drive drum could be hot-swapped with a new one, but for the same reason as making her own ammunition, she was told to keep using the same two drums as much as possible.
"How did I do, boss?" She asked in her cheeriest voice, trying to mask her anxiety.
"So so, Shumba. You need to exercise your arms more. The spin got you wobbling at the end there. Also, your launches were sloppy. You're good with gas but not enough strength for me to assign you a cannon. Chem okay. You sure you don't want to switch to crossbow?"
"You got an auto winder?"
"Eh, talk to Fred. He likes a challenge."
"What you going to tell the big boss?"
"So so we not feed her to Dark Dogs." He smiled at the last, showing his teeth to reassure her of his dark humour.
"Footsack, schellum."
Laughing, they packed up the weapons. Pickle went down the range to retrieve the launcher balls. Thankfully all the bolts today were practice shafts which mainly had shattered. Pulling out the metal javelins was a pain, never mind resharpening or heading them. Going back inside, they went through the lounge and out the front door into the kill room. Concrete stairs lead down to the main front exit but also the only door into the armoury.
There were weapons in other places, small lockers and the like. But the bulk of the weapons and ammunition were stored in the room below the dorm. It included a few work tables for repairing weapons or reloading shells. Though all the powered tools and spin rechargers were down in the vault shielded from the outside.
Placing the weapons back into the proper cages, Leon oversaw her reloading some chem rounds. The required stretching, to remove the little metal footplate of the round. The plate contained most of the hot gases from the chemical explosion. Then cleaning and drying before she used her own personally assigned powders to mix new propellant, which she poured into the round. She then took a bullet, thankfully shared, which she seated on the same footplate before settling it into the cartridge and pressing it back closed. Too much pressure, and the round would stick and explode in the barrel. Too little pressure and the floor plate would fly out or buckle. Which could ruin the cartridge or, worse, jam up the gun. It was a much more complicated system than the chem guns she had seen before, which fired their bullet then ejected the shell.
"Leon, why can't I just make a bunch of these? And why do I have to make every one of them?" In truth, she had a small box of ammunition she had prepared herself but only about 30 rounds.
"They go bad."
"Huh?"
"Did you never think why most people use plasma guns in cities?"
"Not really, aren't they just better?"
"In some ways, yes, they are, but they are expensive and complicated. Much simpler to use gunpowder."
"What?"
"Chemical guns."
"But why do I have to make them."
"You make your own stuff to give it protection."
"Protection?"
"Ask Malcolm."
She made a face to which Leon just shook his head.
Leon continued, "Look, I don't like the guy, but he is reliable. Gunther trusts him, and he is the only mage I've seen survive by the Wild. Not including Wild tribes."
As they cleaned up, she tried shifting the conversation to Leon's scouting missions into the Wild. He had spent days and sometimes even weeks in the deep Wild on scouting missions. Sarah had said he was one of the most experienced rangers on the wall. He looked at most in his late thirties, but she knew he had been alive much longer in standard time. Sometimes Leon let things slip that just seemed too bizarre. He was evasive when talking about the Wild, trying to focus on the dangers and downplay all the things he saw. Still, he downright shut down if you asked him personal questions.
Heading onto the roof, they checked on the Ball twins. Brad and Brian were always on watch before them, so they had gotten used to it. The boys were nice enough when they weren't being arseholes. They hadn't tried to impress her again since the Wisp Cat incident with any acts of bravado. Still, they constantly told stories about their previous jobs and campaigns. Boasting of huge payouts and successes.
To hear them tell it. The Balls had operated in all the Free Cities of North America, worked with European royalty and even dropped in with New Hope strike squads. They weren't brash enough to have claimed to pierce the veil in Asia, but oh yeah, they had been deep into the Wild on corp missions. Seeing strange beasts the size of houses and entire fields of waving black tentacles. Never mind, no corp team would take on mercs except as cannon fodder.
They switched watch and settled into their quiet watch. Leon didn't like to talk much on the watch, which suited her. The first few days, she had been distant with the crew, but that first day had cracked open her shell a bit, and over the last two weeks, she felt a bit more comfortable around them all. Leon's quiet watches with no questions or enquiries and just time with her thoughts were a big part of that. They were relaxing. Even here waiting on the border to the dangerous Wild, she couldn't help feel at peace.
True, the nights were cold, and the darkness was often terror-inducing. The moon had been approaching full, which gave her more comfort. She always liked the moon. Today's watch was lunch to early evening, so no moon watch. Though out here, the moon seemed ten times bigger nestled among the stars, she never knew the sky was so detailed. Always a muffled black in the city with the moon a hazy haunted sight.
About an hour into watch, Sarah came up from the stairs. Generally, they tried to avoid opening the Tube top when they could let out too much from the vault despite being sealed in stages. So the lounge ladder was the usual way up. She dropped down a container with some fruit and buttered flatbread. Sarah looked a bit upset.
"Pickle, you were meant to report for a medical inspection. I was waiting for you."
Pickle's response was sheepish, "Oh sorry, forgot, Leon had me training."
"Do not give me that. Did she tell you Leon? Captain ordered a full inspection."
Leon quietly raised his eyebrow before going back to looking at the tree line through his hand scope. Sarah took this as confirmation for her point.
"You are coming down straight after shift to have a full inspection. Got it?"
"Yeeeees, doctooor," Pickle answered, elongating her words with compliant sarcasm.
Satisfied, Sarah climbed back down and went back into the base. Pickle couldn’t but help smile as she left. She felt in many ways Sarah was her best friend. She had friends and allies in the club or with Jack Jack's boys, but almost everyone had an angle. You worked with people because goals aligned. Sarah was so obvious in her moods and without guile. Her friendly attention seemed genuine, and while Pickle was still on guard around everyone, she felt like she could at least lessen it around Sarah.
Nibbling the fruit as they watched, she saw Sarah had slipped the magazine she had asked for under the fruit container. Staying attentive for five hours straight without some pretty extreme exhaustion is almost impossible. So when on blue status, or all clear no fear as Leon sometimes joked, they took turns. They both watched, but one person would really watch eyeballs on and scanning the treeline until they tapped out and the other person switched in. There was no fixed time for this, and they just felt it out. Her first few watches she had tried to show she could do it for long stretches. Leon relieved her without asking, and even then, she was exhausted from stretching herself.
She hadn't mentioned to Gunther, but that snake that Leon had killed had been on her watch. She had missed it until he had spotted it. Still, a point of shame for her as she was meant to be the one eyes on. Now she was more willing to tap out sooner and stay more alert when she was on.
The magazine was an interesting gossip rag mostly. The guys and gals and the club were always slinging them around and joking about bedding princes or trust fund kids with their private shuttles. The fantasy for most back then had been a wealthy patron, in her experience, that was a trap. Still, the fun what-ifs and celeb gossip flew through the changing rooms.
From the Madame to Vindaloo or even the darker characters like Winston Surrey, the bad boy of British royalty, gossip and speculation were always hot commodities. She didn't know any sim heads, but one of the club girls had gotten wired for some stim porn work. She said all the celebs had finely tuned and edited sims, but the real sim heads hunted leak master recordings. Unedited stims. Illegal as hell, of course.
Felina was supposed to be different. She doubted the famed singer with her cat-like features and tail would be releasing raw stims, but her whole brand was about being authentic. Sarah was obsessed with this stuff. Having grown up mainly on the wall, even every day sounded fantastical to her at times. Pickle laughed at some of the strange ideas that lady had. It was adorable.
The thing that had really caught her eye when they were flicking through them yesterday was the interview with Felina. Apparently, she had just done a concert with PsyCow, and that was an underground name. No one knew their true ident because they always appeared at shows in holosuits, but the rumours were rampant. She had been obsessed with this shape-shifting DJ musician and his crazy shows. She had attended a virtual as one of the flesh dancers when she was much younger, young enough for a particular crowd. The job was awful, but it was her way into the club and to escape Jack Jack. That night she had gotten lost in the music.
She had since listened to all of his electronic heavy metal psychedelic mixes but never again had she quite captured the energy of that night with the live performance. The interview, unfortunately, was not much about PsyCow. The interviewer was going after the meta-human angle. Full-on fluff piece talking about meta-human rights and her story of growing up as a shifting meta and not part of a tribe.
The interview followed the same boring tropes of self-discovery, changing body and empowerment that riddled these puff pieces. Pickle found it disgusting to read. She had known a few shifters growing up, and they were all dead or gone now as far as she knew. Sure she had met a few tribals in the club, but she could count on one hand the number of adult shifters she had met. They all had dark tales. Even if they didn't share them, you could see them in their eyes.
Annoyed, she closed the magazine and stood up. She tapped Leon to let him know she would take watch. She started pacing between the two spin turrets on either side of the tower. She didn't like sitting in them, especially after relieving the balls as they spent their entire shifts mostly in those chairs, and the stink from their fat arses just grossed her out. She grabbed the central ballista and swivelled it, scanning the treeline.
Those damn journalists and paparazzi. What did they know about anything, writing their little glam pieces? Printing their edited photos and sim all clean and pure. God forbid they talk about the agonising pain of bones cracking or the looks from strangers. Sure, most people shifted a little. Eyes, or marking or strange hair colour or skin. But no one talked about the day or sometimes week blind and the strangeness of the world afterwards as your sense of colour or light shifted. No mention of wanting to rip your skin off as it itched night and after night. The horrid nightmares of ripping out your own body. Fucking arse holes.
She wished she could drive a ballista bolt right through them. Bloody airheads like Sarah just going, isn't it so exotic. Fucking no clue.
Just as her rant started spiralling into a maddened fury of disjointed rage, her train of thought was derailed. She saw a few trees shake. From behind a trunk emerged a strange dark grey shape. It lumbered not on all fours like a cat or dog but with a peculiar gait. It looked about the size of a large child or small adult. Walking with a crouch but using the nubs folded wings. Not leathery or feather but scaled and interwoven. Its head on the end of a long snaking neck sniffed the air, forked tongue flickering out to taste it.
"Leon, one O’ clock ground. Small and alone."
Leon jumped up and sighted the creature. Barely pausing before saying in a steady voice, "Center mass. Kill shot now."
Feeling the rage wash away from her, she breathed out and refined her aim of the oversized crossbow. The ballista was narrow in design but powerful. She wouldn't need to account for wind or much drop at this distance. Putting the sight slightly above its centre mass, she fired. The large iron clay javelin flew fast and true. Spearing the creature through its centre.
The large shaft pinned it to the earth, and it writhed and screamed for a second, burning smoke emitted from the wound. It looked foul and toxic, like it was staining the air.
Leon confirmed the kill, but before it was done writhing, he flicked the tower to red status and tapped out a message on the keyboard. Sending before returning to watch and sitting in the right turret seat.
"Reload and watch."
She quickly complied. The ballista used a small auto winder powered by a spin drive to pull back tension. She pulled off another ironclad javelin and placed it in the firing position as she heard Leon bring the turret up to idle, then hot. The first time the turret had run hot since she arrived.
Before she was back in position Gunther was climbing out of the Tube with his gatling gun. Followed by the Ball twins, one of who quickly moved to relieve Leon so he could pick up his rifle. Ka emerged onto the roof with Sarah. Only Fred, the Geek and Malcolm were missing. Wait, Malcolm was combat. Why was he missing when even Sarah was on deck?
The Ball twins were swearing under their breath as Gunther clicked his gun into a mounting point and ready it. It was then she noticed that while Gunther and Leon were scanning the ground like she was. The Ball twins were watching the sky.
"What did I just kill?" Pickle asked with her voice shaking slightly.
"Adolescent Wyvern," Leon answered in a calm tone.
Then in a much quieter voice dripping with fear and frustration but not quite enough, Brian muttered under his breath, "Baby fucking dragon."
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 5
Pickle on the Nightmare Wall - Part 5
The Ball Twins
"Lock it and stock it." Gunther's voice brought her back into the moment as Pickle looked around the echoing underground train platform. The room was just long enough to accommodate the open train on rails with a small walkway upfront with a glittering bronze shaft perhaps two meters across running from floor to ceiling. The ceiling almost ten meters high above them, hard to tell with the low lighting.
The room was clad in poured concrete reinforced with dark iron ribbing and I-beams. The thick metal beams ran the length of the ceiling. To either side was a hard polished wood flooring covering the train platforms. The odd mixture of materials made her pause. The wood wasn't elaborate though it wasn't cheap exposed timber. Some dark heavy grain had been finely jointed and stained but was now dusty and well worn. Functional.
A large fluid tank of some sort squatted in the right back corner with piping run off into the ceiling. Two pairs of large doors on either side into other underground rooms. To her left was the console now being operated by a middle-aged man with dark black hair curly and thick in contrast to his weathered face and scrawny build. He wore a faded blue coverall with tools and pockets attached to every flat piece of fabric or obvious mounting point. As he pulled with both hands on a large level with a pressure handle grip, she heard the clunk and whoosh of mechanical systems. Slowly with less noise than expected, the large metal enforced started swinging shut to close in the room.
Walking over from the console with a friendly gait was the tall hunter who had greeted them. Smiling, he swapped greetings with Gunther pulling him up and in a hug. "Good trip, old man?"
"Good enough," Gunther answered with a warm smile that seemed out of place on the gruff man. Gunther stepped up onto the platform, surveying the train for a second. The tall, toned man next to Gunther was clearly an outdoors type. He had a silly soft hat with a wide brim folded in half stuck in a strap on his shoulder. His outfit was well made but worn, made from tan browns of subtle shades. The yellows and browns of a dry veld went well with his caramel skin. It was hard to tell how much of his colour was sun-kissed vs natural tone. He had a friendly smile like a big warm cat welcoming home its family but licking his lips at dinner as his eyes wandered over the train. She watched their conversation fascinated as the hunter's eyes returned to Gunther with a question.
"Trouble?"
"Maybe, Frank got Scraps' call about the Stalker," Gunther paused for a second to see the Hunter nod before continuing. "Well, the glider is back as well."
"God damn rip off," the old man threw into the conversation, pausing to sip from a mug. "Bastards trying to copy my idea without understanding it. Going to rile up the neighbours."
All men nodded sagely, the wise old men complaining about the antics of children. Gunther looked back at the train and started issuing orders.
"Ka, Scraps and Doc help Frank get the stock away, and the crane fitted. Scraps scoop on the way back. Girl, come here." Gunther waved Pickle over. She rushed over to the men, giving a rough salute which she had seen corp troopers and some mercenaries give. The old man lifted his cup, and the hunter gave a sharp parody of a salute. They all gave each other a look before chuckling. She lowered her eyes. Feeling the energy drain out of her.
"Now now, don't make fun of my kitten." She felt Malcolm's metal-tipped glove fingers rest on her shoulders. Firm and unwelcome. She was unsure if they were holding her down or up, but she knew he would be smiling. Gunther grunted, "Pickle here bought a stake. She is company now."
That changed the mood of the two men. They paused to really take her in. Both seemed to perform different calculus in their head as they inspected her. Before they could pronounce, the summation of their mental weighing Gunther continued. "Pickle, this is Frank, chief engineer. He runs this tower more than I do, and that there is Leon. Best point man on the wall. Leon, take the girl up top and keep watch while we unload. Get a gun in her hands, would you."
The old man had given a modest who me at Gunther's compliment. While Leon simply nodded his head at Gunther's assessment of his abilities. Leon gave a quick last hug and welcome Gunther before glaring past her shoulder and turning towards a large metal ladder. It was sunk into a concrete column running all the way to the ceiling. Just by the wall between the console and the ladder was a big flat open freight elevator. Just as Leon's boots touched the ladder, she felt Malcolm's hands give her a nudge forward to the ladder, his silk voice directed at Leon. "Take care of my new apprentice cookie."
Following after Leon, she started to climb up the ladder. The rungs were worn and cold but had worn grip tape, which showed signs of being replaced frequently. The ceiling was higher in the centre. The wall to ceiling height was much less, but the ladder didn't end at the ceiling. Instead, it extended up a cold concrete shaft next to the elevator until it reached about the same height she guessed as the peak of the arch. The dark cold shaft was unfamiliar to her. In an age where monsters wandered the dark and the wild was not just a tale of children but an existential threat, most spaces were well-lit. Even poor houses were well lit with cheap LEDs. Though as she climbed near the dim lamps, which illuminated the shaft with warm yellow light, she noticed a flicker to them.
They were dimmer than any light she had seen before, faint enough to see the led inside. She was used to bright lights, but these dim lights flickered like a fireplace or the candles from the nunnery. She found herself fascinated by them, only to have her inspection interrupted by a screech of metal as a trap door was opened by Leon above her. Realising she was lagging behind, she climbed up the last few rungs quickly to catch up.
As she stepped into the corridor, he closed the trapdoor behind her. Quickly opening a small door to his right. The door was reinforced metal again with a sense of weight which was not visible when it was opened. They walked out into a small open plan kitchen. It was well organised but used, strewn with reusable containers and labelled cupboards or containers. It immediately gave the sense of being an office kitchen, or at least that was her closest point of reference. She could see the labels and the passive-aggressive questions about who ate what just echoed in its labelled containers.
Leon didn't slow down for her or explain as they walked through a lounge area. Old chairs around a wooden table, bean bags and a small shelf of books. The light in this room all coming through long glass skylights set into the ceiling. The ground was covered in layers of shaggy rugs and worn carpet. Doors leading off in a bunch of directions the layout of the room pointed at one key point. A small ladder leading to a trapdoor between the two long skylights. Leon climbed up and lifted it open, letting more sunlight pour in as he climbed onto the roof. She quickly followed.
After the darkness of the underground train platform and then the lightning quick cut through the building, she was momentarily stunned by the bright sunlight. The ladder roof access was actually covered by a canvas roof pulled tight between some poles but the small shield gave little reprieve from the midday sun. Taking a moment to adjust she saw Leon stretch like he was finally comfortable. Pushing his hands into the small of his back and stretching out.
The roof was concrete but looked extremely lived in. Small patches of stretched canvas provided covered shade in various spots. A small table with four chairs, a stretch of fake grass carpet, a well used putting practice pitch. Small garden boxes dominated the roof, with a small greenhouse towards the back of the roof. The layout of the room was a squat capital T or a plus symbol without its top. Wider than tall, the wide face was presented out towards the front. The back section ran between rocks lifted up, a small kopje provided natural cover to the building. The back was home to the large rooftop greenhouse as well as a tall water tank.
Finally, the largest element on the front was a tall wooden watchtower atop metal beams. The weathered metal beams looked of the same sort which reinforced the train platform below. They seemed overlarge for the wooden watchtower with its wrapped wooden steps leading up. The strangest element was the bronze tube, two meters across, which she saw in the train platform below. It extended all the way up and to the top of the watchtower.
"What gun's you fired before Pickle?"
"Um a bunch, though most familiar with punch and needle guns."
"Small arms, high tech." Leon was unimpressed by the roster. "Anything larger?"
"Fired mag and plasma but not much. Just to try."
Raising an eyebrow Leon appeared to be adding a mental notch. "Well, spin rifles are our bread and butter though you need something to complement it. We can worry about that later. For now, use this until we train you on spin rifles."
Leon pulled out a small crossbow and a large rifle, he handed the crossbow to her. It had a rack of small bolts strapped to the side. She turned over the weapon which was well used. The tension pull was a wheel with a strange mounting she wasn't familiar with. She gave the wheel a few turns, slotting in one of the metal bolts and checking the safety was engaged. She slung the shoulder strap over her head looking to Leon for a cue. He was nodding.
"Lekker, maybe you do alright. Now let's check up on the balls." He was walking towards the tower before the sentence was finished. Climbing the wide winding wooden steps. They were comfortably wide and at a push, she could see two people crossing mid-climb without danger, though it might be tight. As they were climbing Leon added, "The balls are mercs, good ones but don't let them rib you too hard." He suddenly shouted up, "Ja kaks, all clear to climb?"
Two boyish voices answered from above, "Blue skies."
"Who is the girl, shore leave?" Chuckles from above punctuated the sentence with lewdness she was all too familiar with. Leon shook his head while finishing the last bit of the climb. She followed up after.
The thatch roof covered the heavy stained wood with a small railing around the edge which extended out from the base. The centre was dominated by a strange metal hatch into the metal tube which seemed to run through the building. Fat cables ran out from the tube. A small control console just to the side of the tube was decorated with physical buttons and switches. The other tubes ran out to either side to two large mounted weapons by the railing edge. The guns were on a swivel and the high tech nature of them seemed out of place. Oversized, these guns shared the bulky coverings she had seen on Gunther's rifle. Their long barrels and bulk appeared to be finely balanced. The umbilicals leading into the depths of the base.
The large weapons were offset by two short young men, they looked boyish and impish. Both wore baseball caps with a large letter B machine embroidered on the front. One of them wore a faded t-shirt with a complex gothic script forming a faded logo of some metal band. Copper Cow. She had never heard of them but they sounded foreign. The other boy wore a shirt of a cartoon head with robot red eyes and in place of hair a toaster had been drawn with two burnt pieces of toast popping out the head. Without blinking she knew the back would read, Heartbeat Required, Ghost Busters or No Robots. Some similar slogans from the anti-Phantom brigade. They both also wore silly grins of children, though both were in their early twenties.
"Who is the chick?" The left one asked.
"Brad and Brian this is Pick. She is company," Leon answered.
"Ooh fancy, and here I thought she was the entertainment."
"Don't mind my bro Pick. Always good to see another human on the wall."
She breathed in, feeling like her voice was unused to everyone speaking to and around her. Running her tongue around her mouth she answered. "Um thanks, actually my name is Pickle."
"What like the food?" Brian asked.
She nodded.
"Well, fuck ain't that strange."
Leon was glancing through the scope of his rifle, looking over the edge searching. Leon's voice was quieter with the weapon raised. "Anything?"
"Nah," Brad responded, spitting over the edge. "Not a peep."
"Captain wants us to go to green. Glider is back."
"Fuuuuuck."
They both went to their guns and started searching the treeline. Pickle walked up to the railing and got her first real view of the wild. Her first thought was how beautiful it all was. The unbroken forest and veld mixed into the clear distance. Blue skies stretched across the horizon and it looked peaceful. She could see birds in the distance but no other wildlife.
The ground around the base was mown grass. It was kept trim and clear for perhaps seventy meters until the treeline started. The undergrowth and thick trees cloaked darkness which in the afternoon sun was hard to make out. The afternoon autumn sun hung lower in the sky glaring in their eyes. The wall faced north towards the equator so the shadows looked like fingers stretching out trying to touch them and pull them into the dark shadows of the trees.
On either side of the base, a woven wooden wall stretching three meters high stretched off into the distance to the left and right. She was tracking it with her eyes into the distance when Leon's quiet voice asked, "Can you see the demons?"
"What, demons. No, just trees and some birds."
"Look at those birds again," he handed over a small pair of binoculars. They were simple glass in a carved wooden frame with small pieces of leather. She held them up to her eyes. There were no digital readout or controls she could see. She squinted, trying to get them in place. Searching the sky for the birds, looking past to get her bearings and slowly panning to find the flock. Her breath paused, in her throat a hard lump.
They weren't birds, and they were a lot further away than she thought. Leather wings flapped, not entirely there, with an edge of shadow. The seven birds were each the size of a large car, and not a feather was among them. Long stretched beaks crudely extended from their body and small tails protruded out. Large talons looked oversized on the creatures. She thought their faces looked stretched from screams. It was then she realised that she could see their faces. The lump dropped from her throat into her stomach, heavy as a boulder. They were flying in their general direction.
Looking out from the zoomed view, she looked at Leon. He shook his head, heading to the console, he pulled out a keyboard. Typing out a message and then slammed a button. The boys were glancing over their shoulders over at Leon. He looked back at them, "I don't think so. I think MedPoll will pull them. Keep sharp we stay Green."
This satisfied the boys as they returned to scanning the treeline. Pickle confused, asked, "Green?"
Leon pointed at the console pushing the keyboard back into the console. On the top panel, a small dial dominated with a colour wheel. Blue, Green, Yellow, Red and Black. A small keyhole was next to the dial. Various toggles and switches took up the rest of the console. The dial was currently set to Green.
"We are here for the long haul. Can't be on our toes all the time. So we have alert levels. Blue is nothing sighted, all clear. We have two people on watch at all times but on Blue only one person needs to be eyes on at a time. We are Blue most of the time. Green is danger sighted." He pointed at the birds. "Don't be afraid to take us to Green. It means both eyes on, and a third person will come up to check in. Also, you should send a notice down on what you saw as soon as you can."
Leon pulled out a mechanical keyboard with wooden keys from the console. There were also fewer keys than she associated with a keyboard. Only letters and numbers with a space and return key. There was no screen or readout she could see. There was a small laminated label with some codes printed on it.
SOS - Send help
MDC - Wounded
TCK - Tech Broke
The list went on to list about 15 shortcodes. Then handwritten in sharpie were a few others much less formal.
AMM - Bring Bullets
FUD - Feed me
PIS - Rain
POO - Bucket run
Pushing the keyboard back in Leon continued in his explanation. "Yellow is engagement likely or engaged. For when the fighting is about to start or going on. On yellow everyone is up and alert unless on rest shift. We operate four shifts, can explain that later but on Yellow you need to know where your gun is even if you're not up top and unless you have a reason not to be we want you up top. Finally, Red is full attack, restrictions are lifted and everyone must be up top to fight." He pointed out towards the sky. "We are yellow because those demons will likely hit Medpoll, our neighbour. They could turn at any moment so stay alert."
With that Leon returned to the railing, inspecting the flock closing in. A gentle breeze blew in the cold air counter to the warm sunlight. She watched the large beasts flap their wings and draw in closer. When she realised something, "You never said what Black was?"
Brad quipped from over the barrel of his mounted gun. "We are fucked."
"Black is bad," Brian repeated.
In a calm voice, Leon clarified, "Black is bunker down or retreat as we call for aid. Only the Captain or Malcolm can call Black. If we go black, the tower is dead, and our neighbours or Heaven step in to seal the breach."
The tower went silent then as they watched the creatures approach the MedPoll tower. Its white tictac tower loomed on the horizon, waiting for combat. When the flock was still far beyond the treeline, suddenly two of them got yanked back into the sky up high then suddenly plummeted, the ragdoll form twirly and tumbling, breaking the parabolic course into more of a downward scramble. The remaining flying demons sped up to maybe twice their previous speed pin pointing on the white tower.
Thud, thud. Two more fell out of the sky. Pickle searched for a puff of smoke or the crack of a gun but there was nothing, just sudden destruction of the approaching threat. One missed as a bird demon dodged, tearing up its wing instead of the centre mass. The blood-soaked projectile which ripped the wing off was now clearly visible in its tumble. Whatever it was, it was solid and heavy with a ton of force behind it as the tumbling viscera flew off. The wounded beast flapped its one remaining wing, losing height to the tree line, before vanishing below and into the dark.
Suddenly the last remnants of the flock swooped down towards the tower. This time met with a rapid-fire, smaller fire ripping into them. Before they fell to the turf, black nightmares no more. Defeated and crushed on the wall. Pickle was impressed by the sheer efficiency of the weapons.
"Foking domkops. Kak. Shielded or no, that mag rail is going to get us surged one day." Leon cursed.
Brad added, "Well it saved their butt, though it was prob robots who fired it."
"Nah prob Toasters," quipped back Brian.
Leon cut them off. "Doesn't matter, we stay green. Half a mind to go yell."
This cut the mood and the boys focused in on the treeline. Scanning for incoming threats. The minutes stretched as they searched the treeline. Pickle sighted down her crossbow. She saw some rabbits grazing the long grass near the trees, a squirrel running along the branches. The forest wasn't still but constantly dancing in the wind and alive with small motions. It would have been dull but much less anxiety-inducing to watch a bare patch of ground instead of trying to pick out the danger from the chaos.
Following the motion of a bush, she saw a bush shake a little. Then she saw a set of twisted horns poking out from the wood. Before she could say anything the head popped up and a large kudu eye stared directly at her with its face side on. She watched as the creature chewed. A noise from the forest made the kudu raise its head and suddenly, a blast of air was felt to her left. As she registered it she saw a bolt the size of a small javelin stick into the tree beside the buck as it suddenly leapt out onto the grass and tore away to the right before jumping back into the tree line further down.
"Fucking Kak for brains, why did you shoot at a kudu?" asked Leon his voice shaking with rage.
"Sorry man I saw the horns and it was moving fast so I thought it was a threat," Brad answered.
"And you, shit for brain monkey missed?"
"It was moving fast, bloody thing is on the tree line. That's a long shot cold."
"Stupid and incompetent. You are retrieving that bolt."
"No way Leon, it's just one javelin."
"One javelin your stupid arse fired at a bloody buck. Fetch."
Grumbling, he stepped back from his gun, flipping on a safety.
"Pickle go with Brad. He needs someone to clamp the wire."
Brad picked up a rifle with two strange drums a larger one below the barrel and another smaller one just above the barrel further down. Slinging it over his shoulder. Heading down to the rooftop with Brad cursing the entire time as Leon took over his sentry post, they climbed down the wooden steps. The rooftop was surrounded by a small outcropping and low wall that stopped things rolling off, but she supposed it also stopped climbing critters. Brad took her to a section where he unclamped it and folded it onto the roof like a trapdoor opening towards the open air. Now leaving a gap in the outcropping defence ring. Brad picked up a black rope on a pulley system with a yellow handle on the end. The rope rang down into a drum along with two other similar arrangements. Brad explained.
"Now I'm going to be climbing down with this under tension. There is a little hook at the bottom, so I can latch it. The cord is tight," he tugged on the cord, showing it pulling back hard. "Now I can pull it but easier if you just pull the clutch here to free it. Let me climb down and hook then I will tug for you to push the lever back so the cord is tight. Got it?"
Pickle nodded, "I think so."
"Bloody better." Pulling on what looked like a whammy rod on a guitar mounted on the stock of the strange rifle. She could hear a quiet whirring noise as something sped up a little bit. Before nodding, he pressed the lever back and the sound ceased. He started descending, gun slung over his shoulder, down the wall for the two floors down to the ground. Securing the hook as mentioned before tugging it. She pulled the level feeling the cord pull tight. Curious, she went to the edge under the tower's shadow to watch his progress. He walked with his gun up, the rifle pulled strangely, as he turned to look around. Steady but fast. Not running but proceeding at pace.
As he walked forward, she noticed small red circles of laser light projected down from the tower. The laser light hadn't been on early and it painted the small red circles, all of which Brad seemed to avoid. Until finally, he reached the tree line where his large bolt was sunk into the tree trunk. Pulling out a small tool it looked like pliers but with a pair of doughnuts with a gap. He slipped the tool over the javelin sized bolt.
Closing the tool, it pressed against the trunk while clamping and pulling on the bolt. It yanked out the bolt out with a loud crack. Putting the tool back on his belt Brad held the bolt up like a trophy looking back at the tower. Walking back to the tower with the bolt he started playing around with the bolt and making fun with it. Hamming it up for the watching audience. Suddenly a tiny black cat bolted out of the tree line darting for Brad. Pickle yelled out a warning waving her hands. Brad blanched, turning around to see the kitten sized creature charging at him. He dropped the bolt reaching for his weapon, rushing to ready it. Slamming it in frustration.
The cat was a bit larger than a house cat, but the tail wasn't solid. Rather, it was a smoke wisp-like a tail swishing invisibly but leaving a smoke trail in the air where it was moments ago. Claws out, it landed on Brad's chest as he screamed and flailed with his gun. Pickle drew up her crossbow, trying to take the shot. Before she could bring it to her eye she heard a muffled gunshot from above. Moments later the creature's head exploded.
Brad stood there screaming with the hanging headless corpse hanging limply on his chest. After a moment of screaming, he reached onto his chest and ripped off the remains throwing them to the ground. He started stumbling towards the base. After moments the stumble turned into a run. Pickle watched with horror as his stumbling run stepped on a red circle, she held her breath, as he continued running. Nothing happened.
Brad slammed against the wall, pulling the handle off the hook, letting the tight cord drag him up the wall, over the edge and onto the ceiling. As Pickle pulled up the cursing and swearing man she saw blood smear his chest and his face was speckled with black muck. The smell was intense, burning and sickly sweet.
"Fucking cat," Brad's voice was broken and harsh. He started pulling off his shirt over his head. Wiping the muck with the crumpled bundle. Small scratches welled up red on his upper chest and some by his stomach. The wounds looked surprisingly shallow but were angry and welting.
Before Pickle could fully register the scene, Sarah was there. She was pressing Brad down, reassuring him. "Brad, count off to five." She pressed his head down so he was looking up. "Pickle his head, hold it." She grabbed his head, it felt warm.
"Fuck. Five, Four..."
Sarah was pouring water on the wound. The water touching the wound instantly steamed. Brad screamed his head pulling up against her hold, she pressed him down. Sarah wet a cloth, "It is okay, just need to clean the goo. Going to patch you up." She went to clean off all the dark material and blood. Reaching into her pockets, she pulled out a thick square. She pulled it apart and then slapped the thicker half onto Brad's chest with a brutal force. The moist slapping noise was accompanied by a heavy grunt from Brad as all his muscles tensed.
Pickle saw the veins around the patch swell as chemicals sunk into Brad's body. Sarah was now pulling out wadding and bandages, things familiar to her as she went to tend the wounds. Brad went a bit looser as the painkillers in the patch started their work. The work blurred until Brad was lying on the roof, topless surrounded by discarded single-use wrappers and medical debris. Sarah handed Pickle a wet wipe.
"Here pumpkin, clean up any of that goop. Not good to leave on your skin." Sarah quickly followed her own advice wiping herself down. Pickle washed her face and hands, seeing the wipe come away with a mix of blacks and reds. The smell of that sweet sickness was on the air. Looking down she saw Brad was unconscious.
"I knocked him out pumpkin, he did not need to stay awake. We are yellow."
"Will he be okay?"
"Yeah, big baby. Just a wisp cat scratches but you can never be too careful. Wild wounds tend to fester if you do not clean them right away. I should not call him a baby, they hurt to high heaven."
Pickle looked out to the brightly light scenery with a new horror in her belly. She thought back to the holos and fics about the wall with their great beasts and brave combat. The epic combat and action scenes. Nothing had prepared her for this brutal truth, it was the street writ large but she didn't know the rules. She felt that thick ball of anxiety in her stomach dissolving into writhing anxiety rising through her body. She felt her skin start vibrating as a high pitched whine built in her brain.
"Pumpkin," Sarah rested a hand on her shoulder. "You okay?"
Looking up she saw Sarah face swimming in red hair. Her freckles and green eyes looking at Pickle. She couldn't meet them, looking down at the ground. She pulled in her strength as Doc lifted her up to her feet.
"Come Pumpkin let's get you lying down."
She woke up looking at an unfamiliar ceiling. Her head was thick with fog. She hadn't been drinking, had she? The openness of her position sent a jolt of panic through her body. Still paralysed by sleep her normal instant alertness slipped out of her fingers. As her eyes darted around the ceiling, she noted the concrete ceiling broken by two thick slits of glass making long skylights. The glass was mattress thick and reflecting dusk or dawn light. Small lights in the room dimmed against the flooding sunlight. Her bed was in the corner far from the entrance.
Looking around, she was lying on a small bed with white sheets and a brown cotton blanket tightly wrapping the bed but she was lying on top of it. She was still fully dressed but her shoes were missing. Reaching up she touched her helmet, it was still there. She didn't see anyone else in the room. She sat up on the bed. Seeing her shoes with socks on the floor made her feel better. Her bag lay at the end of the bed, with the familiar small folded packet. The clothes the girls had bought for her before leaving.
The last day swam in her mind. Less than twenty-four hours ago she had pulled off the biggest robbery of her life, enough to start a new life. Buying a stake in a defence company working the wall, run by the man, the legend, Gunther the Gun. She had travelled to the edge and seen the wild. A small ball of emotion raised up in her throat. She swallowed it down with the memory. It didn't feel real.
Looking around the room she saw it was a large dormitory. The corner across from her was decorated sparsely with small tokens from beasts. The space was neat and organised with the most noticeable thing being a small glass fishbowl filled with smooth rocks. A multitude of colours. There are no precious stones, just regular pebbles like one would find in a river but a rich mix of colours and shapes.
The corner on the other side by the entrance was the most standout. It was a mess of tossed clothing, posters and some dirty plates and mugs. The beds were stacked on top of each other, making the only bunk bed in the dorm.
The other beds were made up like hers with no distinguishing marks other than some belongings and bags stacked at the end of the bed. She could tell from the bags who had claimed which bed. Seeing her immediate and only neighbour had been taken by Ka'Shek. His large duffel bag with its tribal patches was immediately noticeable. The next bed over had the small neat travel case on the end, the geek's bed then. The door itself wasn't a door, but layered material cut into strips in a thick design. Muffling light and sound from the outside. It was an impenetrable barrier to light and sound.
Pulling her shoes back on she noticed a locking trunk at the base of her bed. Thinking back to what was in the bag and her pockets. She didn't know who had a key to it, other than the key in the lock so she didn't trust it. She didn't want to put people on edge by appearing too private. She resolved to leave her bag on the bed, like the others had. Heading to the door she pushed the curtain aside.
Sitting on the sofa she saw Northcott, he was writing away in a small notebook. Busily scrawling away in his strange handwriting.
"They are on the roof," he pointed to the ladder to the roof. Quickly returning to his scribbles. She took in the room, this time she wasn't being rushed through the building. The bookshelf had a range of books on it but she also saw some boxes with colourful titles on them. To her right was the open plan kitchen, several dirty plates were stacked in the sink. The left wall had thick glass viewing windows showing a concrete stairwell with the bronze tube running through it and a thick metal reinforced door.
Turning around she saw it was the same type of door as the one that had led in here from the train platform. Looking back at that door on the same wall as the bedroom she noticed another reinforced door. She also saw that across from the dorm were two corridors. One led off away from the dorm, while the other led off along the kitchen. She saw several doors. It could all wait. She eyed the ladder up to the roof and climbed up pushing up the trapdoor.
She was immediately greeted by happy sounds as she stuck her head up, a cheer went up as she emerged. Happy laughter filled the air. The moment she was up and out a happy shirtless Brad came over to hug her.
"Pickle. You're alive."
"Um yeah, you were the one attacked."
"Oh. It was a pussy tat. He went scritchy scratch on my chest." The tipsy man stumbled back, pointing at his bandaged chest. The layered bandages looked like a noughts and crosses board on his scrawny chest. Surprisingly she smelled no alcohol on his breath. Brian came over and took his brother by the shoulders. "Come on Brad, let leave the nice lady alone."
Looking around the roof she saw a set of folding chairs set up around in a small circle. Brad being led back to them by Brian. Frank, Leon and Sarah were all chatting in a circle sitting in them while Ka sat cross-legged with tight animal skin and a bone needle stitching a design into the stretched hide. She walked up to greet them all. As she approached, Sarah grabbed a small tupperware and handed it to her.
"Feeling okay Pumpkin, getting knocked out twice in one day. Quite the start."
"Yeah, you could say that," she admitted.
The tupperware had a small wooden fork strapped to the top. It held a bunch of lukewarm curry and veg. Popping the lid the warm smell of onions and tomatoes filled her nose. Stirring it she let the conversation and laughter wash over her. Brad laughing much louder than the rest. She glanced over worried at him. Sarah caught her eye and winked, leaning over.
"He is still enjoying the pain killers I gave him."
"Ah, is he going to be okay?"
"Yeah. Mist cats are mostly harmless but they claw through almost anything. But they are mostly solitary. Still, the goop is dangerous. He will be fine."
"Is it okay for us to be up here making noise?"
"Yeah we are back in Blue. Besides Gun and Mal are on watch we could not be safer."
Looking over at Ka'shek she looked at him working a complex design into the stretch hide. Ka was pulling a bone needle through working a shiny silver thread into a complex design of sharp symbols she couldn't understand. She quietly ate her curry listening to the twins joking about as she watched the needle pull and poke. Slowly the design layering onto itself, growing in complexity. Watching the complex pattern grow she gently asked, "Ka what are you making?"
"I am weaving a ward of protection and hearth into the hide of this Wildebeest. It will protect my dreams and guard off evil spirits as I sleep. One cannot weave powerful hearth protection when travelling." Ka paused as he knotted a thread and clipped it. Pulling out another slightly different colour thread holding it up to the light as he rethreaded the needle. Pickle watched fascinated in the process as he tied off the length of the thread.
"Ka?" she waited for him to register her question, he gently hummed his acknowledgement. "So is it a thing you wear?"
Before Ka could answer Brad stumbled over, "It's his blankie, the big green giant is scared his brothers are going to come fuck him in the night."
A chill silence ran through the group. As Brian grabbed his brother, "Hey let's go grab a drink?"
"Don't give me this shit, why are we protecting people from monsters with fucking monsters."
Pickle watched everyone eye each other. Ka ignored the barrage continuing with his needlework. Sarah and Frank looked angrily at Brad while Brian looked around worried at all the faces. Brian tried pulling his brother away to the ladder. "Come on bro, you need a drink."
Brian pulled him away towards the ladder, carefully helping him down the ladder into the lounge. Frank looked the most awkward of all of them remaining.
"Sorry you had to deal with that Ka, he normally is better at holding his tongue." Frank was fiddling with his mug nursing the coffee looking worried at Ka'Shek. The orc continued working his needle leaving a silence in the air until he poked a new stitch then looked up at Frank and in his kinda melodic deep tones answered.
"We do not entertain fear or its weakened cousin of hate. Many slings have been fired at my people as the nightmares of the world have turned cowards to throw their stones at those who stand tall in this age. Many of the tribes worry and let their own fear exclude them but I choose to wander into the world to collect the good and bad. Even little men and their moods."
Sarah seethed at Ka's gentle and thoughtful response. "That is complete bullshit Ka. You should not have to nurse their feelings or my father's. You have a right to be angry at those idiots. Why Gunther hires them on I will never know."
Frank looked even more embarrassed as he responded, "Well it's hard to hire. The tower needs men." He paused awkwardly looking at this daughter and Pickle. "And women of course. But it's dangerous. Most sign up with the bigger towers. Not many free agents who are prepared to go low emission."
Sarah looked mildly less upset, "Still it is wrong. Plain wrong. I am glad they are not company."
"Wait company?" Pickle asked, "Someone said that earlier. I thought everyone on the tower was company?"
Frank shook his head, "No most on the towers are hired hands. Some like Ka have tribal associations which means they can't join. Others don't have the credit or trust. You are the first new company stakeholder we have had in seven years." Sarah was nodding enthusiastically as her father went on, "Sarah was born into it. Gunther and Malcolm hired me on to retrofit the tower. At the time I was one of the designers on the original wall project. This is one of the last remaining towers. I joined the company not long after with my wife. Leon and Willy a decade or so later."
"So why did Gunther let me just buy stake?" Pickle asked a little bit angry at her complete lack of understanding. Sarah and Frank looked at each other awkwardly. Frank looked back at her, paused then took a sip from his mug before staring into the mug considering. He slowly answered.
"Well, I can't speak for the Captain. He has his reasons but he must have seen something in you."
Her mind reeling at this response her brain popped a fact up from the depths, "Wait you said Gunther, Malcolm, Leon, Sarah and you... what about Scraps?"
"Oh no she has her own recovery and artefact business. She just runs our front office and does transit. But she is family."
Pickle looked up at the tower where Gunther and Malcolm both stood watch, wondering what was going through their minds. This little girl, as Gunther put it, showed up not to their office but the platform. Money in hand requesting assignment to one of the most dangerous places in the world. What an idiot she was, but she was here. She looked down at the empty tupperware and then at Ka quietly working on his blanket. Finally, she looked back at Gunther and Malcolm on the tower. The creepy tall mage made her reach up and touch her helmet self-consciously.
Boom. BOOM!
Flashes of light off in the distance east lit up the darkening sky. More booms continued off in the distance and flashes of gunfire as munitions were deployed en masse. Frank smiled, pulling his chair around so he had a view of the Mars tower. The big black needle in the sky. It's sharp pointy relief a knife-edge in the sky lit up by explosions in the distance. Frank laughed, "Our own fireworks show."
They watched the fireworks explode in the dark sunset sky. Watching the sky darken as the battle raged on. It seemed to grow in intensity over time. After a while, Brian joined them to watch the distant battle. Eventually, as it grew quiet and the sun hints of warmth drained from the day they saw the night sky fill with stars. Looking up at the bright night sky.
Living in the city she was used to seeing a dark grey blanket with a coin of white for the moon. Here the sky was a dark blanket with blues and swirls, deep colours she had never seen in the deep black. Crisp starlight painted the sky though no moon was to be seen in the dark sky. It was a stunning sight she felt like she could reach out and scoop a handful of stars. They were bright and solid without the gravity wakes and haze of the city.
Maybe she hadn't made the worst mistake.
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 4
Pickle on the Nightmare Wall - Part 4
Echoes of Sin
Watching Malcolm's long dark frame sagging, all the threatening strength rushing out. A mountain of power collapsing in on itself. Falling to his knees, vibrant colours flowing away from him and washing over Pickle. The last echos of powerful magical work.
Lost in amazement, as she let the coating of magic flow over her skin, Pickle felt at peace. A wake of rainbow glycerine flecks sparkled off her fingertips, leaving multicoloured eddies as she played with the breeze, scattering across the landscape. Fascinated at the iridescent course of glittering magic, the first thing her brain thought of was flight.
Gravity wakes were tears across the sky, a churning motorboat kicking up three-dimensional eddies in the sky. Her extremities were little fishes in the clear pond, not breaking the water like the powerful engine but flowing through the rainbow currents, touching the spell.
The sky was iridescent blue in its purity, the air smelled clean. She wrapped her fingers around the multicoloured dust closing her hand to feel it shift into nothingness. She felt freezing, noticing the thin blanket of warmth her body kept up against the wind had been stipped back, leaving her naked to the fresh dry winter air blowing over her skin and through her new clothes.
She heard the chunk chunk chunk of the train interrupt thoughts, and then she a loud clunking noise. The moment popped like a soap bubble blasting her mind.
"Incoming, eleven o'clock. Doc get Malcolm, and the girl is gone. Ka Front."
Her mind reeled back from the edge. It was a sudden and sharp feeling of loss. She felt a strange sensation in her skin as it tingled. Trying to shut down the self-examination to look around. She found herself naturally crouching, ready to run. Was there anywhere to run to? It was then she noticed Doc rush past her.
Doc passed her. She noticed that Ka had also gotten off his spin bike. The orc was grabbing his crossbox from the cargo pile. Ka turned the weapon over, slotting in bolts to the feed tray and checking the mechanism. Scraps frantically worked on the Spin drive, pulling leavers and adjusting controls. Northcott was writing down something with almost clerical disinterest in the unfolding situation, flipping a page in his small notebook. Whirling fully around back to the front, she eyed Doc helping Malcolm.
The mage seemed somehow diminished, less scary, as Doc put his arm around her shoulders. It slid under that fire red hair as she held his weight, strength in her pose, gentle concern and professional evaluation on her face. She was talking to the tired mage while checking over him, leading him to the back of the train.
"Move, please."
The doctor's sudden request, delivered in no-nonsense professional tones, unstuck Pickle's feet as she felt herself clearing the path. Hearing Scraps yell a question forward.
"Boss, Spin?"
"Stay free," Gunther shouted back, not looking up from his work.
Gunther stood at the front of the train with the most oversized rifle she had ever seen. He was securing the weapon to the front railing with a small mounting clamp. Working quickly, shifting the weight with his iron claw on the left, and his dexterous right hand making the fine adjustments. She thought the gun might be a chem rifle, but not with that huge cannon of a barrel. The whole gun was comically large, inflated with tons of fans and bits she had never seen before.
Moments later, Ka'Shek joined Gunther upfront with his crossbox in hand. The tall orc stood with his feet wide, making no move to secure his large weapon. Ka stood slightly back and to the left of Gunther, offering support to the captain but not encroaching on his setup, which despite its complexity, was lightning fast.
Pickle was familiar with guns, mainly from the club, but this setup was totally alien to her experience. This wasn't the kind of weapon the Billy Boys or Jack Jack run, nor was it the sort you saw mercs or corps swagger into the club with. The door girls would relieve them quickly with Bruno's help. As the chalkboard sign proudly declared, "Your coat, your keys, and any weapons please."
Plasma powered weapons were sleek and deadly, the preferred choice for most. The mighty little plasma batteries and instability of magic had shifted most away from the more traditional chem guns. You saw chem guns, statement pieces almost always personal weapons, never issued to standard forces, corps or that ilk they were used by mercs and in exceptional cases.
Chem weapons always made people nervous their crude designs were likely to explode without notice at the first flare of magic. Though she had never seen it happen. The things were blasted loud, ringing out loud enough to deafen you. When fired, they made a statement. Besides, the ammo was pretty dumb.
Plasma weapons came in countless varieties, the core power drawing from the powerful little batteries but deployed in an endless range, from short-range concussive thumpers, which mall cops and social security used when they weren't using sticks or stunners. Most carried mag guns which could propel a variety of smart or dumb ammo. Needle guns like hers and the other variants were used by the more discrete, less military sorts. Though she had seen some other strange high tech weapons when the corps were in town to party.
The tribals tended to favour a variety of more medieval weapons, though to call them that was insulting. Refined by modern engineering and, in some cases, magic. Tribal weapons tended to share one trait they were powered by the person. Hand-cranked or fueled by personal magics. The most common and popular type was the crossbox. It was to the crossbow what the modern multi rocket artillery was to the catapult.
Designs vary, but Ka seemed to be wielding a more traditional model. It had five barrels in a long wooden block carved and polished. There was a feeder tray holding a few bolts ready to be gravity fed into place. Ka had a traditional wheel winder to tension and reload the weapon. The wooden bar was the length of the block with two polished and well-worn handles on each side. She watched as he gave it a few turns to tension the weapon.
She had seen a variety of designs and materials all working around the same principle. Really the inventiveness of weaponry sometimes felt without limit. Outcasts sometimes modding weapons to tension plasma fueled motor or compressed gas. Mages working magic into the weapons or replacing pieces with inscriptions. Not even including the whips, psi-blades, personal defence and cyber that came down to fight on the wall. They fascinated her.
Watching Gunther now sighting down the rifle barrel, she noticed the monster weapon did not have a smart scope or holo but rather an old fashioned glass tube scope. Like a pirate's telescope mounted on top with brass fittings holding glass atop the bloated receiver. Looking at the massive barrel and what she assumed was the magazine, the bullets must be gigantic. Though she couldn't see a breach anywhere, every chem gun she had seen outside of revolvers had those waste ejectors.
The gruff captain looked through the pirate scope atop his rifle, drawing a bead on something moving up ahead and to the left.
Dust trail headed by a miniature black spec off in the distance. It was hard to pick out from the background terrain. It was running out from the tall veld grass, tearing up its path.
The first thing she noticed was how it was jerking forward in its motion. Never slowing down, but it seemed to be leaping forward like someone running in low gravity. The second thing she noticed about the creature is it wasn't running towards them.
It was easy to miss at first, but the creature was running to a point a few minutes ahead of them on the track. It was chasing where they would be, not where they were. That superior calculation of a hunter sent a shudder down her already chilled spine. They were being hunted.
She thought Gunther would take the shot any moment, but the seconds drew long as his rifle continued to track the creature waiting for some silent signal. The black spec formed into a pony-sized black cat. The light played on its form strangely. Her mind tried to process what she was seeing.
Six legs. The creature wasn't leaping forward but galloping like a horse with all the limbs leaving the ground as it did progressive speeding leaps ahead. The strange lurch was due to the six legs prolonging the launch time, extending the air time and then repeating. Even that didn't seem to account for its strange gait like it was wearing a grav belt. The creature galloped faster than any vehicle would drive inside city limits.
The was no set definition of Wild vs animal. It was as an old English judge once said regards porn, "We shall know it when we see it." This monster was Wild. She now saw it had soft black feathers, not sleek fur. The eyes were dark red, illuminated by some infernal internal energy. Staring into the eyes, leaping closer to her with each step, she felt something.
BANG
It wasn't the ear-shattering gunshot she expected, but the rifle rang out loud. Quickly followed by the creature faltering in its stride, a flash of feathers flew up into the air. She heard the pull and slide of metal clanking as Gunther loaded another round into the chamber. The sound of a single metal token dropping into an old arcade machine tinkling next to her.
Another loud shot, expected this time, belting out moments later. This time the beast's head yanked back. It collapsed under its own momentum rolling then sliding to a dusty demise not far off the train tracks ahead. She heard the gun reload again. They were closing in on the point of convergence.
The corpse lay still, examined through scope by Gunther and tracked by Ka's bow. Before she could register the details of its twisted form or the dust had fully settled from its ungainly end, the train was already passing it. Moving from threat to vanquished in moments.
Gunther was checking his weapon. The most insignificant amount of smoke seemed to expel from the end of the barrel. A mere wisp. Ka lowered his weapon then pulled the bar in the counter direction releasing the tension from the crossbox. Simultaneously everyone relaxed, breathing out.
The train was more silent than she recalled, realising that since just before the magic, the engine had stopped making any noise and the only sound was wind and the gentle chunk chunk of the rail beneath her feet.
Gunther's turned to Scraps while he worked on his weapon. "We rang the dinner bell. See if the line is connected and tell them we are coming in a bit warm."
"Yes, boss," was Scraps' immediate answer, as she started fiddling with a more complex box of wires beneath a floor panel. Gunther continued on.
"Ka, I want you to keep watch. Hopefully, nothing, but we should be coasting in soon."
Pickle couldn't help but ask, "What do you mean, the Dinner Bell? Sir."
Gunther looked up from his weapon, almost surprised to see her. Ka quickly interjected, looking out at the golden scenery turning green. The noonday sun left almost no shadow as his deep voice cut clearly through the wind.
"We are a tower of little notice. Passing beneath the giants, we guard our wall without song. We hope to stay in balance, escaping magic or technology, drawing no undue audience to dance the deadly footsteps beneath our watch. Death, however, rings louder than any song of magic or symphony electronica."
The tall orc hand resting on his crossbow, staring out at the rushing scenery scanning for danger, was lost in words.
"Magic will draw attention as Malcolm has just shown you. Anything hotter or colder than expected will draw some attention. Magnetics, plasma, radiation, live wires or worst of all grav gel will draw them. I've heard they chomp Phantoms those brain boxes like candy, delicious little cyborgs. Though nothing draws the Wild more than death. You must have heard we eat no meat on the wall?"
Remembering her last warm meal of mushrooms, cheese and root veg. A fond recollection of flavour sitting cold in her stomach, the last slice of the ordinary she recalled. She had heard it was bad luck to eat meat. Ka did not wait on her response, continuing his monologue.
"Well, the killing of livestock or the decay of life draws attention. I hear some organisations use synth meat or just shield their canteens, but most old towers have no murder on them. No one dies on the wall, not truly. Burial and cremation have both drawn too much attention in the past. No death or killing. Bar that in defence of the wall. Even then, wounding or driving away is preferable. Though the captain had to put down that Six Stalk fast, it being south of the wall. He could have put it out of commission without death if he had the option."
Gunther cut in, "Dunno, tough to kill. Thought first shot would do." He shrugged unconcernedly at the encounter. It was then that Scraps approached with an ancient-looking telephone on a wire leading into the floor near the engine.
"Lines scratchy boss, but I got Leon on the other end." Scraps handed over the phone before rushing off to return to work on the engine. As Gunther had a gruff, short conversation over the phone, the Doc joined them upfront. Gunther paused for a moment, making eye contact with her, and she gave a slight nod and smile. Gunther continued on the phone.
"What is that about?" Pickle asked, turning to Doc. Doc seemed to cast off her professional concern and adopt her relaxed tone from early.
"Oh nothing, Pumpkin. The old captain just wanted to know our resident mage was fine and dandy, which he is."
"I thought comms were a problem on the wall?"
"Oh no, papa hooked this up on the line. Well, the last bit of track, at least. Sets off an automated alarm letting the tower know something is coming on the track and provides a line to piggyback on. Scraps will be dumping some power into the line from the braking system as we come in."
Pickle nodded, not entirely following Gunther's conversation but desperate for information. She asked, "We arriving soon then?" making to peer forward, looking for the end of the tracks.
"Oh yes. Pumpkin, come on up top. Let me show you before we pull in."
Doc grabbed Pickle's hand in both of hers and pulled her back towards the large pile of cargo stacked in the middle of the train. Securely fastened. The Doc led her upwards, showing the obvious handholds though Pickle did not need the help. She had climbed and fallen off this particular pile once already. Thank you very much. This was old hat.
They both reach the top of the pile to sit down. Wind blasting in their faces. Harsh noon sun with barely any shadow in any direction left the terrain sharply lit. Behind them, from where they came, the terrain was dust and golden grass with spindly trees dotting the landscape in tiny clusters. Small Kopje dotting the horizon but no sign of the civilisation they left behind bar the train tracks. The discarded wild body, a black speck now fading into the horizon.
The terrain ahead of them was lush with patches of green trees, and the grass was washed with more green than gold. The ground was much less visible between low bushes and growth. Trees more plentiful but younger in their growth. Less old baobabs and more mopane and marula trees. Their big bushy green spheres and umbrella of green.
It was comforting to see all the life. Off to the left, past the tree line, she could see a white tower stretching into the sky. It was maybe as tall as a seven-storey building, hard to tell with the trees. She thought it was less than thirty meters into the sky but definitely more than twenty. What was strange was its shape. It glistened white with a rounded top. The sun reflecting off glass windows and solar panels.
It looked like a giant's tictac dropped onto the horizon like some comical joke. A train line was similar to the one they were on now cut through the landscape not far to the west. Leading to the tower. She guessed it branched off the line they were previously on.
"Medpoll research and development tower. We don't talk to them much outside the captain's call once a week. They are arseholes, but they shield pretty well. See that white paint apparently, it is a new shielding tech of some sort. Still, they get more beasties than us."
Pickle looked at the Doc, her red hair blowing in the wind, the braids flapping. She noticed the black ribbons holding them, her gaze distracted and fixating on them. The Doc didn't seem to notice, instead turning to look to her right as if Pickle was looking past her.
It was then she noticed the sleek black needle tower. Not an actual needle but rather a black triangle with its tallest edge facing out to the wild. The building bristled with equipment and gun emplacements. At about the halfway point, there was a small landing pad of sorts. The needlepoint must have been ninety or so meters from the ground. It was almost lost in the sun glinting high above, though she expected it cast a long shadow south most times of the day. The low winter sun high but slightly to the north put the southern side in shadowed relief.
Doc wrapped her arms around herself, holding her shoulders as if she had just noticed the cold from the wind. "Mars Weapons System Tower. You know them big weapons manufacturer. Used to be old Keeplan's tower before the swarm twelve years back. The company sold their plot after then. Old man Keeplan lost the will aftermost his company was slaughtered. We tried to help. They were low emission like us. Used to be dozens on the wall. Mars makes a lot of noise. They like killing beasties to test new weapons out."
"I can't see our tower," Pickle was peering as hard as she could to the gap ahead. All green trees and some of the stone hill Kopje.
"Well, that is the point, silly Pumpkin. Low profile and low emissions." Doc pointed her finger ahead, tracing one particular outcrop. "See that one there."
Looking ahead through the crisp, clear air with the wind directly blowing into her eyes, drying them out, she could just about make out the shape.
"That is our home. You will see the metal once we are close, but dad likes the rock on the south end to hide some bits. Need to keep the tower clean, so nothing can climb up easy."
Home. Without knowing it, Pickle found herself rolling the word over her tongue. She hadn't really thought of the club as home. Queenie had given her a small room docking rent from her wage. Nothing much more than a bedsit. Small single bed with a tiny desk and a few drawers under the bed. There was a slimline closet in which she could hang a few dresses but not much else. Maybe a square meter of floor to stand-in. Lock on the door, but of course, Queenie had the override code. Better than a cap bunk.
Those small honeycombed capsule hotels were filled with little coffins. Many mercs or travelling freelancers hired those out for the few nights they were in town. Though those with a bit of cash splurged on a hotel room. The brave or foolish stayed in the hostels, though unless you were a squad or hooked up with the local gang, that was silly and a surefire way to end up poorer in the morning. If you woke up.
She knew of some tribal plots, corporate campuses, or embassy grounds which all had on-site housing. A few wealthier folks, merchants or free agents had genuine homes, but the urban sprawl was much tighter these days. People didn't like suburbs spilling out into the countryside.
If you live outside the city, you were in a walled community with private security or on a farm complex much the same. She thought back to the mining barracks, her earliest bunk. The little sleep she got was in whichever cot was empty. Any privacy she had was contained in a small locker with a combination lock on. The lock was a joke which could be kicked open. No one kept anything of value in there. A place for some bedding and a spare rag or two. You kept anything of value on you always.
No, she had never had anywhere she would call home. She had a few favoured street spots she knew you could get a good kip in. Where the cold or rain wouldn't get, others where the heat or wind wouldn't. Never both. Each hideaway comes with its own perils. Even the soup kitchen old Ghilli ran was more a stopover. The nuns had been lovely, but beds had been few, and once she was better, it was best to move on. Home.
"Well, I have never known any place else. Mum had me on the wall in this tower. Pa says not a single creature attacked that week. Like I was blessed."
Pickle was pulled out of her memories by Sarah's words. She was still huddled up against the cold wind. Though now, instead of her arms wrapped around herself, they were tight against her chest as she felt a small golden locket around her neck. The shallow oval gleamed. It was the sort that held a photo. Pickle didn't need telling. She put her arm over Sarah's shoulder.
"Don't think I've ever called a place home," admitted Pickle. The was silence for a while, then a tiny sniffle from Sarah. Feeling the awkward silence pull the words out of her, she continued. "Well, I moved around a lot from place to place. Had a warm bed the last few years, but that wasn't always true. Been lucky the last few years." Pickle noticed Sarah rubbing the locket.
The silence stretched on. She wasn't sure if Sarah was listening or lost in dark memories. She could feel the sadness and didn't want to leave her drowning. "Home." She rounded her lips around the sound. She didn't want to think about her childhood either.
Not that there was much to say. Her mother was a distant memory lost to dust or whatever the old-timey high was of the time. She didn't blame her. She was human, or at least some of the guards seemed to remember her as such. That made her think about the day her ears started to point. She squeezed Sarah tight. These were dark thoughts indeed.
They lingered there for a while with the wind and cold.
While watching the greenery envelop them and the veld vanish, they spotted a large white bird in the sky. Sarah pointed up at it, adding, "That glider is back. We should go tell the boys in case they have not spotted it yet."
Rubbing her eyes, Sarah tucked the locket away and stood up. Bending down before leaving and placing a small kiss atop Pickle's head. "Thanks, Pumpkin. We will be home soon."
Smiling awkwardly, Pickle waved Doc off and watched the glider as Doc clambered down the pile. As Doc descended down the cargo pile, the glider descended in the sky. Doc in a mostly straight line going from handhold to handhold the glider in a spiralling down towards the white tictac tower. Closer now, she could see the red cross in a circle. Emblem of Medpoll bright red on the white wings of the glider.
The glider was unlike any shuttle or transport she had seen before. Her closest point of reference was a street merchant in Harare who sold toy planes for kids to throw. Made of balsa wood, they included a propeller with elastic you could wind up. Throwing them, you would see the little prop spin and pull them forward into flight. She had fixed a broken one once, discarded on the side of the road. It had only needed some tape. Amazing what tape could fix. She had played with that discarded plane for hours.
It had nothing on the mech drones with their noisy engines and small power cells. Flying at high speeds, flipping and turning on a dime. A toy plane like this glider needed a long time to wheel around. Formal lady in white gently dancing across the sky. No bending of wing or whirr of the engine, just a gentle twirl of motion and momentum.
She thought back to all the larger grav craft. Anything she could think of which was big enough to carry a human was equipped with grav gel. The distortion wake left everywhere by the gel was the sign of civilisation. The saying went city folk looked straight ahead round the next corner. She had always heard that remark from tribals talking about how tricky city folk were. Or from corp serfs talking about how city people tended to think in circles. Though most who lived it knew with pride that danger and opportunity were always hiding in the side alley.
Though in a thick enough wake, you could see the light bend around a corner. She had heard some of the kingdoms had strict limits on grav in city limits, but, well, most places the distortion wakes were like the smell of progress. Though if the trail was thick enough, you could sometimes smell or taste it. To her, it was always a sharp tin smell of burnt metal. Tangy on the tongue with a slick after taste which made her want to drink something warm.
Breathing in the fresh clean air, she could smell new growth and dry dirt on the wind. The low humidity and cool air dried out her skin and made her hair feel like thatch. She noticed the glider was dropping something a recess on the bottom of its hull. The small white box fell and was caught in a net almost invisible attached to the side of the tower. The glider continued to spiral downwards. Pulling tighter and tighter.
She could see the entire craft clearly now. The small pilot was using sharp turns to descend at speed. She had no idea how the glider would land on the round top. Watching with fascination, expecting a smoking wreck any minute. Suddenly the glider pulled out of its spiral. Widening its approach, it just clipped the top of the tower. Flying maybe a meter above, it snagged a small case onto a hook suspended beneath it. The small package flapped in the wind like the Doc's braid.
The glider then pulled up all the energy going into a climb. Moments later, the sound of the motor spinning up reached her, the craft pulling itself forward like the toy used to. Deeper in pitch than the toy. Infinitely louder than the silent grav gel but softer than the chem rockets she had seen. It was a new sound, so the propellers must have just turned on to aid the climb.
With the airshow over and cold in the rushing wind, she decided to climb down the leeward side of the cargo pile. Escaping the wind briefly. At the bottom, she found Malcolm snoozing in his preferred spot among the cargo and the little clerical man making some notes in a notebook with a pencil.
"It seems strange, doesn't it, Ms Pickle." He tapped the pencil on the page then secured it, closing the notebook to look at her.
"What?" Once again, feeling the little geek's academic look, she felt like she needed to make a better showing of her education. Such as what it is. "Strange how Northkit."
"Northcott madam if you please. Virgil, if you find that too formal." He paused, allowing his correction to stand clear before continuing onto his preferred subject.
"Why the glider, of course. Though plane would be more accurate as it seemed to leave under power. Why go to all the trouble and expense of building an ancient plane to avoid grav gel only to equip it with an engine. Do you suppose they used plasma cells or chemical fuel?"
"Chemical fuel?" Pickle asked, confused how guns applied here.
"Oh, a few drill heads are still run occasionally though they are risky operations. You can still get old-style fossil fuels though most oil goes to other manufacturing. Solar, thermal or even drawn down from gravity harvests are cheaper. Though I'm told, chemical fuel draws less attention. I must ask Gunther. I wonder if the northern tribes have any fuel sources they use."
Pickled had heard about the head hunters, cannibals and other inhuman tribes which lived among the monsters. "I thought they were all devolved?"
"Oh no, propaganda mostly. They are different. Though of course, we know many countries and almost a billion souls were lost on this continent during the wilding all those years back. Of course, some would find a way to continue. Other's it said are so far from human well..."
"I never got that. Why didn't we hold onto more?"
"We tried, oh we tried very hard, but in the end, this beachhead of Azania and some isolated areas up north were all we could hold. It happened too fast, and we had too much going on at home to care. People never really cared for Africa, even before magic. It was just a convenient place to hide our crimes, Europeans that is and of course Asia in older and more recent times. The cradle of our birth, how we must hate our mother."
What a strange little man, she thought. She was reminded again of how pleasant his voice was when not being rude. It was calm, with every word carefully picked out, not a wasted breath in a sentence. There is no doubt about the exact tone and meaning behind each word like there would be a test later. Not flowery like Ka'Shek or slithering like Malcolm. Just polished. He continued on, switching the topic on her again.
"Have you spent much time in the outdoors?"
"Travelling place to place, not much."
The little clerk adjusting his round glasses on the bridge of his nose looked directly at her.
"Well, you will be spending a great deal of it soon. I confess that's my first time on the wall or in the true Wilderness. The Free Republic doesn't count, I'm told since the council reclaimed it."
"Are you with the government?"
"Oh heavens no," he smiled, amused at the question. "I worked for a small consultancy company, Thunder Limited. My employer hired Mr Gunther for a limited service. So I might spend some time in his tower observing his rather unique stratagem."
"What kind of research would someone want to do on the wall?" she asked, genuinely curious.
"Plenty. Many of the towers are mostly funded by research. Such as the Medpoll tower we were just observing. This is the edge of beyond. The frontier with as much to be discovered here as any frontier. In truth, my enquiries are much milder focused on this company and its methods. Low emission towers are exceedingly rare, and this is one of the longest still standing."
"This tower is special?"
"Partly, all towers practice waste reduction except those who thrive on kill count or weapons testing. Such as our dark neighbours to the east."
The little man cleaned his glasses with a cloth and then pointed at the tall black needle tower. He placed them back and continued on. "To a greater or lesser extent. Though almost all use plasma as their primary power source with other methods as fallback or complement. None other depend on Gunther's methods. Not anymore. Yup, Gunther's section hasn't breached in decades."
This news came as a shock to Pickles, "The wall has been breached?"
"Oh, of course, think back to our little roadside attraction we had. It is not actually a wall in most places, but a range of sentry towers, some large, other's small. A virtual wall of firepower holding back the Wilderness. There have been slip-ups and even large scale ones. News doesn't cover it much."
"Surely people would want to know?" She asked, incredulous at the deception. Bloody corps hide everything.
The little man shrugged. "Those interested enough to ask, know."
She was confused by the different approaches to the towers, expecting a more uniform design. Though in truth, her watching of the companies and train station had only ever shown an eclectic mix of society, she supposed she was naive to think it wouldn't be like that at the wall as well.
"It is ultimately a business like any other Ms Pickle. Hence your shares, or stake as I believe you people call it. You bought registered voting shares which entitle you to seasonal payout of profits as per the company charter, did you not?"
She glanced down at her wrist, the small metal plate still fresh and new to her. Strange but sunk into her flesh. All signs of the binding cord now gone, dissolved into her flesh. You would need to cut her up to remove it now.
"Well anyway, the tower earns a fixed commission for defending a section of the wall. A fixed agreed fee is adjusted on an annual basis by the Azania government. This stipend is the primary source of income for Gunther's Guns. There are, of course, payments for kill count and some bounties. Surge fees and the like. Though in truth, most towers make their money through research, testing or some other mix of money making methods. Such as staging areas for incursions."
This was all news to her, though not entirely new information. She still had the image from the holos burnt in her mind. Brave soldiers fighting on the wall defending humanity from the roiling hordes of the Wild. Waiting for any moment when society could be wiped off the continent by a break in the wall. Storylines and films were always about some brave hero saving or evil villain endangering the sanctity of the defence.
The hole is always being plugged at the last moment. No creature ever breaks through the brave heroes and flawed anti-heroes bravely defending with whatever blend of romance, comedy or mystery your particular sub-genre mixed into the tale. This cynical bean counter and imperfect view of the ultimate human defensive line was just... well, real. She supposed.
She cursed herself for being a naive kid. Thinking back to the dead monster along the side of the train tracks. This was reality. Not the show on the boards with makeup and lighting hiding all the imperfections while the music and dazzle drew out for every dream. This was backstage with the grit, cussing and piss soaked leggings as dancers worked blisters and tried to get the stench off with wipes as the shower cubicle was broken again. Drain clogged with hair and glitter.
She had once heard all of life was a stage, but in her experience, a small portion of it was in the spotlight. Most of her experience was in the messy backstage with crying, underpaid performers and sweaty customers paying for the filthy disappointing reality of their dreams. Backstage where the world was dark, nothing made sense, and you heard the distant clapping and saw the lights flooding into the wings. Hinting at another better world if only you could reach it.
It was at that moment, lost in the dark thoughts, that the sun vanished. The canopy of trees quickly enveloped the sky. It was at that moment she realised that for the last while she had been feeling a gentle feeling drawing her to the front of the train now become a sharp breaking motion. No instant jerk but more instant as the speed was bled off the train.
It dipped and sunk beneath the ground as they pulled into a covered trainyard. The wind gone, the train finally came to a halt. The tunnel was wider than she expected but still relatively narrow. Illuminated by small red lights, the darkness was held back by a wash of red now colouring everything in sight. A looming set of metal doors stood in their way, blocking any hope of travelling forward.
Pickle stepped away from the little clerk and towards the front on the other side of the cargo pile. Sarah and Ka starting to unclip cargo holding lines. Working at a fast but unhurried pace, efficient. Gunther was still holding his rifle, looking about the place with an air of inspection. Scraps running around at speed tending to her engine, working through some complex docking process.
It was at this point she noticed the doors swinging closed behind them. They moved without sound, smoothly closing inwards. She noticed there was a tiny gap between the doors where they met the track. Big enough, a small child could crawl through on their belly.
The doors gave a loud clunk of closing with some locking mechanism engaging. It was perhaps not as loud as she thought, but the enclosed space enlarged the sound. Hearing the sound continue in front, like a stereo dial yanking from ear to ear. She saw the doors ahead open up towards them. She noticed with approval that this set of doors seemed to have a gap blocker where the previous one did not. A small seam was present, but no child would crawl through these metal doors with strong rivets.
Once the doors were halfway open, the train again had a small puff of speed, drawing it into berth. The end of the line was just big enough for the train. Not more than a meter of space was left as the train gently tapped against the cushioned rubber end stops. The doors now closing behind them.
The arched ceiling of brick enclosed two platforms on either side. Awash in red light, her eyes were immediately drawn to a weathered figure sitting on a wooden box smoking a pipe and an old man in overalls working a control console next to him. The smoker pulled on his pipe and blew out a small cloud of smoke in a large ring which he then shot a dart of smoke through as an idle afterthought. In thickly accented tones, the man greeted them all.
"Welkom home, shamwari."
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 3
Pickle on the Nightmare Wall - Part 3
Journey to the Edge
"Easy there. You have quite the nasty knock there, Pumpkin."
Stirring from her dazed state and looking through powder mist as her brain cleared of powered frost and fog. She said the first thing which came to her mind, "For saying name's Pickle, not Pumpkin."
"Well, whatever it is, you still took quite a fine tumble onto our resident grump. I want you to be careful there. Sit up slowly okay? You seem mostly fine. But well, always got to be careful with a head injury."
Slowly the icy mist cleared from her brain as the sensation of cold wood underneath her sunk in. A chilling autumnal breeze on her face as she sat up washed away the last vestiges of the fog clearing from her mind. She looked around through eyes still blurred and swimming. A flash of red moved across her vision. The girl, no, the lady who had been running with Scraps along the platform. Moments before she fell then jumped and fell on top of Malcolm.
Pickle groaned internally, "What a fucking arsehole. Sorry, not you. Who you?" The question came out in stutters. Instead of responding, the lady leant forward, putting the back of her hand on Pickle's forehead, holding it there and then moving it to her cheek without ceremony. Pausing the motion both times till the strange lady was satisfied in her inspection.
"You can call me Doc."
"Oh hi Doc, I'm Pickle."
"We covered that."
Pickle found her embarrassment refreshed, wondering if her concussion had driven her into fatal foolhood. Blushing, she never blushed. Looking down at the floor she found herself running her hand into the back of her neck, ruffling her hair and looking down at her lap. Feeling for a bump and searching for the words, her hand ruffled the top of her hair... her dusty dirty brown hair. Dusty hair?
WHERE WAS HER HELMET!
Quickly covering her ear with her hand feeling its pointed tip, she firmly held her hand in place. Where was her helmet? Her vision was still foggy. Glancing around for it, she decided to try to play it cool. "We arse helmet?" Damn it.
"Oh, just here," small hands holding it out towards her, "I had to remove it to check your scalp. No bleeding but you can never be too safe."
"Thanks," she quickly grabbed the helmet and secured it on her head and pulled the chin strap tight. With it back on, she felt her senses returning to her.
"Truth be told, it probably saved you from a serious injury."
"Yeah, that's why I was wearing it." She lied through gritted teeth.
"My name is Sarah, by the way. I am the doctor of this company. But yeah, most people call me Doc."
"Thanks, Sarah. Much appreciated. Is Malcolm okay?"
"That old cat. You could not drop a building on him if you tried, and a few have tried. Even then, I am not sure you would kill the little shit."
"Yeah, I got that impression," Pickle froze the words out of her mouth before she realised. "I should still apologise to him."
"No, hun. Never apologise to that old fool. He was napping, but he still managed to get out of the way quickly enough. Truth, he could have caught you."
Pickle's vision slowly coming into focus, she saw the countryside over Sarah's shoulder whooshing past in a blur of motion. The gentle click-clack of the tracks as the train made a gentle swaying motion as it flowed along metal stock towards the true Wilderness. She used the awkward pause in the conversation to look around and take in her surroundings.
Scraps and Ka were near the front of the train, tending to the Spin Drive. The engine now purring at full speed. Scraps were secured by waistline to the drive, checking dials, twisting knobs and tapping readings. While Ka was on one of those strange bicycles sunk into the floor having a gentle cycle, the strange sight made it look like he was moving the entire world with his slow pedalling. Disjointed from the speed of the train pulling itself along at high speed. Truly an absurd sight of she picture the strange orc going for a cycle through the countryside.
Shaking the vision out of her head, she noticed that Gunther and the small clerk, North something was his name what a rude little man, were both leaning on the railing talking to each other. She still couldn't quite get the little man's rude introduction to her and to be talking to a legend like Gunther with no regard. Speaking of rude...
Pulling her vision back, she looked behind her, then to Sarah, who just had a single finger pointing up. She tilted her head back for a moment, feeling it swim to see Malcolm perched. The strange man was sitting in a strange, near birdlike pose, knees akimbo, looking down at her, his long heavy coat being gently pushed by the wind. The heavy armoured plates sewn into the fabric fighting the fierce wind. He was looking down at her pointy hat tilted, wrapped fabric flailing in the wind and dark goggles hiding any semblance of human eyes.
He seemed to be judging or inspecting her from on high. It was hard to tell with no skin showing or eyes to judge. He didn't move a single muscle like a grotesque scarecrow or gargoyle waiting for the sun to set. She knew this was his fault. She wasn't certain how but she was certain of it. Unable to continue looking at the grim spectre, uncomfortable with the stillness of form, she looked away to her left.
A greater contrast could not have been struck. While Malcolm could be made carved from an old trunk, cast in iron or hewn from stone, the sight to her side could only be expressed in thick oils flowing with life on canvas.
Sarah was framed and highlighted by thick shoulder-length red hair. The curls bounced and swam in the windy open air of the train. A loose hair tie holding it roughly in form as the wind blew it as a banner for all the world to see in its vibrancy and life. She was kneeling on both knees next to her but currently scowling up at Malcolm with an angry pout on her face which somehow was the funniest thing. She had such a serious and educated manner but behaved like an angry older sister to the man.
The dichotomy was carried to her clothes as she wore faded black cotton pants, splattered with paint. At least she hoped it was paint. It was too colourful to be fluids, and its accidental nature made it look natural. The printed fabrics or pre-distressed fashion she sometimes saw in the club manufactured European bourgeoisie fashionista piece always got it wrong. Artistic randomness and natural randomness are easily spotted.
The true chaos of life looked planned out and patterned like someone handing out karma tokens or enacting a pre-planned tragic comedy by which you would be screwed. Dice didn't roll equally on all sides. Coin flips didn't have to work out even. True chaos was all cows and shit, never predictable, always messy and underfoot.
This extended to her entire outfit, not thrown together out of no care like Scraps maniac fashion sense which seemed to strive for noise but instead a mishmash and jumble. Her red hair and paint splat black pants were offset by a white blouse with neat little frills white buttons, except for one turquoise one which had been replaced, the hand sewing a little less neat. Black suspenders held it in check, firmly secured to the pants. The denim fabric was spotted with buttons and colourful badges of no apparent pattern. A printed silk scarf around her neck of an Asian inspired design was a mess of colours, mostly red and gold.
Sarah's freckled skin was delightfully framed by the shock of red hair. Curls tumbling down past her shoulders. Her eyes, forest green, intently scowling at Malcolm. Attached to her face off centre was a large monocular device. Perched near her left eye, it appeared to be several lenses of different focal, prismatic and coloured arrangements. A truly strange and maniacal contraption more akin to magical equipment than science.
In place of a traditional magnifying arrangement of progressive lenses were a mishmash. Mixed focal length, circles with squares, fresnel with bifocal and clear glass with coloured crystal. She even saw a prismatic bug-eye looking one in the mix, all impossible close and on individual arms. Strangely compact for the large size. A truly absurd sight now she focused on it. Pickle cleared her throat to break the doctor's intense scrutiny of the dark mage.
Sarah seemed taken back, looking back towards her. She noticed that Sarah wore dangling mismatched earings, which swung one a small vile of fluid of some kind. The other was a discarded fuse, burned out, crafted with wire into an earpiece. She also noticed a few small rings of metal running up her ears.
"Sorry, that man just riles me up. You are the patient, though you are looking much more healthy if a bit flush. Too cold?"
Pickle rubbed her hands together to get a bit more warmth in them, playing into the excuse. Though truth, she was freezing her tits. The wind of the open train was crisp in the autumn cold, even with it near high noon. "I like your style Sarah." She saw Sarah smile, what a wonderful smile.
"Now, now then, you don't want my papa running you off first thing Pumpkin." Sarah grinned with a wicked smile, comfortable pursuing the joke.
"Oh no, wouldn't want him chasing me into dangerous Wilds. I might get eaten."
"Now really, that would be bad for the tower. He would probably just shoot you out of his new cannon into the forest. He has been looking for a human tester."
Pickle found herself doing a double-take on the earnest tone and sentence.
"Wait, your dad's in the company?"
"Yeah. Chief engineer, you'll meet him and the Ball twins. Assuming he is not on one of his ranges, then Leon should be there too. They are currently holding down the fort. While we came into town course, a few of the gang are off on rotation, and well, Willy cashed out but yeah, still good to meet everyone soon."
"Delighted, I'm sure." She had no real desire to meet everyone soon. Enough trails and broken hearts had made her cautious through the years. You only had your life savings stolen once before you slept with half an eye open, and that wasn't the only thing they could try come steal. But she also knew that being openly hostile towards people was not a good tactic. People having their friendly advances rebuffed could lead to worse things than theft. So she smiled and looked at the naïve doctor.
"Yeah, sure. That sounds lovely, Doc. You know, we'll all be working together."
"That's the spirit. Well, let's see if we can get all grumpy face to apologise to you at that."
Doc stood up and looked up at Malcolm still perched. She shouted up without holding back, "Come down here and apologise, you old meanie!"
Malcolm tilted his head to the side, furthering his bird impressing. Just sort of looking at her with his dead-eye stare. How can I tell that? He's wearing fucking goggles? Doc continued her tirade.
"Come on, old cat. This instant. You come down here, and you apologise to Pumpkin. If she had fallen just a little bit differently, she could have been dead. Your lazy ass didn't even think to catch her."
Malcolm's head turned to her robotic and then tilted back in the most peculiar expression. Then in the most human display she had seen from him so far, he shrugged, resigned to his fate.
Not wanting the mage's apology or his attention. Pickle tried to think about how to get out of the situation.
"It's okay. Doc, you know I fell on him. It's kind of my fault."
"No, it's Gunther's fault. Silly old fool did not tell you to strap in and think to check you were secure." She seemed riled up and quite upset now before deflating a bit. "But that, to be fair, is somewhat my fault. Sorry I kept Scraps. I was shopping, and I got a little bit distracted. Should have kept an eye on the clock, but when she said you needed clothes well... So I suppose if anyone should be apologising to you Pumpkin. It's me."
"That's that's fine. It was really my fault. I should have been holding on."
"No, no, no allow me to get you back to the tower. And then. We will give you a proper good apology tonight. I can cook even."
That last word seemed to send a bolt of action into Malcolm as he dived down as he dived, down off the pile of boxes. Gracefully rolling and landing on the moving platform before standing up in one smooth movement. Malcolm laid his hands on Doc's shoulders as if he had been there the whole time.
His salutary voice cut through, "Now, Now. We don't need that. I'm sure we can think of some other wonderful apology that you could give to our newest little kitten."
Doc seemed insistent, "No, I went shopping. I got fresh ingredients and everything. Got a new recipe. I want to try."
"Well, if it's that special, then shouldn't you need more than one chance to get it right?"
The Doc seemed thoughtful before putting a thoughtful finger and thumb to her chin. It was then Pickle noticed that Doc's nails were done in a strange, metallic paint with an opalescent finish. The Doc seemed to think for a moment before rolling her eyes and giving in with a sigh.
"Well, tell you what, Pumpkin. I'll make one small dish for you and you only. But first, I'll get Malcolm to taste test the first attempt. You can get my second perfected dish. I don't want my apology to be anything other than perfect."
Malcolm's shoulders sagged, utterly defeated by this news. Sighing deeply before grumbling, "I wonder if Leon needs assistance again."
Seeking a way to break out of this interaction, Malcolm looked down at Pickle.
"You okay, kid? I'm pretty sure you are. You seem tough sort, but, well, I'm sorry. I didn't catch you."
"See, was that so hard?" The Doc beamed with satisfaction at Malcolm. "Now I have my stuff to pack up."
The two shared a small laugh. Doc laughed with genuine joy. Not a body shaking belly laugh but a warm chuckle that just seemed to animate her entire form and bring a sense of warmth and life to her aura. While Malcolm's laugh seemed more of a snicker like a cartoon villain cackling under his breath. His head bobbing with delight in another evil plan fulfilled. But, they appeared friendly, genuinely friendly with each other. She wouldn't think Malcolm was capable of it.
The tableau was unfamiliar and uncomfortable to her, so Pickle thought about how she could redirect the conversation. She had done as much research as she could before coming on this trip, but double-checking your facts and gaining information on the ground, kept you alive. So she turned to the informative doctor who, outside of Scraps, has been the most talkative so far. And a lot more articulate.
"You mentioned your dad and such. Is this the full complement?"
"Mmm. Yeah. Just about. Gunther is our Captain, you know that you signed up with him, big old war hero that he be and Malcolm here is his right-hand monster." Doc seemed to glance smirking at Malcolm, who shrugged before she continued, "Well, monster friend or fiend. We will go with friend. Malcolm here oversees the magical side of things. We try to keep magic and tech to a minimum. We are what is called a low emissions tower. But you are not interested in that. You were asking after people. Yeah, so Captain Gunther and his right-hand monster Malcolm."
Doc held up two fingers, counting everyone off.
"Then you got my old Papa. He's kind of the mechanic engineering. Pretty much keeps everything running. You can call them Fred."
"Or little Fred if you want to get on his good side," Malcolm interjected.
"Now, now. Do not be giving her terrible advice like that. Papa got a sense of humour, but Malcolm's humour is a bit sharp. Papa keeps the place repaired and upkeep and does any upgrades. Of course, tinker with anything and upgrade anyone. We don't really do cyber even Gunther will not let me do much with his arm, but yeah, if the tower breaks, dad will fix it. And if you break, I will fix you."
Four fingers up, the Doc played with her thumb for a bit, "Course Scraps doesn't actually work the tower. She does train supply runs and staffs the office back in the city."
"You have an office?" This was news to Pickle, who had only watched the train hub. Never seeing Gunther go to an office.
"Oh, sure, Pumpkin. That's actually where most people sign up or do business. Most people don't come up to the platform and just sign up as we're loading up. He is so disorganised I am surprised Gunther let you on. I was told you went to the station to sign up? Never heard of the like. No, I suppose you used to back in the day when things were a bit more hectic. These days we have an office. I don't think Scraps is there every day, but it's a small rental downtown. You know PO box paperwork and the like."
Doc had settled into a lecturing tone while Malcolm, bored, started loosely braiding the doctor's red hair with his gloved hands, displaying more dexterity than she expected. Doc continued on before concluding and deciding to keep the thumb up.
"And, of course, you know, we have to do the regular, business paperwork stuff. Scraps is a liaison and pretty much our lifeline back to the civilised world."
Starting her count on her other hand, thumb out, "Then Ka. Not always with us," her voice went theatrical for a moment. "But mighty Ka'shek Patoresh the warrior-poet join us on his quest." She calmly continued, "Oh, about a season a year. Sometimes two if we're short-handed. Handy orc and a tough cookie but a real sweetheart."
Lifting two more fingers, she brought the count up to eight. "The Ball twins, well again freelance with us most seasons lately, but they come and go. Got a few other regulars none on the wall at the moment."
Lifting the ninth finger and sticking her tongue out a bit, Doc seemed to think for a moment. "Oh, then there is Leon, of course. Ranger fellow lives on the wall. Leon's been at the tower since I was little. Does not come to the city, strange fellow quiet but nice. No playing cards with him for anything other than fun."
The doctor stared down at her nine fingers intently as Malcolm seemed to come to the end of his braiding project, producing two black ribbons tying Doc's braids. Then Doc held out all ten fingers towards her in glee, "And then there is you, Pumpkin. Did you sign up for the season or a company contract? Welcome aboard. It is a small group of us, but we are family."
Pickle couldn't help suppress a small involuntary shudder. Doc didn't seem to notice and converted her ten-finger count into a high ten waiting in the air. Faking enthusiasm, Pickle returned her high ten. Only ten, well, eleven people, including the Doc. She thought there would be dozens.
"I thought there would be more? I thought towers were huge forts on the wall. I mean, I knew this was a smaller tower but..." Pickle was unable to frame her question. It was Malcolm who answered the unasked question in his cold tones.
"Listen, kitten, the wall is a dangerous place we have had more and rarely fewer. People die, people leave. Few sign on. But ultimately, we are, as Sarah said, a low emission tower with not much room."
"Papa or Scraps could explain it best. Ask them." Doc piped in with enthusiasm. Malcolm gave her a pained expression at the interruption before continuing in his patient tones. No humour or mocking in his words now.
"You must know the basics. Pretty much everyone does. Magic and technology can upset things, especially in the Wilderness. So we try to keep both to a minimum."
At that moment, a shadow fell over her eyes. A gruff voice interrupted before she could ask her next question. Looking to her right, she saw Gunther standing there, arms crossed, looking down at her.
"That means I keep it to a minimum. You ok, girl?"
He looked down at her without any sense of concern in his eyes, but his face wasn't unkind. Just business, she liked business. Professionalism, she could deal with that.
"Sir, yes, sir."
"You own stake, but obey orders. I like people to understand the why when there is time. Short answer. Low emissions keep us alive. Long answer well..."
Gunther seemed to pause for a second, his iron claw once again scratching the underside of his short beard. The man of legend was not given to long speeches in the flesh. His behaviour was different from the hero on the holos or talk shows from decades ago. He seemed conflicted and uncomfortable, he continued.
"It's about money. Towers are paid seasonal based on distance and length of wall protected. Bonus kill and research commissions sweeten the pot. Some towers work different to ours. Scout towers, slaughter boxes, RnD bunkers and the like. But I found the safest way to keep everyone alive and paid. Guard the wall, stay quiet, and we don't see much action. Don't poke the bear. Keep everyone south safe. Mostly."
Pickle ran the strategy through her head. It made perfect sense to her the tower operated much the same way she had stayed alive in the mines, on the streets, hell even in the club. What did it matter if you took risks for that big shiny? Chances are you would die getting it, or someone would kill you for it later. No much better to scrap what you could and steal a small bit of sparkle now and then. She liked it, but a voice in the back of her mind nagged at her.
But what about the waves of violent monsters crashing against the wall. Does this keep the monsters away? Is everyone truly safe? Even keeping a low profile, she still had to fight off the occasional street creep.
"What if you have to fight?"
"We'll get a few stragglers and smaller incidents. And for those, we have a range of weapons. We use mostly pneumatics, hydro sprung and some chem. Pretty much anything old Fred can come up with that can kill and doesn't flare too big."
Gunther's eyes seemed to take a mental inventory of the canisters, crates and cargo. Glancing at the Spin Drive, his eyes flicked towards the small clerk still leaning on the railing. With a note of bitterness in his voice, he concluded, "Worst case scenario, we got some plasma in reserve. Nightmare sitrep, we can always call down the light of Heaven. Expensive as hell and wipes out several seasons profit. Course cheaper than a breach penalty, and well lives come first."
She knew from holos and fic that the giant orbital defence assist was a port of last resort, and there were actually a few other options that could be called for. Assuming those slick action fics, Dark Defensive one through twelve hadn't lied to her. Though she was fairly certain no one on the wall had ever ridden a dragon in defence of humanity. So maybe some actual questions would be good.
"What about Drop Squads? Sir," she asked cautiously, belatedly adding the sir onto the end. She had always loved the image of the brave heroes dropping in on grav shot arriving at the last moment to save the day. Gunther grunted.
"Those flyboys? Mostly private. Corp or insurance. When they come, they enter hot and heavy. If they come in. They call doom drop, then they have no obligation to drop. You call, cowards cluck, and then you're holding the bag." Bitter tones entered his voice. Gunther paused for a full second before continuing on. "Then you are calling for Heaven's help regardless. Besides, they cost a lot of money, almost a season's taking for us. Money will do us no good if we are dead, so we have options. But well..."
The gruff man shrugged his shoulders. Not a full shrug loaded with uncertainty of youth but a little confident acknowledgement of the fates and the cruelty of life. Nod to fate. Barely enough to notice. Doc's voice, now a little sad, cut into the conversation.
"The wall is run pretty thin these days, Papa says. Even the big corp towers are battling to hold their own some days. And of course, if we surge." Doc paused briefly, shutting her eyes and shaking away a bad thought. Her braids swinging side to side in the cold wind. "You are not to worry about that Pumpkin? The surge has not happened in our section for ages. Not since we stopped poking the bear." Doc's voice shook at the last word.
Gunther grunted, and Malcolm put his hands on Doc's shoulders again in a light hug. There was a conversation here, and Pickle wasn't part of it. An awkward moment of silence stretched for what felt like ages, though it was probably only moments. Time was funny, real or standard.
"That's the reason I came back here," Gunther interrupted the moment. "Malcolm ritual time, and girl, I need you to take off your pants."
Doc shocked spluttered with outrage, "Now see here, you may have Captain's total writ, but that's just not right. Asking a lady to..."
Malcolm's snickers cut Doc short. Pickle hated that man so much. Malcolm was on the edge of a full evil cackle, and Doc was wordlessly indignant as the stoic Gunther looked on non-plussed. The Captain's clause meant he could do anything, right up to and, including killing her for the safety of the wall. Still, she hadn't expected this.
Doc glared furiously at Malcolm, who now collapsed to the floor in a full laughing fit. Doc was more concerned for her than she seemed to be. Well, worse things happened at sea, resigning herself. She started removing her top when suddenly Gunther's voice came out quickly, embarrassed though more frustrated than flustered.
"Nothing like that girl. God, you are child! No Scraps told me your pants smelled." At this Malcolm was wheezing on the floor. Gunther continued more calmly, "She got you some new ones."
Her fancy pants didn't smell! They were the most modern meta-material synth. Self-cleaning with irradiance and sculpted print. Hell, these were the height of fashion in New Hope City. She had been assured as much while getting the previous owner out of them. Why only thing better was true meta-material or smart fab... she groaned internally and facepalmed.
Meta-material was tech! Or magic, to be honest, she wasn't a hundred percent certain not having bought them herself. Scraps had said they would need to be swapped. For the second time today, she felt her cheeks flushing red with embarrassment. She never blushed and now twice in one day. It wasn't helped that Malcolm noticing her facepalm, was now coughing on the floor between wheezing laughs. She joined in with Doc's angry glares at the mage before they both made eye contact and started laughing a bit themselves.
Shortly after, a small parcel was produced. A set of new clothes all from natural fabrics wrapped in a length of cloth. The package was sealed with a small blob of wax with a shop crest pressed in. They all looked handmade rather than machine cut. That is to say, they were sewn by a machine but lacked the straight edge line of a textile factory and instead had the slight, almost imperceptible wobble of a person guiding a sewing machine. You learned to tell machine lines from human, or at least living hands, she thought, thinking back to old Lady Bloom, the pixie who did costumes for Queenie.
It seemed lacking her input Doc and Scraps had opted for fairly neutral choices, and she was impressed Scraps had eyed her measurements so well in their brief conversation. Wrapping a length of cloth around her like a large towel to give her a moment of privacy to change. She changed into the new pants at the back of the train.
Immediately she felt the cold chill of the wind, and the fabric was scratchy. Nothing like her fancy pants. Now changed into appropriate attire, she came forward, pants in hand, turning to Gunther and asking, "What is the ritual?"
"Well, kitten, " Malcolm's oily voice interjected, "It's not THE ritual, but a particular magical ritual. As you know, the mage school... or may not being from the sticks. I suppose I have taken you on as my apprentice. Well, this is not the time to explain all the complexities, but the School of Magic I follow is ritualistic and formulaic."
She found herself drawn into the explanation as Malcolm's creepiness faded away, and he got a bit more human in his motion explaining his craft.
"Rituals, of course, being the most powerful format. This particular ritual, the crew lovingly calls the scrub and clean, but really it's a balancing ritual. You see, whenever magic is moved about a place, peoples auras mix, or you just pump a ton of heat, radiation or directed energy flow like electric well, it leaves a mark. Fingerprints or gradients like how you can make a metal magnetic using coiled powered wire or something left in the sun grows warm. Fingerprints."
Malcolm pulled out a few small rods of metal. About the thickness of a chopstick but a third the length. Spreading the shiny rods on his palm, fingering each as he continued.
"We all know iron stops, silver streams, gold eternal, copper carries, and tin taints. Well, truth be told, most materials have alchemic reactions, but metals, in particular, pure heavy metals are notorious for holding or blocking fingerprints. Wood can be tough, too, depending. Though alchemical alignment class, this is not."
His fingers danced in the air before tapping her helmet, then pinging his gloves metal tips on the rim of her mining helmet. Making a ringing sound. The long-drawn tone seemed to ring unnaturally long in her ears.
"Metal magical, magnetic or well-exposed will sing to anything with the ears for it. And the ritual is to calm and quiet and things down. We like to do it. Not too close to the wall because the ritual makes magical noise itself and draws attention, but there's no point doing it while we're still in the station. Because well, the full Spin and the emissions from the city. Taking a shower before swimming in sewage. Not to mention the city doesn't like large-scale magic performed inside of it."
Malcolm completing his lecture, sighed and placed the rods back into a small pocket before inspecting the glistening fabric of her folded pants. Rubbing the material between his fingers. "Well, better get this stowed. Cleansing rituals can ruin batteries, tech, weaker magic and the like. Or worse, react. We don't want to make your day even more interesting kitten."
She was beginning to loathe that nickname, but the information was interesting. She'd never really talk to a mage about magic. Magic was magic. The magic users she had all met, present company included, all creeps revealing in their mystery. They were more interested in showing off or discussing their greatness and how they could make the tequila sparkle. It never tasted the same. Once Queenie had lured in a whole bunch of them from some magical conference in town. The club was enchanted all week, booze tasted funny, and bottles exploded randomly for a month. Not to mention all the breakage or pranks. Oh, and of course, how they could make any night magical. Several workers had caught the nasty case of regrets. Queenie had to get in a hedge witch. Fucking creeps.
Gunther interrupted, "Get that stowed. Malcolm, get prepped." With that order, Malcolm walked to the back of the train pulling out a large book from a bag. Gunther went to the front with Doc. Doc climbed onto the bike next to Ka and started peddling, saying something to Scraps, who unclipped her safety line grabbed something and made a beeline for Pickle.
Scraps came over with a little metal case with a combination lock in hand. Spring in her step as she walked with the motion of the train. It was battered but looked newer than most things on the train.
"So soz bout the depart. No time to flog the stuff you gave me, but Gun said it would be good in a case. Grabbed dis one for ya. You can shove your shiny shorts in it. Codes 1234, but you can switch it."
Scraps held out the case and popped it open. The inside was lined with shiny red fabric on which her pad, needle gun and stun ring lay. She placed the folded pants on, topped concealing the contents and closed the case making a mental note to change the code later.
"Keep it private. No one steal from you, but bit of private portant when living in tin can." Scraps smiled, "I take pad battery out and disconnect comms so no soft call home."
"Thanks, Scraps, I appreciate this," and strangely, she found she meant it. She had taken a liking to the crazy multicoloured grease monkey with her honest face and simple manner.
"I go now make the engine free. Malcolm make it all go wobble wobble. If Spin not free well wobble wobble bang crash and no go."
All around her, everyone seemed to be making preparations. Malcolm had a heavy metal bound tomb on his lap tracing words with his finger and writing down things on a spare piece of paper. Though it wasn't a crisp white printer or notebook paper, she was used to but rather brown and thicker with a limp quality.
Gunther was fussing with a screwdriver on his arm. Using an oil rag to make the process go smoother. Ka was reading a small book, well in truth, a regular-sized book, but it looked tiny in his hand while pedaling on the cycle next to Doc. Finally, she noticed the one figure still in all the commotion, the clerk or guest leaning on the railing at the front of the train looking in the direction of travel.
Thinking back, she didn't recall Doc mentioning his place in the company. Was he new like her? She hoped not. She remembered how rude the silly man was. Northcoast or something was his name. Virgin Northland or some such. She walked up to him, the cold June air crisp with the promise of winter rushing all around as she moved to the exposed front. No boxes or cargo cutting the wind. The train was really just an open platform on the rails, exposed to the sky. She leaned on the cold rail next to him, taking in the scenery.
The signs of winter were all around. She saw the tan countryside. Sand and brush with low veld stretched out in all directions. Even now, the trees green were tall and thin, bare-bones skeletons puffed with green clustered to give a sense of flourishing life. She had seen forests in paintings, holos or fic, but they always looked wrong to her. Too verdant and lush like a garden, not like the wild, she knew of hot sun and sand with grass being a patchy thing in places and tall where it grew. When the big cats and lumbering creatures roamed.
She picked out an old baobab tree with its thick trunk and umbrella leaves. The old ugogo of the bush or ambuya, as some locals around here, called the trees. They were ancient. Some she was told were over 2000 years old. Everyone knew they were places of old magic.
Off in the distance, she saw the stack of stones indicating an old Kopje. The mix of natural formation and ancient construction were considered places of power as well. She knew to avoid them, and she thought she saw some great beasts sunning themselves on the stone in the noon sun. These castles of stone, most small stone outcrops some ancient castles were not known by one name collectively in the old tongues, but Kopje was the word used in the city to describe them. Though in the bright noonday sun with the cold air rushing in her face, she saw only the beauty of such places. It was hard to link them to dark stories and dire warnings told in soldiers bars and whore houses. Places to give grown warriors night terrors and make them fear the dark.
Looking down at the twin rails of steel below them laid on top of broken and patchwork tarmac. The old road was barely visibly echoing a time long gone, the rails a statement of purpose lonely in their slimline cut through the relatively tame outdoors, not the true Wilderness yet but echos of it were present. She didn't know anyone who was truly comfortable in the countryside. It's not that people had widespread agoraphobia. Some people did like a quiet life. It's just isolation now came with time slip. The mind played tricks on itself. Then, of course, monsters stalked the wide-open spaces.
She glanced at the little man wanting to ask so many questions. Where did he fit into all of this? She decided to come out and ask. She was about to just ask when the man pressed up to his gold-rimmed spectacles and straightened up. He pulled on his jacket and dealt with any creases before turning to her and saying, "Well, it looks like Mr Malcini is ready to perform. I must attend to my equipment, good day Ms Pickles."
Doffing his hat, he left her there as Malcolm walked forward and took his place. Book no longer in hand, he held the piece of paper and a slim rod of tin tall as he was. He placed himself firmly in front of the train dead centre. Turning to her, he said in a cold voice, "Run along now kitten, you don't want to be too close."
Glancing briefly at the page, which looked to be more algebraic formula. Doodles and short passages of numbers and words with strange symbols scribbled in the spaces to form what looked to be a demonic cheat sheet. She rushed back towards Scraps and Doc, now drinking quickly from warm cups of tea. Scraps wordlessly handed her one. It was warm to the touch, and the gentle heat was comforting.
Malcolm stretched out his arms wide and began trailing his fingers in the air. She recognised some of the patterns from the piece of paper. The motion was fluid but precise down to the exact dancing of his fingers as his voice incanted in a melody of tombstone timbre. Forming a harmonic with itself in the most unnatural way. The air folded and glistened. She could feel the folds in space more than see them directly. There was a prickle as she sensed the magic flowing, the sensation even stronger now than the cold wind blowing over her.
Finally, Malcolm flung his arms wide, stretching the complex web of folded space trailing furious energy. The wires of power took a new shape, a performer revealing it was the three hearts all along. The flush of power travelled on the wind, and she felt a shiver journey through her. She knew then on some subconscious level this was not the end but merely the start as the spell in place Malcolm now poured his personal power into the contraption to power the mechanism he had set.
The wind washed over the train, and wherever air hit resistance, tumbling and twisting around things, there was a halo or glisten of rainbow space. Not the broken frayed edges and knots of a shuttle soaring into orbit. Or even the grav lines left by heavy traffic in the cities or the murky clouds of drop troops falling into the soup. The streets swimming in ankle high distortions from grav trolleys and float cars. They all felt dirty, like seeing sewage in the air. This felt like water flowing crystal clear in a mountain stream. The purity was so crisp the only sight of it was the subtle bending of light as eddies formed in the current.
Prismatic rainbows danced more strongly on the metal. The large spin drive, still humming and purring but not roaring as before, shone brightly with flares of colour on all sides. She saw Doc trailing flame and Scraps leave rainbow smoke. Her own hand appeared to be swimming in currents of jade. To describe any of the trails with a single hue was to describe a painting with a single line. It was a dance in space, every moment different as it danced over her goose-bumped flesh.
It was then she noticed the cold of earlier was seeping into her bones. Like the wind was cutting harshly across her skin, stealing any semblance of heat. She felt her soul push out against it, the warmth of the tea spreading out along her arms. Just when she thought she would freeze to death, the streamers of prismatic colour broke and sparkled into glittered dust scattering on the wind and into the landscape carried away from them.
The glitter did not fly with the wind but was carried by another force and spread out behind them in an even fan flying high and wide, leaving a backscatter of sparkle. She let out the breath she had been holding to see not a hint of warmth in the air. Everything felt balanced.
The silence was suddenly broken by the sudden return of wind and the clunk clunk of the rails beneath them. She felt at peace with the land in perfect harmony with the train and everyone on it. For the first time, she felt like she was in the right place.
Gunther pressed past her with the largest rifle she had even seen announcing in his booming voice.
"Incoming!"
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 2
Pickle on the Nightmare Wall - Part 2
Leave it all Behind
Pickle approached Platform 13 with a smile and a confident step only to find a great deal of motion had ensued in her minutes in the office of the scribe. She paused to see Gunther locked in a shouting match with a small man who was wielding a stack of papers like a furious baton of authority. Meanwhile, a flurry of activity was happening on the platform behind them, the folding metal table now packed away.
Pausing to take in the tableau of sudden change, she halted in her step only to feel the cold black air of Malcolm sauntering past her into the chaos. He nodded at Gunther ruffling his hair with one hand before leaping up to the train catching the hand railing and pulling himself up. Malcolm vanished behind some crates out of her line of sight. With the mysterious dark figure gone from her vision her mind cleared and she was able to once again focus on the farcical scene before her.
A small figure and a large one were handing off crates and boxes to each other onto the train. While a third figure moved around checking boxes. It seemed fast but organised.
Gunther stood tall his tan khaki jacket unbuttoned and hanging loose on his frame still dusty from travel. His combat shorts were adorned with pockets and attachments. His tall socks and well worn laced boots giving the air of authority of one who spent little time among civilisation or hot showers. His left arm ending in a crude metal pincer of his prosthetic waving madly as he argued down towards the smaller man.
The man was of average hat wearing a suit and pants. Not formal black-tie like she sometimes saw in the clubs or fancy tailored attire. This was a plain but well-made cotton jacket of power blue over a white collard shirt buttoned to the top complete with a small dark blue bowtie with white polka dots. The immaculate white pants with their freshly pressed creases had barely a dusting of dirt. The round-faced man with his small wireframe glasses sitting on his nose as two circles of gold-rimmed glass emphasised the clean-shaven moisturised skin and immaculate self-care routine. The dark hair styled and cut in a short practical fashion but with enough length to show the shine of expensive and perfumed products. Matching the dark gloss of freshly cared for pointed shoes. The man had the manicured tones of Queen's English she rarely heard in this part of the world.
"Captain, if you consult our agreement, my employer clearly stated that I would be bringing equipment necessary for my survey of the wall."
Gunther's brow creased as he fired back, "We are a low emission tower, zero if I could manage it. I will not have you killing my men."
"I assure you the equipment is perfectly shielded and of the highest calibre."
"No, you are not bringing anything on that train Scraps or Fred ain't cleared. If Scraps can smell it, so can they."
"I was merely checking the equipment before deployment. I assure you it will not require a satellite link in normal operation. The contract clearly outlines the technical specifications of your engineer..."
It was at that point that Pickle lost interest in the conversation. She knew some about beasties and plasma. None in the south didn't know the night stories told to children.
Night night child take a candle to bed
Blow out all flame before resting your dead
Turn off put out and wrap it all in lead
For most of her short life, she had been under the city lights. Sure she had travelled from place to place. You were safer south of the wall, but all knew a tale of a horror or two getting through the net. Or some homegrown nightmare stalking the alleys and sewers mixed in with the monsters on two legs, calling themselves civilised most of the time.
Looking at the chaos round back, the arguing pair now dissecting clauses and terms, she walked past them. She wondered where Malcolm had gone?
"Hey Pickle, over here!" The eager hail came from a pile of boxes in a voice too energetic and feminine for the tall miscreant. Moments later, a colourful teenage girl stood up from behind a crate lifting up a small toolbox.
The girl's hair was a disaster zone of colour swirled rainbow pixie cut that didn't look like it had been dyed but assaulted by a clown car of paintball gun-wielding hairdressers with eclectic tastes. She wore a loose-fitting white shirt stained with dirt and grease. Tall block lettering picked out in a brutish font.
ROCK SMASH LOVE
The shirt was tucked into black cargo pants with a large carabiner hanging off a cloth belt weighed down with more keys and tools than Pickle could make out. The loud jangle and clash of her movement with the bright colours was a shocking and immediate contrast to the practical crates and canvas all around. The girl gleefully extended her hand past the toolbox now resting on the crate.
"Name's Sam. Though you can call me Scraps, the rest of the crew does. Gunther mentioned you were signing up with old tall, dark and sleepy. Welcome to the Gun Show best tower on the wall."
Momentarily stunned by the barrage of joyous cheer from this young girl she found herself without a response. Falling back on acknowledgement, she nodded. This seemed to be enough for the girl to launch full steam back into her routine. Scraps grabbed her hand and shook it with vigour.
"Hear, let me take that bag of yours. I'm cargo master, or mistress, well cargo queen, let's call it. Nothing goes on the train without me checking it over, and I run supplies over to you all every lunar cycle, bout once a month. Bossman likes to move with moon when we can or close as schedule allows. Oooh, nice pants, they metamaterial? Going to have to leave em here. I'm sad to say too much backwash from the weave. Smells funny to me. We try to go only for natural fabrics, now I'm not say strip here, but you got another pair o pants?"
Pickle confused for a moment, shook her head, she had other pairs but none good for the wall. She had some dresses for the club, but she had left them along with her rags behind. These pants were kinda the bee's knees of fashion with all their self-cleaning and all she thought they would be perfect. Did she have time to go buy pants? Weren't they shipping out soon? "Um, I thought these would be okay?"
"Oh for most towers, sure but the old man just don't like risk. Like I said they smell funny to me. No benefit to bringing em so he will want you out of them. No worries he mentioned you had shinies on I yanked some threads from the locker. You are about my size might be a bit short in the leg but should fit ya. Now I got to see the bag."
Slinging the small khaki pack onto the crate lid, she loosened the drawstring on the top of the bag pulling it open wide. Together they went through her personal items, not that there were many. The changes of clothes were broadly acceptable through a few of her more excellent pieces got put aside. Some garments for containing wearable tech, others for synthetic fabrics. Nothing crazy Hitech but the deoder pads or the micro AC units were all no go. Her bathroom bag was another matter. The nail box, electric toothbrush, sonic sponge, buzzer and even hairbrush were deemed too high tech to take. The brush just had an anti-frizz module, but even that low power usage was too much for Scraps.
"Don't worry I can give you dumb alts for most of that stuff no bother. He won't question this lot or me and the Doc would kill him." Scraps winked at her moving some personal items back into the bag. "Now these though we will need more of a talk."
Left on the box top were her personal pad, folding knife, a small needle pistol and stun ring. The pistol was large for her but not overly so. The handle could hold around 300 needles which could be fired at varying velocities. The gun could, in theory, sort the needles into 5 distinct chambers for different loads but she had only ever used the cheapest lead load. A small plasma cell powered the weapon and charged the magnets, which catapulted the needles in a silent flurry. It was without question a killing weapon for someone who didn't want to be noticed. She had used it, more recently than she would like to admit to.
She had heard needle guns weren't legal in most places, but no one batted an eye at anything short of a tank in Anzania. It was a place of dangerous game, and well, the wall protected everything the mining consortiums kept a strict hold. She had heard nowhere outside a secure base would you find a denser concentration of military force as you would in the streets she grew up on.
The stun ring was a more everyday affair, sized for her index finger on either hand. It could deliver a concussive or electrical force depending on if you used the inner or outer nib. Practically this made it a punching or slapping weapon. Safe enough that even a child could use them, and they did. It was the preferred tool of club girls and delivery rats who could afford them. The small ring had a plasma cell that could hold maybe three charges on a good day though it should have kept closer to ten. She had got it off one of the gents at the club on her first week. The first time she had to slap a saucy clubgoer, she was surprised at how quickly he had fallen limp. The man had been a creep and a drunk not much meat, or she never would have the courage to try it though she was encouraged by its effectiveness. She had never used the ring to punch a person, but Bruno had encouraged her to try it on a melon one time. Queenie had made them both mop up the kitchen and clean the ceiling.
"Look, Pickles, the gun is just no go. Wouldn't be much use 'gainst most of what you will see on the wall. And it's plasma. Complete no-go in personal stock. Cap carries some but only for the most dire oh shit we going to die need. So likewise, I need to nix the ring. Can put both in lockup with a receipt for you or sell em. You call?"
She paused, thinking it over, "Won't I need some weapon on the wall?"
"Feck yeah, but boss man train you up on the clankers and whizzers. Big and small give you the whole run through when you get there. You ever fire an air cannon? Weee those things pack punch like a bull on bass. Not 'ike these squirt guns."
"Yeah. Sell em both," the sooner she was rid of that particular needle gun, the better. "What about my pad?"
"Keep it. I'll yank the plasma cell later, but you can plug it into the mains in the bunker to use it. No comms mind. I will dc the ribbon so ware don't glitch. Course cutter be no bother, everyone carries a blade. Just be sure to report any cuts. No blood on air, speaking of which I should grab you some clothes to replace what we pulled out. Be right back. In meantime help Ka out with the loading." She turned round yelling at the large Orc lifting a crate onto the flatbed. "Ka, show Pickle the stack. I'm going to go nip to the lock."
And without a further word, the little girl wrapped her gun, pad and ring up in the synth clothes and dropped them in a small cardboard box before skipping away. Yup, she literally skipped and sung a happy tune to a small set of stairs leading to the underground discretely out of the way of the concourse set between platforms 13 and 14. Pickle found herself looking up and seeing the tall Orc figure with its pale green skin.
The seven-foot-tall figure was triangular in build, his broad shoulders spreading the leather waistcoat over a bulging chest coloured in tribal tattoos. Detailed tattoo sleeve work showed an ink depiction of a kudu leaping from a bush fire towards a sun golden on the back of his right hand. Horns twisting to the tips on either side of the wrist. The tattoo flames covered his shoulder and part of his chest. On his waist, hanging from a heavy belt, was a silver knife the length of her forearm, looking normal sized to the brute's bulk. The pants also from hide looked crudely made at first until she realised the savage beauty in presenting a garment with as few cuts as possibles preserving the buck's pattern as close as cured leather could. Slim silver lines glinted as complex embroidery of metal cord picked out water symbols down the leg. To the soft wrapped feet, not in shoes but instead the four toe feet had a shoe-like item she had seen Orcs were before, though only tribal. The corp or civies tended to go for human-style shoes. This tribal warrior wore the more traditional wrapping style. Rawhide wrapping around the arch and ankle, leaving toe and heel bare. Similar to a soft leather boot or a fancy metamaterial parkour slipper but bare in front and heel letting the toes grip and heel feel out the ground. The goal was clear, direct contact with the terrain without the sole barrier between skin and turf. She wondered what they did about broken bottles and discarded needles, tough it out or were their feet already that tough.
She was still taken aback by her strange encounters. She found her eyes travelling back to the Orc's deep-set dark eyes, pausing at his mid rift. A slight glint of metal showed bolts in a pouch in the small of his back. Metal tips reflected sharp edges of light, calling them out crossbox bolts. Finding herself loose jawed in realisation, she looked up again at the Orc's face gaping as she glared at the grinning warrior. This was the knuckle-dragging idiot with the duffel bag and crossbox this morning who had almost run over her. Did she confront him, or...
"You remember me, little one? I expected a dancer's grace and light step from thee. The sunrise found your feet slow and stuck in the flow of humanity this morning. I apologise for my rudeness. I must admit to being something of a cloud head myself this daybreak." His voice was musical with a beating rhythm. Like every other syllable was seeking a drumbeat or a harmonic cadence. Nothing like the crude street patter she heard from city brutes like her friend Bruno. It was more akin to stage performer or bard.
"Huh, I know you?"
"Perhaps not, but I recognise your delicate form and sharp features, and not just from our bump this morning though I did not think of it till after our paths crossed briefly in the flow of souls in and out of this dispatch."
Wary, she glanced to her side, wishing she still had her weapons. Or just company. Crude brutes she could deal with and slimy rats with silver tongues but never before had she met a bruiser who let words dance as a street shine boy aiming for your pocket. Gunther was still loudly discussing matters behind her. She must be safe. She asked cautiously, "Where do you know me from?"
"Why, your dancing, of course. I thought that was clear in my speech. Maybe a week ago turned back at night haunt called Queenies. Never expected a dancing girl equipped for war on the wall? Silly, I know from one of my line, mayhaps I should say I never expected a dancing warrior from a human girl. Are you hoping to dance with the nightmare horrors, little lady?"
"You must be mistaken. I don't dance. My name is Pickle. I paid my stake." She defiantly flashed her metal on the wrist.
Hands upraised in a calming gesture, the imposing figure said in his soft booming tones, "Easy warrior, I meant no offence. I'm usually good at telling the soft features of humans apart. In this case, I beg you forgive the eyes of one long worn down by candlelight and night watch awash in the Lethe waters of entertainment this small hamlet offers to such as us who wish to dangle our fates on the edge. I was with friends in fine spirits, mourning the passing of a brave soul. Allow me to introduce myself," taking a slow bow, he placed his sun blazoned right hand over the middle of his chest with his left arm pulled back and outstretched to the sky. The bow almost completely folded him at ninety degrees before straightening back up to his impressive seven-foot height. His left arm coming to rest in the small of his back, with his right fist still centre between his two hearts in a formal pose. She had seen the vids of it but never witnessed a formal Tapola in real life, let alone been the honoured recipient. His voice rolled out in a formal march.
"I welcome you sister with my blood. I am Ka'Shek Patoresh of Keras bonded to Gunther's Guns. I welcome your drum."
Unsure how to respond to the fancy greeting so out of place from the rough street slang or slick shine of night talk in which she was fluent. Aggression, slang or sarcasm all seemed useless here. She reached for her most respectful voice used for honoured guests at Queenies. "Your attention shames my humble presentation, sir." Her tongue twisted on the next line realising she may have sunk her previous denials. "Um thanks, I guess. Scraps mentioned you needed help to move stuff?"
"Oh yes, delightful Samantha is always practical in her concerns. Forthwith let us transport the freight from the platform up to the boards of the train. We can stack and organise as we go. The load must be secured and fastened. Be not afraid to ask for help." He pointed to several small boxes and tarps as they organised their efforts. She saw most of the supplies were perishables. Foodstuffs, some medical supplies and the like. There were some chemical rounds and other munitions, but there still seemed to be less ammo than she saw on most platforms.
Also lacking from their platform was a grav trolley or simple lifter. Typically the helpful tools would have made moving the heavy objects a breeze. Instead, there was a crude mechanical loading crane for the heavier objects when Ka was too occupied. Thankfully it was electric. It made the work light and fast. In truth, Ka could lift most things, and much of her time was spent lashing and stacking.
Most of the cargo didn't make sense to her as Ka directed her to load up many barrels, flasks and canisters of strange fluids and compressed gas. How would they fight the nightmares of the wilderness with these? Surely, they would need bullets, explosives munitions or plasma power cannons.
These questions and more ran through her mind as Ka directed her to load with a musical rhythm. She found herself moving to an invisible beat as they hefted heavy and strange cargo aboard the train. Commands and grunts became a baseline beat with hands slapping and crates clanking on the counter beat. She even heard Ka humming a clear melody under his breath as he worked.
There were many large metal drums wrapped in cloth and padding. Not tall metal barrels instead, rather squat short cylinders about an arm's length across and hand's width deep. It was strange to see something so extremely heavy and study in construction be treated like fragile glass. Ka gave extra attention and care to them.
Finally, as they began strapping things down and securing the top load with a tarpaulin thrown across the load to keep dust and wind off. They tied the wrap with tight flat bands cranked tight. The argument between Gunther and the strange man appeared to have reached a conclusion. Neither seemed too happy, but she would wager from the smug grin the suited stranger had gotten the better half of it.
Gunther circled the train inspecting it from all angles before jumping up and grabbing the railing. His inspection covered the buckles and fastenings, but he paid careful attention to the canisters and drums. Gunther seemed, if not happy, at least satisfied with the job. He gave Ka a small smile before approaching him and thumping the centre of his broad chest with his right hand. Reaching up to hug the tall Orc. In the happiest voice Pickle had heard him use so far, he greeted the Orc.
"Brother Ka, good to see you. Apologies I couldn't greet you properly earlier. Inkwell ran dry?"
"There are still words on my quill, but I heard from our embattled brethren you were short-handed this rotation. I thought an early season to my liking."
"Glad to hear it. Scraps?"
"Off to get the girl new garments, I believe, though she should be back by now."
"Agg bloody hell. Minutes left. Give me a hand with the drive?"
"Sure, Captain. It would be an honour to speed our journey on steel wings."
Pickle was taken back by the exchange but, feeling thoroughly ignored and useless. She offered up her help, "Can I do anything, sir?"
"You know Spin Drives or have engineering girl?" Gunther's reply was brisk and without humour.
"No sir."
"Then stay out the way."
As the two burly figures went to work around the large drum and two bicycles without wheels, she glanced over at the other end of the loaded train to see Malcolm snoring while draped over some crates in the shadow of the loaded cargo of which he moved not a gram. Repelled from both ends, she sat in the middle looking up at the station clock suspended in the middle of the dome. It's one side facing them. Clearly showing only a quarter-hour standard before they needed to be clear of the platform. She leant on the railing, looking out across at the next platform. A busy squad was bustling, pushing trolleys and the like.
"Eh hem, a hand, please." A small and quiet voice came from below.
Looking over the railing, she saw the small clerk-like man holding up a small travel suitcase with tiny wheels. She had seen the sort by the fancy hotels or shuttle ports but it was such an absurd carry all with wheels so small only the smooth surfaces of hotels and ports could give any aid. She hefted up the bag surprised how light it was after the heavy cargo. It was made of fine leather with brass trim and zips. Delicate brass letters picked out the initials VN on the case.
After loading up the bag, she saw the man reach up a manicured and moistured hand while holding a metal briefcase in his left. She noticed his face was rather pinched while at the same time rounded. She wagered he never missed a meal nor a hot shower often. Judging by his clothes and manner, he was from England or some similar posh royal holding. Silver spoon, privilege and everything she despised and admired in one package. She offered up her hand and pulled the man up onto the train.
"Good day Ms Pickles. Allow me to introduce myself. I am Mr Northcott Esquire. Thank you for your assistance. Now, if you pardon me, madam. I must make myself ready to travel."
Without waiting for her response or acknowledgement, he shuffled off near Malcolm. He seemed momentarily baffled by the lack of seating. Holding his briefcase to his chest, he glanced at the mage, boxes and canisters. Deeming the area insufficient for his needs, he moved back a bit further, trying to move some cargo to make a seat. Though it was all securely fastened, Ka had been fastidious in his instructions to her, making certain everything was down tight. The little man made a seat of his travel bag against a crate and used his briefcase to make a laptop desk. He then started working on a small pad.
Little twit. She eyed the train seeing the massive pile near the centre. She climbed up atop the cargo pile, making a perch on the highest point. Looking out at the station from her lookout now out of the way. It was nearing midday, the commotion in the station was gearing up. Near noon was a popular departure time at the station. She knew that from watching trains but in truth, there was a trickle most of the day. She looked across at the station clock and saw the minute hand dropping down to half past the hour, only minutes left till their departure.
She saw a long sleek five carriage affair, all aerodynamic and manufactured, starting to pull out of platform 11. It was a creation from a corporate design team that had been stress tested in sims and then fabbed with the latest parts maybe in Europe, the Free Cities or almost certainly some chip fabs in orbit. Assembled in a clean room and then sent via connecting tracks to the station. It had barely any mileage on it, the smooth shape cleanly coated with corporate colour and logo hiding the nature of the materials or any seams in the creation.
The smiling anime chibi-style characters of the Power Solutions smiling, holding up a cartoon blue plasma cell radiating golden power lines. The blue gold emblem centred on that cell, a capital P with a stylised sun in the negative space of the letter. The company's main and most profitable product in the design with the gold lines radiating and wrapping the entire train. She watched as the train silently glided out on well-oiled wheels. Not even one of the arrogant big seven would send men to the wall on grav. Everyone went on rails. She heard some towers restocked by glider or emergy halo, and of course, the vid fics always had brave drop troopers landing in on exploding clouds of gel bravely to firing as the rescued and overwhelmed tower.
Watching one of the most powerful entities in the world send men to the wall on the same old metal path as her small company would be using gave her a sense of satisfaction she couldn't quite contain. Tic tac, always, it was tinged with that tiny tic tac spider of creeping horror in the back of her mind that even the mighty walk small to the wall. What had she got herself into?
From her perch, she could see a division of polished church armour division receiving a smoky blessing. Tribal drums beat a rhythm as dancers spun a circle around splashed blood. Were they crazy? Some smaller but more organised contractors board their multi carriage trains. Most electric with plasma batteries or steam, none she could see had spin drives, though she knew there were others she had heard them before.
That moment her watch was broken by the sight of a running Scraps hauling ass across the centre of the concourse with a strange-looking young redhead. The bouncing flaming curls drew most her attention but she noticed the two were laughing their heads off with joy as they ran towards the platform. They were shouting and waving towards the train. Gunther leaned out over the rail seeing the two running. Pickle, staring out to get a better look, perched on the edge. Who was Scraps bringing along with her? A loud roar from below made her jump, almost falling off her perch as Gunther yelled from below.
"MOVE IT, YOU DAMN BRATS!"
Gunther's bellow was loud and without apparent anger but left no room for doubt. They laughed even harder before both jumping up onto the back of the train and waving to him. Pulling themselves up the back of the train as Gunther blasted out instructions to Ka in the front, who was now standing firm holding a large lever.
"SPIN IT!"
Curious, she watched Ka pull on the lever, gripping tight the handle, which had a large clasp on it like an upright bike grip with a brake. The large lever made a clunking sound as it was drawn. Then she noticed that besides the firm stance, Ka was also secured by a belt and carabiner to a small rope leading to mounting rail along the rim of the protruding large vertical drum, which was half exposed at the front of the train.
It was during this moment of clarity she realised she was perched atop the cargo with no handhold. The train lurched with a loud screech and scream of metal as an explosive force like a pinball spring let loose unfolded from the drive. She slipped and scrabbled for a handhold finding none on the tarp held down tight by wide straps smoothly holding the load. Assisted by the platform release, the small train pulled itself out, screaming from the station. The unnerving scream of a spin drive in full release.
She found herself falling between the gap of the middle pile and the back pile. She had a choice between landing on a collection of secured metal canisters with metal nozzles and high-pressure contents or a sleeping mage unperturbed by his bed accelerating noisily out of the station. Kicking off the box, she directed her fall towards the softer and perhaps less deadly mage.
Moments later, she felt a hard impact hit the back of her head as she collided with something square. A flare of pain shooting up her leg before darkness and screaming took away the last moment of consciousness as she headed off on her bold adventure.
Yay adventure.
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Pickle on the Nightmare Wall - Part 1
Pickle on the Nightmare Wall - Part 1
Platform 13
She pulled the helmet tight, checking the clasp once more in front of the big metal dome as the cold morning air washed over her. Trains rumbled in and out of the station. Looking up towards the pink dust sky torn by gravity trails travelling south. She knew what lay south. It wasn't hope. She saw a single knotted rope of distortion tearing to the heavens, its frayed bottom torn wide, showing the ascent in the gravitational wake.
The morning shuttle had left. She didn't know when it had gone, but she clearly had missed it. Maybe when she was down in the hole getting the last of her supplies before leaving this place behind.
East-1 was the principal station on this side of the country. Harare served as the deployment point towards the wall and maybe her bridge towards the future. Checking over herself once more before walking through and mixing into the crowd. She felt a duffel bag knock into her back, stumbling forward as she caught herself staring back in anger, crouched, ready to fight.
She saw a gruff figure seven-foot-tall orc shuffle past her with a large duffel bag slung over its shoulder. The orc appeared to pay no attention to her as he wandered into the building. Crossbox secured on his back at a casual slant. The large beastly weapon was probably a pistol to him, but to her, she would have had to hold it with both her hands and brace herself, least the recoil send her small frame flying across the room. In the small of his back, he wore a small bundle of bolts, horizontal in their configuration. They looked small and diminished against this large frame. They were the length of her forearm and the thickness of her thumb. She looked around to see if anyone had noticed a moment of embarrassment before hiking up her bag and continuing. Going forward into the building.
She was good at blending into a crowd, even with her short figure and her mix of unusual clothing. In this audience, she didn't stand out walking just a bit slower behind a group of corporate marines with their fast march and corporate gear. They're all of similar figure and build, uniform in their equipment. Shiny and new. There were a few scuff marks of use and professionalism, but they look like they had all come off the same assembly line. Roughly the same build and figure, all standard human. They marched three by weight in a tight formation, clearing a path in the crowd. She stepped in their wake, lost in the tide.
The domed metal of the train station hub East-1 was noticeable in its construction. Unusual among the oldest style buildings squat brick and tall concrete or the newer prefabs printed shapes. It was a statement piece. Probably one of the last great constructions in the area. A testament to the wall project bent iron bars of unthinkable length bending and forming a gridded dome bubbling from the earth. To her eye, it created a cocoon around the hub. Crystal panes sat in the grid squares directing light. It must have been marvellous with its white stone floor reflecting light. Sharp shadows cast by the ring of pillars dividing the central concourse from the outer wall ringed with shop facades, platforms and ticket booths. Imposing metal frame and clear crystal causing light to refract and reflect brightly off the white stone. An impressive monument to what mankind can achieve.
It was constructed maybe a hundred standard ago though it had experienced something like 300 years real. Dust stains and grime on the crystal barely let the light with a patina of bird shit and caked dust blocking out large sections. The sunlight which hit the white stone showed stained and worn cracked slabs. Replaced haphazardly with off white prefab worn from countless people, walking through the smoked, polluted city. Just uncared for, like most things in this part of the world.
The layout was elegant and functional in its simplicity. The north was a series of train platforms jutting just past the pillars. Fingering out towards danger and adventure. It was a metal web spreading out the hub as tree roots would overlap as switching lines crossed over, and the trains exited. Always going towards the north. At each platform stood the various officers or dockmen prepping their trains for departure or offloading various goods. As custom drones and workers inspected each person or item returned from the wild wall. Too many lessons had been learnt to slack in their scans.
In the oval centre of light and grime stood military companies and friends. Some had just rotated out and were expressing the joy of being alive with their tribe. New tattoos and drinking stories would be shared by the firelight or in neon bars. Corp regs not yet ranked to the officer lounge hung about with an air of superiority polishing their equipment rated to just a fraction of more value than their employer valued them. Paladins systemically beat on a begging pixie beggar boy unlucky enough to get close to the holy wrath. They did it with a joyless ritual which made her sure they were due to ship out, scared for their lives if their faith would hold the line once more. The pixie boy had a shattered wing, not cheap to fix that, but was now crawling away sufficiently beaten. Lucky to escape with his life, maybe the Paladins didn't want littering on their bill or perhaps they were just tired.
The south wall of the building was for commerce and connection. Well, for many, it was safety. For her, it was no future. She knew what was made to the south. She had spent some time there, really there was no hope, and she needed to go towards the danger towards hope after all these years. Maybe she had enough. Wow, had she planned well? She knew she had enough. As long as she passed without issue. Moving along the south side of the hall past the shop entrances avoiding drawing attention to herself.
When the alcoves were built between the white columns, they were occupied by shuttle connections, scribes stations, weapon shops, and high commerce. Now the broken columns showed the years through grime and their rebar bare in places. The rim was blocked off corporate barracks, tribal offices, and delivery services. Occasional betting shops highlighted the lack of drink, outlawed now in the hub after too many pitched battles. The two original frontages still polished white of the original construction were the Scribes under Heaven office and the shuttle station where the wealthy and expensed travelled.
Coverings in the archways, you could see shiny corporate officers and warehouse depot, drop off points, where various deliveries and organisations, very little commerce occurred in the hub. This was a place of business, this was a staging zone, a place of functionality. Her stomach growled in hunger and nerves, her muscles tensing in anticipation, she needed to calm down. Looking around for relief.
She immediately spotted two small food carts. A pie store appeared to be run by a gnomish figure. God knows what's in those, but almost certainly meat. She wasn't superstitious, but she knew that eating meat before your first deployment onto the wall was a clear sign that you just didn't think. Staring at the other stand, she proceeded forward to it. The small cart with three heater plates and an old grey-haired lady, human standard, wearing apron and smile, sat behind it on a small stole. Sizzling on the hot plates, were a mixture of mostly mushroom, chopped root veg and some beans.
A shelf of unlabeled well used herbs and spices were accompanied by regularly squeeze sauces more identified by colour than label. As she walked up, the tiny tannie stepped off the stool and stood up, just smiling towards her.
"I'll have whatever you're selling," waving her hand over the hot plates.
"Good dear. I only have one thing on the menu. Mushroom chow. 37 credits"
It was a bit dear for street food, but this was a port, she reached into her bag for the cred stick. Watching the old lady, with minimal fuss, pull out a cold flatbread and throw it on the heat plates next to the mushrooms, pressing down with an old metal spatula. The searing. Plating hot mushrooms and burnt veg onto the bread she mixed in some cheese. Without asking she reached for a blackened sauce jar previously unseen and dolloped a large black spoonful of darkness and onion onto the bread. Smiling like a hedge witch over a brew or an alleyway spell slinger over dice she grinned a secret smile showing gapped teeth, "Pickles from my own store just for you."
Oh, thank demons and praise luck an Omen. A good one which she needed this day. For her name or at least the only one she matched the fates. The old lady folds and flicks over the flatbread with the spatula in a practised motion. Pushing it into the heater, caking bits of brown and burn, and a million meals before this, the flare dents brown-black against the white bread, leaving a fingerprint of time.
It makes a sealed warm meal.
Glancing at her stick she sees 508,011 credits. Spotting the slot, she thumbs over 37C for the meal, grabbing the hot wrap with hunger and viciously devouring it. The warm mushrooms ooze between chunks of cheese only interrupted by crunchy burnt veg. The blast of pickle offsetting the soft creamy flavours with a tart bite of memory. Sealing her mouth around the warm flavours. Within moments she is sucking vegetable juices off her dusty fingertips, smiling.
The old lady was impressed at the speed at which it disappeared into her patron's gullet. Rough living and jobs learnt her the ways of eating fast. She hadn't eaten a hot meal in a week. Her tummy had been tied in knots by the nerves, and this was the only way she knew to calm it at the moment, and for a change, she had the creds to make it happen, this time at least.
Licking her fingers and looking over the station. She made idle chatter with the old lady. Trying to examine the various groups and the mood of the crowd. You always needed to know the mood lest you end up in the wrong eddy like that pixie boy. Sure an organised regiment of corporate troops march through without a care. The crowd parting like the sea leaving a churned wake of bruised egos and careful mutters but most moved like fish in the currents. Watching she could see tribal groups form, organised squads coming off rotation, companies drinking and playing cards and swapping stories, and everyone in their own clique and group.
There was a mix of almost all backgrounds. Formalised by everyone wearing combat gear and a sense of shared purpose. Sure there was no one of her slight build or dancer frame.
Knocking on her helmet and hiking her bag up. She waved farewell to the old lady and carefully plotted her path forward. Taking a moment to consult her pad. She had stolen it from a euro tourist several years back. It had taken most of her credits at the time to wipe it and reclaim the device for herself with a local fix monkey. A few adjustments have been made over the years. The most expensive repair was substituting a blown fuel cell that exploded in a surge. It was perhaps the second most precious thing she owned. Irreplaceable with her budget and resources. It was a good trade, expensive and dangerous, but a good trade.
Pulling up the live schedule from the local net she saw the platform schedules.
GUNTHER'S GUNS PLATFORM 13 0930 - 1130
Checking the net standard time, it was 0947 on last sync, she had plenty of time. Approaching as nonchalantly as possible but along the edge of the concourse, avoiding any large groups. She carefully eyed the blue lights. Signage for each platform were boxes illuminated bright blue with white painted numbers on. The blue boxes picking out the various platforms with their beastly machines and organised regiments waiting to board. Until eventually, she came to platform 13.
It was not the first time seeing the crew. Still, with a fresh set of eyes the hunking beast that lay on the platform was actually one of the smallest trains in the station, a single carriage, but unlike the streamlined multi-carriages parked on corporate lines, all the various creative but ritualistic messes of the tribal trains.
This was a functional beast, nothing covered it. It was a flatbed. Perhaps eighty paces long and four pieces wide. Wood and metal flooring open to the environment with a simple metal frame. Wasit high railing around it. The cargo was lashed and tied down. Least it fly off but fully exposed to the elements with a few items shyly hiding under the smallest piece of tarpaulin. Towards the front and the centre of the wooden platform, there was the spin drive squatting confidence in it's mass and power. This metal beast's heart of tension and torque just waiting to be released. The wheels removed and sunk into the platform to either side and just behind the spin drive appeared to be two metal bicycles. She knew they must be connected to the gearing somehow and in some fashion, but at this distance and from this angle she couldn't tell how.
Most of the equipment and cargo did not yet appear to be loaded onto the train. The diverse assortment of boxes and loose items piled next to the train in a disorderly fashion separated from the crowd by a fold-out metal table at the front. The first thing to catch her eye as she looked to the table was a tall man wrapped in black, sleeping underneath the table, snoring loudly. He had a silly-looking wide brim hat, a dark trench coat with armoured iron plates, clearly visible in their creases and folds. Thick buckled boots with toecaps covered his feet. The gloved hand she saw was entirely covered with fingertips bulging in some strange fashion. His face was wrapped in a black sating scarf and goggles. Shaded black. She could not pull her eyes from the peculiar figure snoring beneath the table. Until moments later, a rough voice interrupted her fascinated stare.
"Can I help you, girl?"
"Gunther," her tongue tripping over itself, "Gunther, sir! I've come to buy my stake."
She pulled herself upright to her full height of five foot nothing as the tall man rolled over and continued to snore. Her eyes quickly flying to a point just a hand's breadth the man's forehead. He was no man but a figure of legend calmly sitting behind the small folding metal table doing paperwork... ye gods on actual physical paper.
She knew of this man, the Captain of this bunch. Captain Gunther or the Gun of the Wall as some of the older folks called him. The middle-aged man was tall but not lanky shy of six feet. He was built sturdy with no spare height or bulk. His shoulders were reasonably broad under the khaki jacket worn but well cared for. He was looking her over, scratching the stubble with a strong start towards a full beard. His dark hair was full and slightly curved, all his grooming pointing towards a man who favoured a splash of water and minimum fuss while maintaining basic hygiene. The hand doing the scratching wasn't a hand at all but an iron claw crude in design no magic runes or cybernetics here. Missing was the famous gun prosthetic and she could not see the arm she knew from town tales to be chewed off above the elbow.
His cold grey eyes took in her new boots, well thoroughly used but these had no holes. She was rather proud of these fancy pants. Well smart trousers she had stolen, well borrowed okay more procured for services rendered from a club patron nights before. Heck, the corp girl should be grateful, cheap really for the night, waterproof and self-cleaning the shimmering grey fabric was well above her usual. To the faded denim jacket over the loose cotton black tank top with the small khaki pack on her back. His eyes lingering on her face, her purple eyes and sharp features, before smirking at the rusted miner's helmet strapped tight on her roughly cut hair which was dusty black at the moment.
Gunther's inspection done, he looked her dead in the eyes and asked, "You're sure you are in the right place girl?"
"Yes sir, I wish to sign up. I have my share."
"Very well I assume you know our charter and all the standard stuff?"
"Been told it all, Captain."
"Well, you are bound to have some accursed stupid thoughts, but I'll leave you to discover those. There are official questions that need asking. Name?"
"Pickle." She hadn't paused, but she waiting for the expected reaction, he had none calmly writing it down, but she was sure she had heard a chuckle from the table.
"Family name?"
"No family."
"Title or membership under Heaven?"
"None"
"Are you currently or have you in the last year been a subject, tribal member, corporate citizen, serf, indentured, summoned or otherwise engaged under quest, geas or formal obligation under Heaven?"
"Free scum sir."
Sure, Queenie would lay some claim but nothing any outside town would care to back. The club didn't know where she was and wouldn't know where she had gone. She could be wired or bewitched and dusted to the winds or gobbled by bits for all they knew. Jack Jack's boys hadn't known where she was for years, and she knows they didn't consider her valuable enough to ink.
"What about the helmet girl?"
"Miner's helmet."
"I can see that, but where did you get it."
"Found it, sir"
"Very well if you say so. Girl, they will know once they run you, so remember to be honest on these. Are you currently under any debts registered to heaven?"
"None," or rather none that the mighty cared for. Small scrip owed to friends and favours owed and owned the cultural currency of the town in which she was rich and poor.
"Race?"
"Human"
He looked up again into her purple eyes, "If you lie to me it's Gods trouble for us all."
Unable to make direct eye contact, she responded with all the confidence she could muster. "No sir, human standard sir."
He paused, kicking the man under the table. She realised the snoring had been stopped for a while. Gunther's voice was monotone, "Malcolm, check out the girl."
The sleeping figure yawned and stretched in the most peculiar fashion. It wasn't a true yawn, but more like an oil slick noisily, expanding beneath the table. Flowing more than rolling or underneath the table, he extended up, lifting his shoulders too well about six feet. It wasn't like he had stood up but rather as if invisible strings had pulled him to his full height like a marionette. The strange wide-brimmed hat atop his head appeared to have a soft fabric cone collapsing in a lazy lean of folds. The hat's tip was actually adding to his imposing height. With all the dark fabric wrapping his form, he looked more mummy than man. All in black, not an inch of skin, hair or person showing.
His stretching yawn, arms akimbo, appeared to distort the space as his back bent straight and the room wobbled. No signed of muscles or bone that she could tell. He could almost be drawn into real life, like some crazed imagining. It was disturbing to look at his silent movements. Putting a foot towards her he stepped, pulling the room closer to him. Looking deeply into her eyes, purple reflecting in the goggles He stepped forward and looked deeply into purple eyes and then back at Gunther. Malcolm's voice was silk on silk sibilance with brass resonance. "You want to know what, the girls numbers?"
"No," the gruff man responded. "Is she safe?"
"Is it ever safe to bring riff-raff off the street?"
"Malcolm, can I put down human standard?"
She still hadn't exhaled watching this demon pantomime play out before her. She could pass. Without warning, gloved hands flew behind her, she tensed, expecting them to grab. The foul hands just floated over her buttocks and slowly went up her back without touching. It was somehow more intrusive and defiling. She could feel the tingle as his hand moved. She could not see it, but she could tell exactly where each fingertip was at any given moment.
Then just as she thought him done at the nape of her neck she exhaled. His fingers went into her hair between helmet and scalp, his fingers flew to her ears. No to her tips, the pointer tips of her ears. Thumb and trigger finger gently pinched both and withdrew all in a flash without and visible pause as his hands went back into his pockets.
That moment was the most intimate touch she had ever felt. She felt violated with her clothes on. Instant and total violation, she thought she would pass. She thought she'd be okay. The breath stuck in her throat. She couldn't finish breathing it out as her chest closed tight. Every muscle pulling in and pain flashing through her body as it tried to pull in on itself and disappear. To erase her from this world.
Most people didn't notice. Yeah, sure. The eyes, but everyone, okay maybe not everyone, mostly everyone, maybe even half of everyone, but more people than most had something. Eyes were common. Nice. Hell she didn't bother hiding them usually. For day to day she was generally able to tuck her tips in a hat. Hell even tucked into a bandana or even just her hair if she was careful.
If she was lucky, it was good enough. The helmet was surefire. The helmet was sure. The helmet was iron. Oh, what is she's gonna do. She had enough of share, but she didn't have enough for certification. She didn't have enough for insurance. She was done. She was doomed. Shouldn't have come. Back to the club, she went.
Oh, God. If this man had tried this at the club, he wouldn't last a moment. Bruno would have bounced him into the alleyway? She didn't care if he had any bones left. No Bruno would bounce him off the alley wall anyway. Bones or not they would have crunched and cracked, and he would have bounced and rolled, and it would have been the most hilarious thing in the world. Just sick twisted de... demon of a man would not exist before her.
She had wandered through the filth and dirt of this city and other others. The club was vile, but at least in the club, even though there wasn't a classic uniform, she and the other staff wore a uniform attitude. She was other. She was apart. She... she was safe. There were rules. Never before had someone so instantly, torn apart any shred of confidence, spent so long building, to come to this point and see it all fall.
"She's standard sir, well standard enough," Malcolm's voice flowed like a knife through her mind, he knew. Her train of thought derailed. She stood shocked and shaken to her core. She couldn't form a sentence in her mind, let alone on her lips. As she watched the silent exchange between the gruff man and the tall demon.
Silently she cheered on her hero, come on, oh Legendary Gun of the Wall. Gunther the Great will slay this vile demon and free her from this paralysis. Captain to one of the last free companies, guardian of humanity. The man before the nightmare army, please free me from this horror.
He seemed to shrug as if it was nothing.
"Well, that's the paperwork filled out. You know the share is currently 500,000 right?"
"Yes," her voice squeaked in shame as her hand shook. Her rage welled and pooled in her eyes, threatening. All that uncertain energy rushing into flight or fight. Unable to fight, being pushed into some pathetic moment. She would not break. Falling back onto formality, she barked. "Sir 500,000 credits for company share ready to stake."
"Okay, well, we've got the birth until eleven-thirty standard but I expect you to be back by eleven and inspected by scraps. Malcolm. Take her to the office of the scribe and get the paperwork registered. Sign it girl."
The form was now completely filled out. He pushed the form and a pencil in front of her. Signing her name in lead she eyed the top of the pencil with its sharp blade. Running her thumb over it, she pressed the small cut over her name. Blood and lead mixing name and print. Pushing the form back to Ganther.
Gunther takes it signing his own before reaching for a wax stick glittering next to him. He takes the wax stick, the mark of scribes and captains pushing it on the heater then paper. Pressing his thumbprint into the wax. Captains, didn't cut themselves. The saying went, "Captains had no more blood to spill and scribes have none to give". Gunther folded the form and handed it to Malcolm, who took it with a flourish.
"Make sure there aren't any problems, Malcolm," Gunther's eyes underlined the sentence. She couldn't see Malcolm's reaction as Gunther continued, "I'll wait for the geek and Russel. Get back sharpish. This is the last stray we sign today." With that Gunther seemed to start clearing the table.
"Come on, kitten," Malcolm's voice cooed behind her, "We'll be late."
Without shame the son of satan slithered his way to the south side where the scribe's office stood. She marched ahead, determined not to follow after the arrogant fool, let him be her shadow.
"Now now, kitten you will leave me behind," his voice came on her heels as he lazily followed.
She slowed her step. Grabbing the blade in her wrist cuff, she swung around as fast as she could and closed into him. Pressed the cold silvered blade into his stomach. She found the kink between two iron plates and rested the sharp tip against his skin with light pressure. She was confident she could drive it in with a moment's notice.
Looking up, staring into this tall fiends eyes as he slinked and curved. She just perceived darkness, dark goggles, dark cloth, looking down from the shadows of that ridiculous wide-brimmed hat. With the most venomous voice she could summon born in the dark pits, sharpened by the street and polished in the clubs, she said, "Address me like that again or touch me and I will have your guts on the floor. I don't care what Gunther says, you are a foul creature."
She could not see his smile through the wrapped fabrics but she could feel it. The mirth dripping onto his tone as his melodic response, "Of course kitty. Play nice now Pickle, or you will make daddy Gunther sad."
Pulling the blade back, she stalked off with a new purpose. Malcolm had called her bluff without hesitation or fear. Feeling the tall shadow follow her she decided then. She would not give him the satisfaction of guarding herself. She would show him the disdain of dismissing him as a threat and allow herself to be blind to his theatrics.
Walking into the office of the scribe was like stepping back in time. It was almost enough to forget the foul encounter. Grime and neglect painted the rest of the train station but here the white stone was clean and the crystal shone brightly. Crisp air sharp with polish and the smell of clean aged carpet as green felt carefully traced a civilised line of approach, lest the floor be marked by time.
Thick black knotted cord ran crystal poles waist-high separating the lines of carpet. Organised to lead a queue to three fine windows carved out of white stone with a heavy wood door discretely off to the side. The countertop was white and worn but clean. The windows weren't anything as brash as crystal, glass or bulletproof synthetics. Instead finely hammered iron formed complex patterns of leaves and flowers all polished black. The delicacy of the smith's work could make one forget the sheer stopping power of a thick iron grill that let sound, air and the barest light through.
They seem fragile but brutish at the same time. She had never quite seen such delicate artistry performed. The fact that the metal was kept clean of rust or mildew or artifice made them feel otherworldly. Rare to find anything in this part of the world that wasn't covered in grit and grime, dust and neglect, forgotten and left behind by humanity as they ravaged this corner of the world.
Only one counter was occupied. You could just barely make out the silhouette of someone knitting patiently unhurried. Confidently, she walked up to the scribe counter suddenly conscious of the ringing sounds of her boots on the stone just as the carpet swallowed them up. Her stride faltered for a moment before approaching and declaring, "I'm here to buy my share."
"Oh darling," came a kindly voice from behind the window. "One second as I put down my needles. Now, what company?"
Before she could answer, Malcolm reached over her shoulder and slid the folded paper form through a purpose-made gap in the ironwork. She had overlooked the flowers parting there, and a large leaf presented a slight lip. It was a subtle effect, but it was easy to spot once you knew it was there. She could hear the paper being unfolded, the keyboard clacking away. The scribe's motherly voice was punctuated by her key presses as she talked and worked.
"Gunther's Guns, my my an unusual first posting for someone so young. You sure you want to join such a group of scoundrels first time out? Join them if you must but many a fine corporation, guild organised tower. Maybe an academy tenure or one of the church towers. Free Towers are rough places for a girl of your age and the corporations or church both have long prospects?"
"Thanks mam," she interrupted the scribes' advice. "I prefer my freedom."
"Very well, I know better to try talk a lassie out of loony. I myself, oh well. They come with no backing and their tower is a rickety one. Gunther's men mostly come back it is true. He does run a tight ship, oh but if you could see him back when. Ah well the sky was brighter. You will have to deal with his crew..."
At this last statement her voice lost some of its sweetness and she appeared to look at Malcolm. He was currently examining his bulging glove tips as if they were painted nails fresh from the salon.
She tried to ignore the exchange, "That's okay I have confidence in the captain."
"Oh well let's get you in the system. Currently seven registered stakes this season, excluding the Captain of course. Charter is even stake so that means you'll get an eighth share, less the Captain and wall dues. Unless anyone else is signed up today?"
The scribe had pointedly directed her question upwards at Malcolm. His oily voice purred out flowing over her like waves of slick. "None so far."
The scribe continued, speaking to her once more. "Right well deary the stake will come to 500,000 credits this season per the Gun's Charter. Do you have that dear?"
"Yes."
"You have any debts, contracts or outstanding gravity debts under heaven?"
"No ma'am."
"Right, oh dear it looks like the ident number on here is blank. Have you not dealt under heaven before?"
"No ma'am. Gunther's Charter covers free agent registration."
"Unusual for one buying a stake," an air of question flaked her voice. "So registering you before heaven as well. The Charter does indeed cover that in your stake, but it is unusual. We have a blood signature and I see the Captain has filled out Geo Neutral Aligned Type."
That stun, she was technically a gnat. Few would hurl that insult in the city knowing its vile consequence but she knew it was a technical term. Besides at the end of this conversation she no longer would be. Without pause the scribe had continued on, picking up the thread again she heard her continue.
"Check can take a while but you will be in the system immediately. Oh dear, one moment we have a fracture. They tend to clear fast. You know we used to have to wait for the gap between, and there it is back again. Oh darling you know you can change your name under heaven correct? No fee if you're registering now."
Pickle blushing, she knew people laughed but it was her name. She hadn't used it in the club and not many in Jack Jack's knew it. Though everyone she ever considered a friend knew her by that name. It was hers, given in love.
"Pickle's fine ma'am."
"No family, clan or last name? Many people take an approved free name."
"Company name only ma'am."
"Pickle of Gunther's Gun. Very well next of kin or beneficiary is named?"
"None known."
Their rally of questions was interrupted by Malcolm leaning onto the counter and looking directly at her, "Pardon me. Just don't child. You must name a blood benefit. We could kill you and the share would revert to the company. It is just too much temptation. Name someone, it doesn't matter who."
The scribe added, "Many name a charity or local establishment in repayment for kindness."
Kindness, she thought, remembering clawing her way from the depths to the limelight to where she was today. No charity. That wasn't technically true. There were those nuns in that Pretoria hospital the winter she had gotten sick. Oh, and Ghilli soup kitchen. Ghilli was safe and nice. Their wife Jenny was a friendly face for an urchin who needed a cheap meal. She softly ventured, "Ghilli soup kitchen in Mutare." She could hear that click-clack of keys. "I'm not sure of the business name."
"Well dear, I can find no soup kitchens registered in Mutare. I cannot list a benefit without a formal ident. We could send a letter of note?"
Malcolm shook his head, "No girl. Scraps could take it after our run, but nothing stops us saying we delivered it when we did not. Pick someone, anyone."
She tried again, "There is a hospital in Pretoria by the hill run by nuns. For sick children."
"Found it, yes I know it. Saint Angus on Mountain View. Yes there it is."
She had forgotten the name. It had been so long, she never would forget the pink fluid they gargled or the smell of the halls. The winter had been long and her leg was infected badly. The cold and pain had cleared and she had seen purple. She still loved that shade of purple flower.
"Yes ma'am. That's them, they were nice."
"Okay. Almost done, any magic to declare."
"No ma'am."
"You have that certified dear?"
Before she could react, Malcolm put his hand on the counter, clacking his fingers one at a time. Punctuating his words, "Human standard, dormant. Certified apprentice of Malcolm the Magnificent. Magus Academy." His finger's paused before he quietly added for her ears. "Apprenticeship has no fee girl."
She wanted an object, apprenticeship to this creature. Never never ever, but she couldn't afford the certification on top of the registration. She wasn't sure she would pass an official certification and a street cert good enough to pass register would cost almost as much if not more. Hundreds of thoughts passed through her mind and she tried to plot a way out of this new hell. Her hope is now tainted by the black stain. The sooner she spoke and washed off this stain from her new clean identity the better. Her voice sticking. Hope tainted. She couldn't.
Was he helping? He was helping, she thought. He had offered the advice and Gunther had sent him. No way would this fiend be helping, indeed he was was toying with her. Her mental exploration of her companion's motives were interrupted by the scribe.
"Okay? I have you registered. You have the stake in credits?"
"Yes." Breaking out of her drowning mind she pulled out her stick and slotted in the small illuminated slot in the counter. She thumbed over the 500,000 credits. The stick vibrated against the large amount. She quickly keyed her complete sequence. The small stick was only rated for a million tops. Its crude needle pin pieced her trigger as she keyed pulling the last piece of confirmation. Her fortune gone, the stick felt light. She felt the world swim in a moment of uncertainty.
"Give me a sec dearie, it takes a while to communicate with heaven. That orbital tore a fracture larger than most this morning. The pilot dropped like a stone. Ah there it is."
Apparently it's an eternity to heaven but a moment to us. Never mind when times slip a curse to hears the old printer file. A fire or fire up. The click and clack as paper moves and the receipt slowly rolled out. For a moment, it paused, then a slim metal plate the size of her thumb but thin as a fingernail clinked onto the large leaf which formed the letter slot in the grate. It was, of course, iron but in the elegant shining letter of gold written by the scribes practised hand was her name.
Pickle + Gunther's Gun
Lifting up the plate in shaking fingers she pulled out a small cord from a fine pouch in her pocket. Threading the expensive cord through two small holes in the nameplate, she wrapped it around her wrist. The cord slowly tightened and pulled as it felt the warmth of her skin. Slowly she watched the cord melt into her skin, drawing the plate into her right wrist. Embedded into her skin her identity forged in iron strengthened by blood. The letters of immutable gold holding her name and company.
Her name was written in the stars of heaven, she existed forever. No longer was she a mine rat in the darkness. No longer a street gnatt running. No longer a club girl in the bright lights. She existed. Yeah, Jack Jack's boys might find her. Yeah. Queenie, might wonder where she went off to. They didn't know if she was wired up or dusted out. Let them think her lots to bits or blown on the winds.
A registered standard human with a free company and capital stake, she had a future. She believed in the moment. Striding out into the hall with confidence, walking to the platform to catch her train. Arms stretched out, she hooted at the top of her voice, a guttural cry of triumph wordless in its joy. Shameless in its volume. For she was heaven wrought!
Unnoticed behind her, a black shadow stalked behind, a vertical oil slick flowing after. As she stopped by the platform, she paused once more, hearing that soft voice.
"Welcome to Gunther's Gun. Please die slowly."
Afterword
This is an ongoing web novel updated every Thursday. I really hope you enjoy it, this is my first attempt but I've spent a lot of time in this world, over two decades. Running roleplaying campaigns, writing comics and creating stories so it feels really natural to tell a story in this world.
Started at Adobe
Started at Adobe

Well, after almost 15 years chasing video games, I decided to do a bit of a side step. I still love games, and I could easily see myself working on them again. At this point, I looked out at stuff, and well, this seemed the right move.
Leaving Mm and Sony was a tough call, but I wanted to push VR, and well, I knew that PSVR2 was mostly locked. I could see the road ahead for me in my role, and it wasn't contributing to the VR future. I had done my bit, and it was time to move on.
Speaking to a whole range of companies from hardware to middleware to games companies and even some odd platforms, which I quite love, there were options on the tables. They were all appealing, some familiar and others required life changes which couldn't gel with our new flat and my lovely life with my wife in London.
One of the first people I spoke to after I decided to leave was Anton. One of the four horsemen of Dreams. That is to say, one of the four technical people at the heart of the project. I have a lot of respect for him, and well turns out he had ended up on Medium who Adobe now owned. We had been speaking about Medium and our thoughts for a while, so it was a natural conversation. It was a great team, after lining all my options on a table it was the best all round. I joined.
I don't want to speak about Adobe or the team, but rather the vision which drew me away from the highlight of my career, Dreams. Virtual Reality is what drew me into Sony in the first place. I've been chasing this Dream ever since James brought the DK1 into the studio and we started making little things for it. Virtual Reality is compelling in so many ways, but the best way is its ability to immerse and engage on a whole new level.
Now I hesitate to write about the metaverse because, like so many wonderful things the tech bros have "claimed" it and pissed all over it. Though connected, persistent universes have been a dream of many since the early days of networking. I hate writing network code, but I learnt to do it because of this dream. Connecting people is powerful, but I also despise walled gardens. Though more than anything, I worry about corporate dystopia caging those dreams.
I remember the early internet and the revolution that images made as we started attaching them in bbs and later forums. Early webcomics were more about image compression and technical knowledge than art. That was why I could pull off doing them. Though as the tools got easier art exploded in a way that I don't think people understand how profound it is. Now folks don't even bat an eye at a quick photoshop meme. The tools for digital art so common that like the doodle the image meme has become the medium of our time.
When I first joined Sony, I did a lot of research, talking and yes, pitching for metaverse tech. SocialVR from the Online Tech Group started as a series of emails and phone conversations when Richard Lee asked me, "What does VR communication look like?". It was a question near to Shuhei Yoshida's heart. Though the scars left by PlayStation Home run deep, and corporate memories are long. I won't talk about all that work, mostly because legally I shouldn't, but we did some great work and shared what we could. Solving many problems years before, and I know influencing others. The gesture system in VRChat pulled from a community mod is directly covered by our gestural emotion system we demoed at GDC, though ours was a bit more subtle.
Though an issue I knew from day one was content. The metaverse needed content, and well, every time I was asked about the problem, I just pointed at Dreams. It was the solution. Why worry about polygons, use spatial input and build new UV free pipelines. Teardown those barriers, let people create. Well, it's obvious why I ended up moving from central tech to Media Molecule in the end. It was the most exciting content creation and virtual reality project in the world.
We shipped it. As I already said, the highlight of my career.
While Dreams was happening, the tech Alex had shared at Siggraph and parallel invention was hard at work, and now the field is brimming with SDF modellers and the next generation of tools. One of the original big movers in the space Oculus Medium.
The choice to join and help build the next generation of 3D sculpting tool with that talent, people from Tilt Brush, Maquette and now two of the original four Dreams tech people? Well, I had to throw my hat into that ring. So yeah that's how and why I left the games industry.
Or at least moved to the sidelines, still cheering it all on.
So here is to modelling the metaverse and building that open future.
April Update
April Update
First off new job which means a bunch of things but mostly a project update.
The video should be on the main page at the time of posting but here is a link if your in the future.
I've updated the experiments page with a range of stuff. Here is a brief overview.
Software / Hardware Dev
- ThimBall Controller - Alternative VR controller design
- TinyXR - OpenXR / Vulkan engine with SDF / Volumetric approach
- Dig Deep - Game project built on TinyXR
- Magic Shop - Casual Game
- OSC Twitch Extension Bot
Books & Comics
- Ducky Book 4 - Final Draft, art ect..
- Ducky Book 5 - Starting editing and appeal pass
- Ducky Book 6 - First Draft waiting on my edit pass
- Virtually Unknown - VR history comic project
- South African Tales - Comic slice of life stories from growing up in Africa
- Space Survival - Writing 1st draft
Video Projects
- VR Interview Show - Two interviews in the can, need to work on branding and editing
- Morning Monsters - Ongoing but a more Tech / VR slant with occasional Game Dev now
- Skate Southwark - Skate all of April challenge and new YT Channel
- AR Short Stories - TikTok / YT Short format project in RnD atm
So yeah a ton going on. Some of it will slow down as I start the new job which I will be letting you all know about soon.
First Jab
First Jab

I'm now officially protected against Covid, or rather in two to three weeks, have a pretty good immune response, with a second jab bringing me up to the high 90s. That is because I went I got my first jab thanks to the NHS deeming me a high risk younger person. No idea what put me in that risk group, potentially my weight which hasn't been great. I thought it might be helpful to note some thoughts down on the experience to show people its all good and as a record for myself.
I got the first text on 6th March 2021 3:51pm stating I had been placed in group 6, 16-65 with underlying health conditions, and I could use the unique link in the message to book my jab. Going onto the website a few hours later because I missed the text, all the spots were taken, but I was told to try again later. The following day I was gaming until 1am, thanks Valheim, and I thought I would try before I retired. Sure enough, there was now a broad selection of slots starting Monday the following week.
No way was I going to do Monday, nor was I going to do anything before 11 in case I slept in. Not to mention a desire to avoid the London rush. So 11:15 on Tuesday it was. A quick form later, I got a text confirmation. It was great, and my vaccine centre was just up the road, maybe 30 minute walk. I should add that I also got a reminder text the day before to make sure I didn't miss the appointment.
I was giddy and excited, it has been a long year, and really, this is the actual end of things or rather the beginning of the end. My mum and a few friends had received the jab but most people I know are without, so I knew I was lucky to get in relatively early. It is with this giddy excitement that I turned on the news beforehand to hear about Germany stopping the Oxford jab out of concerns about rare brain blood clots. I cannot express how nervous this made me, someone with high confidence in the science and excitement to get the jab the next day. I honestly think they acted irresponsibly. There was an established method of evaluation within the framework of the EU, and they broke it. Personally, and on reflection, I think this was a political move. I swallowed my fears and headed off for the jab, and I'm glad I did though I can say quite loudly atm Fuck Germany.
Heading off to the clinic, I double-masked, thinking that it was a high chance of infection going to a medical place, even if they do say don't go if you feel ill. It was a pleasant walk, but I haven't been exercising enough, and I felt that for sure. On arrival, I'm giving a small question sheet and a medicine sheet with all the usual details: allergy questions, blood thinning questions and the usual stuff. After a short wait, the Doctor saw me. She was lovely and kind. Advised me I might feel a bit poorly and just to take some paracetamol if I do. Jab got I walked home singing and dancing with an enormous feeling of progress. It was lovely.
Mostly I felt okay until after a gaming session that night with friends, the fever hit. I went to bed with all the symptoms of a cold/flu kinda thing. The next morning I felt terrible but manageable. Some paracetamol and a bunch of couch rest, something I always hate and suck at, and then by the time I woke up this morning, it was all gone. I feel fine, and in two to three weeks, I will have a pretty solid immune response, just in time for stuff to open up a little more and for me to have some stronger confidence in my future.
The NHS is truly a wonderful thing that has done so much for me, my family and my community. I can safely say I would not be alive today without it. ♥ NHS ♥
Lip Sync in Virtual Reality
Lip Sync in Virtual Reality
Recently I've had a bit more time between leaving Media Molecule and starting my new job. I want to explore a few concepts, some of which I think are worth writing up, if only to work the ideas through my fingers. Lip Syncing in virtual reality is an interesting one that seized my grey gooey bits the other day so let us explore it.
The issues with computers are they like numbers. If we were to take a full-colour high-resolution photo of your lips, it would be somewhat useless as we would need to convert colour pixels into red, green and blue floats—one for every pixel. So the first simplification is to use Luma, a type of greyscale image. Then instead of using a high-resolution image, use a lower resolution image. Working at lower resolutions also allows us to work at higher framerates which you will see come into play later.
Our approach could branch into tracking a volumetric dataset and building a 3d model, a generic and highly potent system that, while more data-intensive, allows this method to work on all face shapes, including those with medical conditions or some future two mouthed alien we encounter. The limitation of this approach is it will only ever show what's real and is an absurdly large volume of data, especially in a large space with many people. We will put this approach in our pocket for later discussions and instead wonder how we can break it down into more abstract data. Think about it as the difference between a picture and a drawing or vector illustration.
Motion Vectors
Feature tracking and filtering allows us to boil the image down to a set of tracked points but doing this all in software could be a pain. It turns out through a beautiful instance; the data needed to improve video encoding can help us. You see, cameras get this raw image data, but instead of saving it to lots of bitmaps, we compress it into JPEGs or similar, and for video, we use interpolation frames, commonly called I-frames. More complex variations exist but aren't helpful to the discussion. This work is computationally complex, and camera manufacturers wanted to reduce cost, complexity and size, so they developed specialised silicon, which is purpose-built to find motion vectors and gradients.
Motion vectors, simply put, are a data store of the pixel colour and the estimated motion that pixel has moved. They are useful because if a car drives across the frame, we can re-use data when encoding to compressed video formats with I-frames. For us, it provides some useful motion data to allow us to pick out features. Hardware in some devices allows fast detection of gradients mostly used for digital focus algorithms but is also extremely useful for detecting features in images.
Building on these fortunate developments allowed computer vision software to get a boost in the last decade. When breaking down a face, we are often looking for motion and gradients. Things like the eyebrows, the shadows they cast on your eyes, the distinct shadow under your nose and the shading of your chin and lips help us anchor our model. Complications like facial hair, long fringes and glasses are just added complexity. Though in the end, we should have a facial feature track with between 8 and 64 points depending.
The final step is don't think of these points as full 3d positions; instead, we can encode this data down further to relative spaces and reduce the inputs we need to feed into our system.
Visemes
The issue now is one of output. We don't want to generate a deep fake or some other image data. We want to drive an animation. Something that algorithms are good at is tacking that set of values and developing a set of confidence values or a conceptual point in space; approaches vary. The easiest way I can explain a common practice is to imagine we map the mouth open to the Y value on a chart, and then we map the wideness value to the X value on a chart. For any combination of mouth open and wideness, there is a valid representation on this chart. So the algorithm just needs to place a point on the chart.
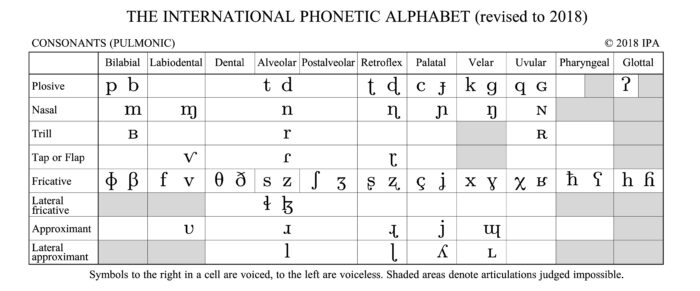
Perhaps the most exciting place to start is giving our current biology and limits of the human range. We know that there are only so many sounds the human mouth can make. The Phonetic Alphabet is based on sounds rather than mouth shapes, but its an excellent place to start. As a result, we also know there are a limited number of forms the mouth can take. Outside of the silly faces and blowing raspberries, the focus can be placed precisely on speaking.
Try opening your mouth as much as possible, making a tall O shape. Now smile, smile more and make your mouth as wide as possible, making a long dash shape. Those are our limits but notice you cannot have a fully open and wide mouth. Instead of an infinite plane, we form instead of a find of oval shape where the point can be on the paper. This geometry is our possibility space. I have say eight expressions that map the possible mouth manipulations. We build this complex 8th-dimensional possibility space which is easy to talk about with maths and computers but very hard to visualise. It will have very likely spots and improbable spots with edges fading to impossibility.
My first exposure to mouth shapes was the classic animator's handbook which so many have poured over for its depth of knowledge. This page should look familiar. This breaking down into shapes rather than sounds allows us to merge into a smaller problem space than the full phonetic alphabet. The most common use case I think most VR denizens and artists will face are the VRChat Visemes.
I have heard Visemes describe as representing an axis in that possibility space. This is an okay approach but leads to smearing and, honestly, a larger dimensional space than is needed. A better system is to take those hot spots of high probability I mentioned before, being sure to have points near the edge represented and build a set of points, like planets floating in this multidimensional space, each with their own gravity. You don't care where you are in space but rather which planet, or maybe two or three planets, are nearest to you—giving you the mouth shape you need to create from 1-3 blend shapes: the fewer shapes, the more distinct and readable but the less smooth the transition.
Japanese vs Western Animators
An important side note in this discussion revolves around Anime and the Japanese language. The IPA chart I put above is representative of all languages, not just English. Some languages use more and others less. English with its habit of beating up other languages and stealing their grammar and vocab, has a pretty broad presentation. Though try to get an Englishman to roll his Rs or a fine Lady to get the plosives of Xhosa, and you will have a fun time laughing. For various reasons, Japanese has very few sounds comparatively but also focuses on the sounds with not much rounding or mouth manipulation.
Studies have shown that native Japanese speakers barely use lip reading to help to understand words. By comparison, English speakers have auditory hallucinations based on what they see, allowing for a wider range than the pure audio. Don't believe me watch this video from BBC Horizon on the McGurk effect. As a result, animators in Disney and the like have whole departments dedicated to lip-syncing as it's critical to sell the character.
By comparison, Japanese animation has mostly made mouth flaps, or envelope tracking, with only the occasional emotional scene getting the full lip treatment. This has a substantial cultural effect but also an impact on technology. It's no secret that Japan & China lead the way in Virtual Reality and a critical but tangential area, Virtual Avatars. VTuber tech of today, and much of the motion capture tech, was developed in Japan. As such, engineering effort has been spent in certain places and not in others. This also bleeds out into content like the dominance of Japanese art in VRChat, leading to less emphasis on distinct Visemes. Some plugins even generating smoothed out estimates of key shapes based on 2-4 example shapes.
Virtual Reality and New Devices
With HTC once again teasing their lip tracker, years after it's debut in the dev space, and other big players entering the space, it's time to talk devices. The HTC device is a dedicated lip tracker camera, purpose-built for this tracking. The Decagear has both an upper and lower face camera for tracking, so they will have a dedicated lip tracker. Additionally, we know Facebook is developing a range of solutions. Many other's have projects not yet in the public space but safe to say the facial tracking cameras will be standard tech in new headsets within five years.
Remember how earlier I talked about luma cameras and high framerates. That matters because the most effective cameras use infrared LEDs and because your skin is more distinct under IR light. Also, facial hair is easier to ignore, and items such as glasses show out more distinctly. Another benefit is most make-up does not affect this. The high framerates give better motion vectors and allow higher confidence by tacking multiple frames of data and smoothing the result. Some models even apply movement constraints to avoid jumping data points.
The camera isn't the only data source the HMD also have microphones that allow us to map mouth shapes and phonetics to improve the models. Additionally, muscular or electrical sensors on the interfacing plate can also drastically improve the tracking. Open your hands into a loose shape like your holding a large ball and place your fingers below your eyes where your VR faceplate rests. Now make all the funny mouth shapes you can think of and talk, notice how distinct your skin and muscles' movement under your fingertips is?
I should point out everything we are talking about here is already technically BCI, Brain-Computer Interface, much like your keyboard is. The really juicy stuff is EEG & fNIRS but let's leave those topics aside for another discussion.
So this all provides a robust lip-sync and viseme based platform, and I think it will be the approach most tech takes—finally, one last side note on facial tracking vs lip sync.
Facial Tracking vs Volumetric Models
Now I've been focused on lip sync, but the conversation extends out into facial tracking easily, and you can look at Hypersense, now owned by Unreal devs Epic Games, or the FaceID work in mobile phones like Apple to see how this scales out. Instead of Visemes, they have a range of channels, some of which interact and others that don't. Your tongue sticking out does not affect your eyebrow position, for example. However, the approach is broadly the same.
Remember our two mouth alien? Well, it turns out some people fall out of the normal dataset, and for these people, this data modelling approach really sucks, and you could see some digital exclusion happening. We already say this with early face tracking on some racial groups or even just people with longer hair. Also, this approach is limited in scope, so when Ace Ventura walks onto the digital stage, we cannot capture that full range of motion. The solution to this many will point to is volumetric capture and playback.
There is no real difference between volumetric playback and capture than video from a webcam with the noted exception of depth. As such, it is creatively limited. Snap filters or their holograph equivalent are possible. Beauty filters that remove double chins and even emotional filters which hide nervous ticks or solve resting bitch face for those us lucky enough to have a face destined for galactic conquest. Ultimately though, you are sending a much larger amount of data. Instead of 16-80 floats compressed in relative space, you send a high resolution 360 video with depth information. Using facial models, you could compress the data, but then you get all the negatives already discussed without the freedom of a full abstraction.
The shift from traditional animation to computer animation saw this pain point with hard rigged models limiting animators' creative freedom. Over time they started building bespoke tools, and modern animation flows quickly flesh out scenes with automatic lip-sync tech or motion capture. Animators later tweak and sculpt with all the freedom of traditional animation, even replacing the face entirely. Tweaks can be done with canned animations, or if the confidence value is low enough in the model, you could switch to a point mapping distortion from the HQ source or a range of other fill-ins. I'm confident though even with these bells and whistles, the double-edged blade of compression and standardisation will push us into standardised data formats for a wide range of applications. Much how phone calls could be significantly higher quality, and once were, but economics and technology ushered us down a compressed VOIP line which brutalises hold music.
Conclusion
All that taken equal the TLDR is
- Facial tracking hardware based on audio, IR camera and skin contacts will be widely available within five years
- Tracking models will settle into a handful of abstract data standards
- Expect Visemes and Blend Shapes to dominate with custom animations sprinkled in
- High-End volumetrics will be used in limited cases but lose out due to bandwidth and creativity
Book Review: Reborn as a Vending Machine
Book Review: Reborn as a Vending Machine

"There is some surprising complexity in this isekai." That was the line my wife blurted after she asked me was it good. It's honestly a fun romp I would recommend to anyone as being both silly and wholesome. It maintains a unique flavour while "conforming" to several tropes.
It has some surprising nuance in places for all the silliness of the premise and tropes of the genre.
I would strongly recommend this book to genre fans, but I would also say there is something special here.
It really was the perfect birthday book.
Book Review: Artemis by Andy Weir
Book Review: Artemis by Andy Weir

My lovely Ducky got me Artemis for Chrismas. I confess I skipped this one hearing mixed reviews, but with a lovingly gifted paperback sitting on the lounge table, it seemed time to tackle it. I quickly ate up the novel in two days, its an easy and compelling read but the entire time I was groaning and reading awkward passages aloud to her.
Overall the plot will carry you through, and the science in the book is exciting and engaging.
The characters are relatively flat single notes, and the main female character is rather cringe-worthy at times.
I thoroughly enjoyed the Martian but looking back, it seems to play to the author's strengths. It's frustrating because I found the plot and concepts so interesting in this book, but the characters and interactions were off-putting. The guy is gay, the marine is stoic, the police officer is a Mountie, the dad is Muslim, this guy is a Trekkie, this guy is rich. It lacks, and sometimes elements like the reusable condom RnD could be cut entirely leave nothing of substance out and be much less cringe-inducing.
I would say it's a fun, fast read but don't read it for the characters. Which is a shame as the story structure is character-driven.
In other news I'm trying to find the line between update and blog post. I think I need to work on some of the web tooling a bit more ;)
First

So I realised one of the reasons I don't post as often to my website is that often content is not blog worth but its more substantial than a tweet.
When Twitter started we referred to it as a Micro Blogging service. There where some other competitors, such as Tumblr but it really stole the spotlight and solidified the idea. I still need to make my Golang static website generator update AWS but its relativly low friction.
Future steps might involve intergration with ActivityPub though that can get a bit spicy with static webpages. Really it's a lightweight blog so RSS should be fine but I'm in two minds.
Anyway the good news is updates are easier